本文将介绍 GTC 2025 session 之一,由 Snowflake 公司分享的 Text-to-SQL 产品,名为 Cortex Analyst,分享标题为:Key Design Patterns to Build Trustworthy Data Agents.
先看一个官方放出来的demo:

下面将分享产品细节,可以通过以下链接找到本文的参考内容
(作者的分享文档可以评论区留下邮箱,或者公众号后台私信获取)
GTC 链接(有视频):
Snowflake 在这次 GTC25 大会上还做了提高 text-to-sql 效率的分享,链接:Trustworthy Data Agents and Making Inference Faster and Cheaper (Presented by Snowflake):https://www.nvidia.cn/on-demand/session/gtc25-s74585/
GTC session 介绍:
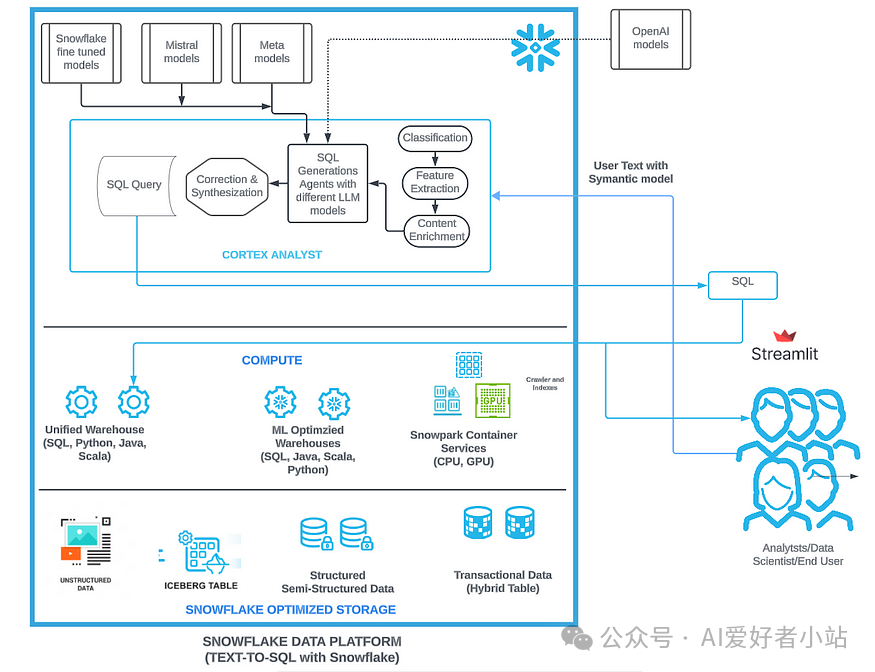
架构图:
首先分析了 text2sql 用于实际业务的难点:

1.问题复杂度(Question Complexity):现有基准测试(指的是数据集)中使用的自然语言问题通常不是非常复杂,也不太具有特定行业性或现实性。这些问题也无法涵盖在商业智能(BI)场景中经常被问到的问题类型。
2.Schema 复杂度(Schema Complexity):这些基准测试中的数据库并不总是能体现出在商业智能任务中常见的那种复杂、混乱且往往不清晰的模式。此外,在事务性数据(如销售数据或用户网络活动数据)中常见的时间序列表,在现有基准测试中的占比也严重不足。
3.SQL 复杂度(SQL Complexity):这些基准测试常常缺少复杂的查询,例如包含窗口函数、公共表表达式(CTE)以及复杂聚合操作的查询,而这些对于产业界应用中的商业智能任务来说至关重要。
4.在语义背景下衡量 SQL(SQL Matching Businesses Context):传统的基准测试没有考虑到使 SQL 查询与特定业务定义和指标保持一致的重要性。例如,不同组织对 “日活跃用户” 等关键指标的定义可能差异很大,这会影响到 SQL 查询在现实应用中的准确性。
