
这是 Text2SQL 系列第四篇,之前分别写了数据集、当下 SOTA 的 LLM-based 的实现方式及耶鲁大学 2024 年数据集 Spider 2,排行榜 TOP1 的实现、怎么选择适合自己的**开源项目
写在前面
建议读者耐心看完,这样对本文的背景会有更深刻的了解。
假设我们有了一个系统,系统在不停地迭代,如何说服自己和审稿人系统越来越好(发论文必备要素),如何向客户证明系统的有效性和可靠性。这时候就需要有量化的评估指标。
举个例子:爆火的 DeepSeek-R1,成本是 OpenAI o1 的 1/10,怎么说明你的效果差不多,甚至更好。从中(DeepSeek-R1 发布,性能对标 OpenAI o1 正式版)可以看到,有 2 个要素,数据集和评估指标,系列文章的第一篇介绍过业界公开的数据集,后面会专门写一篇如何构建自己业务的数据集;本篇内容着重介绍评估指标部分。
另外,以上所说的都是在已经知道用户提问对应的正确 SQL 语句(Gold SQL)的前提下进行评估,在实际产业应用中,必不可少的是在线实时评估系统,这时你没法预测用户会提出什么问题,更没法预测 Gold SQL,但是需要及时感知系统生成的 SQL 是否正确,来调整系统给用户更好的体验。这是另一个话题,预计会在后面详细写一篇,有兴趣的小伙伴欢迎留言讨论,关注本公众号“AI爱好者小站“。
未完待续,下期预告商业落地前瞻或者在线实时评估系统,更多更新内容请关注本公众号!
评价指标设计有一个潜规则:指标数量不宜太多,不然会失掉重心(不超过 5 个)。特殊情况下有多个细分指标,需要合并为一个指标,便于比较。
本文将总结介绍 5 种标准评估指标和一些评估指标的探索。
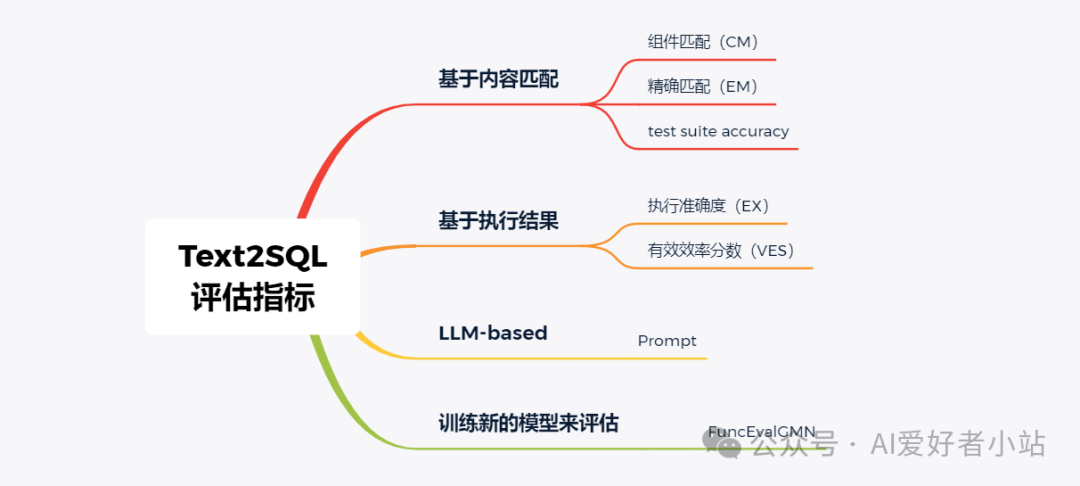
5种标准评估指标
🎯先总结一下,有个印象
CM、EM、EX 都是在 2018 年 EMNLP 会议上,由耶鲁大学和 Spider 数据集一起提出的,已经成为事实上的标准评估指标;
test suite accuracy 在 2020 年 EMNLP 会议上由耶鲁大学和伯克利大学提出,论文名:Semantic Evaluation for Text-to-SQL with Distilled Test Suites
VES 是在 2023 年 由香港大学和阿里达摩院在 NeurIPS 会议上和 Bird 数据集一起提出的,目的是在 EX 的基础上,测量查询的效率,可以同时评估效率和准确性。
可以看出以上 5 个指标的权威性,遇到 text2sql 相关的论文、产品、文章,先盯着这几个指标看准没错。关于这些指标的开源代码,均列在下文的详细介绍里面,请注意查看。
下文的公式和定义原文,均可在下面的论文里找到:
Spider 2018:https://aclanthology.org/D18-1425/
Semantic Evaluation for Text-to-SQL with Distilled Test Suites:https://arxiv.org/pdf/2010.02840
Bird 2023:https://arxiv.org/pdf/2305.03111
🎯基于内容匹配的指标:CM、EM、test suite accuracy
这里把 CM 和 EM 放到一类,因为都是基于对 SQL 语句和结构的分析,
详情如下:
组件匹配(**Component Matching, CM)**
也叫 partial_match,评估脚本请查看开源代码:
CM:https://github.com/taoyds/spider/blob/master/evaluation.py
为了了解模型在不同 SQL 组件上的性能,进行每个部分评估。通过使用 F1 分数测量预测 SQL 组件(SELECT、WHERE、GROUP BY、ORDER BY 和 KEYWORDS)与真实 SQL 组件(GROUP BY、ORDER BY 和 KEYWORDS)之间的精确匹配,评估文本到 SQL 系统的性能。每个组件被分解为若干子组件集,并在考虑无顺序限制的 SQL 组件的情况下,比较是否完全匹配。
精确匹配(Exact Matching, EM)
也叫 Exact Set Match without Values,评估脚本请查看开源代码:
EM:https://github.com/taoyds/spider/blob/master/evaluation.py
首先按照 CM 描述的对 SQL 子句进行评估。只有当所有组件都正确时,预测的查询才是正确的。每个子句中是进行集合比较,所以这种精确匹配度量可以处理 “顺序问题”。
test suite accuracy
评估脚本请查看开源代码:

针对 EM 的 False Negative 问题(左下角)和 EX 的 False Positive 问题(右上角),通过近邻查询衡量测试套件代码覆盖率。将目标设定为找到能区分所有近邻查询的小型测试套件。近邻查询通过修改黄金查询的整数、字符串、比较运算符等方面生成,具有语义不同且能检验测试套件覆盖度的特点。
这里不展开讲技术细节,有兴趣的小伙伴可以通过链接(https://arxiv.org/abs/2010.02840)下载全文研究。可以简单理解为对 EM 指标的优化。
🎯基于执行结果的指标:EX、VES
这里把 EX 和 VES 放到一类,因为都是基于执行结果。这类指标有一个比较麻烦的事情,就是需要有实际的数据库和数据来执行语句,详情如下:
组件匹配(**Execution Accuracy, EX)**
评估脚本请查看开源代码:
EX:https://github.com/AlibabaResearch/DAMO-ConvAI/blob/main/bird/llm/src/evaluation.py
通过在相应数据库中执行预测的 SQL 查询,并将执行结果与基本真实查询所获结果进行比较,来衡量该查询的正确性。公式如下:
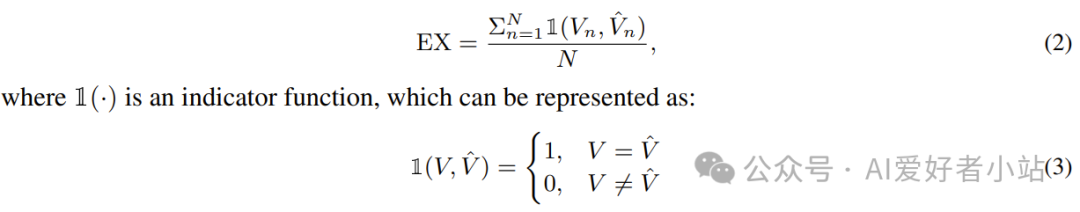
有效效率分数(**Valid Efficiency Score, VES)**
评估脚本请查看开源代码:
VES:https://github.com/AlibabaResearch/DAMO-ConvAI/blob/main/bird/llm/src/evaluation_ves.py
执行结果与真实结果完全一致,同时加上对执行效率(运行时间)的指标
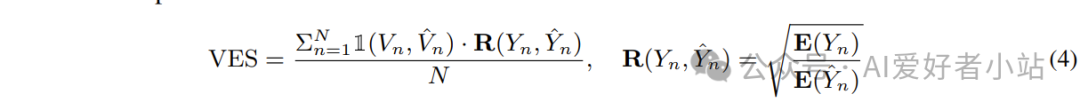
相对效率函数 R (・) 用于衡量预测 SQL 与基准 SQL 的执行效率比值,该指标通过引入机器状态不确定性模型来消除硬件环境波动的影响;
绝对效率函数 E (・) 则基于特定环境下的实测数据,直接反映单条 SQL 的执行效能;
特别地,我们引入平方根变换机制,通过数学方法抑制因随机因素导致的异常快 / 慢执行案例对整体评估的干扰;
本系统当前主要以运行时间作为核心效率指标,该指标可扩展支持吞吐量、内存占用等单项或复合评估维度。
探索性评估指标
🎯LLM-based 打分机制评估指标
这种指标的思路是借助提示词工程(Prompt Engineering)、检索增强生成(Retrieval-Augmented Generation, RAG)等技术,用大模型的推理分析能力,来打分,优点是适用性强而且可以不断优化,缺点是不稳定,且公共认可度不高,放在论文里不太合适。
Prompt 模板示意如下:

🎯训练新的模型来评估
这个指标是最近才出来的,由字节团队提出,也作为 session 话题出现在 GTC 2025 的讨论中,前两天我的一篇推文有详情:GTC25 | 字节参会文章 Text2SQL 新评估指标-FuncEvalGMN
总结来说,也是基于组件的方式,不需要执行结果和大量的数据库准备。思路基于图和自注意机制训练了新的模型用于评估,这个思路可以持续关注,有可能是未来的方向,缺点是尚未得到行业普遍认可和大规模的应用。
找一些排行榜和论文看看
找一些排行榜和论文看看,他们都用哪些指标
Bird 使用的是 EX 和 VES 指标:https://bird-bench.github.io/