鉴于以上的难点,用下面的工作流来提升准确度:
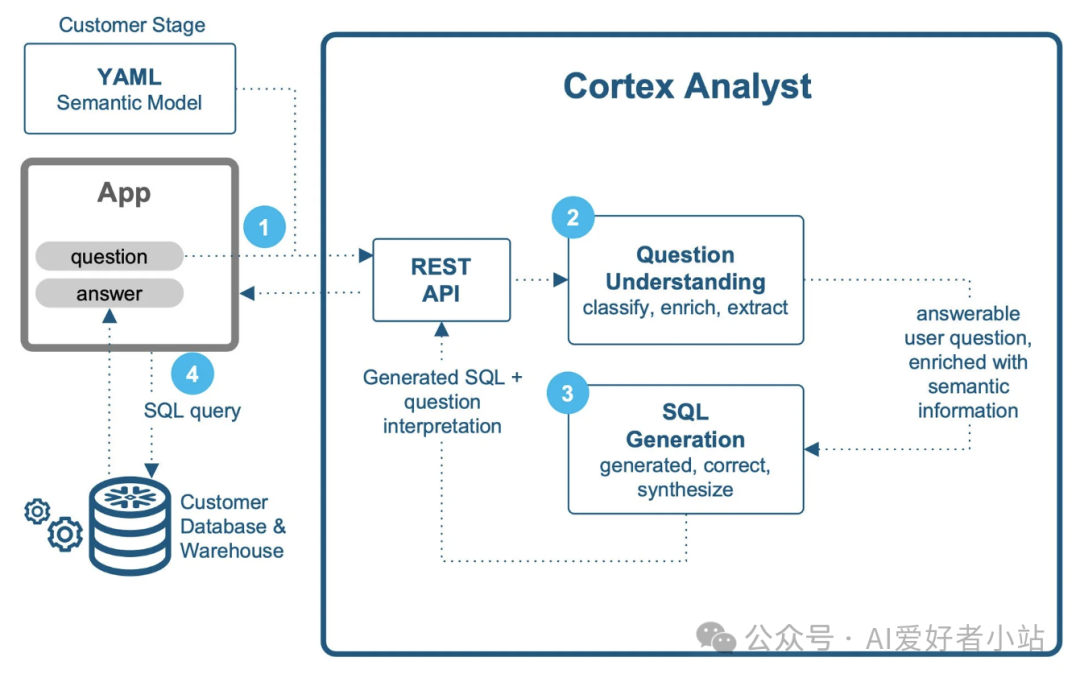
涉及多个大语言模型(LLM)智能体之间的交互,并且在每个步骤都设置了防护措施,以防止出现幻觉现象。
①面向终端用户的客户端应用程序会发送一个请求,该请求包含用户的问题以及相关的语义模型 YAML 文件,并将其发送至 Cortex Analyst 的 REST API。
②问题理解与扩充。针对上面的用户问题复杂难点,对用户问题的意图进行分析,以确定该问题是否能够得到解答。
如果问题模棱两可且无法有把握地回答,系统会返回一系列类似且能够有把握回答的问题。避免因为问题不清晰返回错误的答案。
如果该问题被归类为可回答的问题,它会利用所提供的 YAML 文件中的语义信息进行扩充。该文件包含诸如度量值和维度列的名称、默认聚合方式、同义词、描述、样本值等信息。
③SQL 生成与错误纠正。经过扩充的上下文信息会被传递给多个 SQL 生成智能体,每个智能体都使用不同的大语言模型。不同的大语言模型擅长不同的任务(有些在处理与时间相关的概念方面表现更好,而另一些则能更有效地处理多层次聚合操作)。使用多个大语言模型可以提高查询生成的准确性和稳健性。接下来,一个错误纠正智能体将使用 Snowflake 的核心服务(如 SQL 编译器)检查生成的 SQL 是否存在语法和语义错误。如果发现错误,该智能体将运行一个纠正循环来修复这些错误。此模块还会处理幻觉现象,纠正模型可能会虚构语义数据模型之外的实体或使用不存在的 SQL 函数的情况。
④最后一步,所有生成的 SQL 查询都会被转发给一个合成智能体。合成智能体利用之前各个智能体所做的工作,生成最能准确回答当前问题的最终 SQL 查询。该 SQL 查询以及对用户问题的解释都会包含在 API 回复中。返回的 SQL 查询可以在客户端应用程序的后台执行,最终结果将呈现给用户。
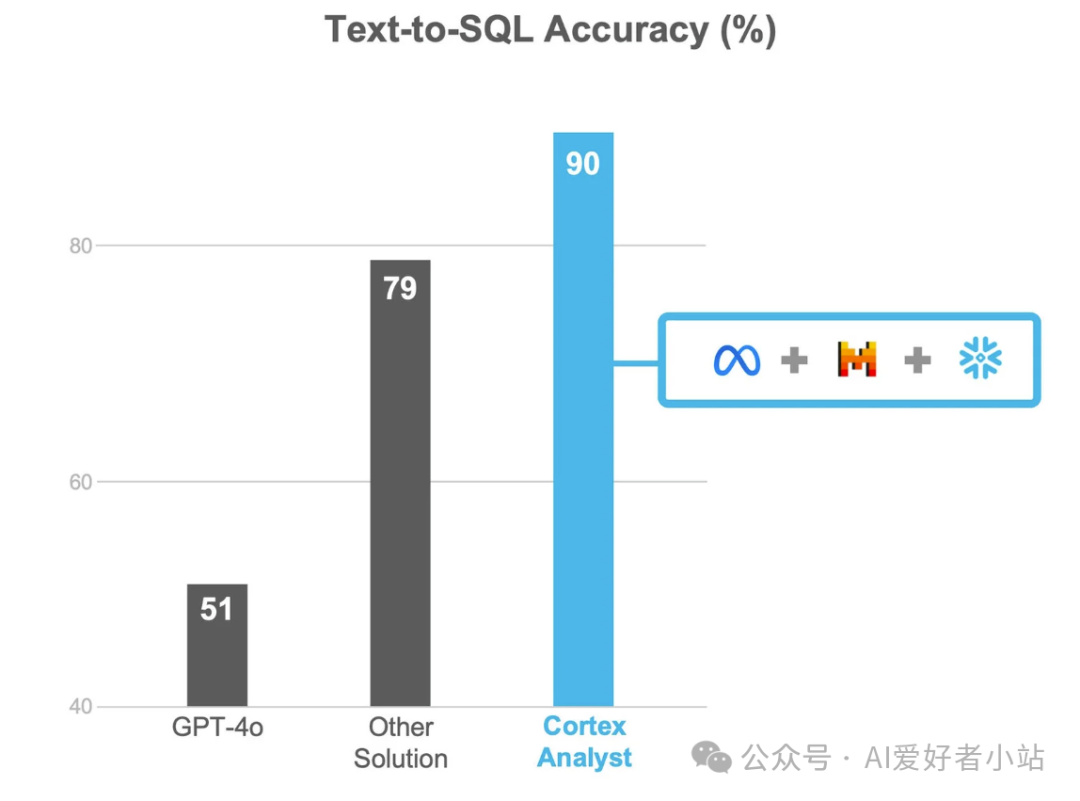
在实际业务中达到了 90% 的准确度: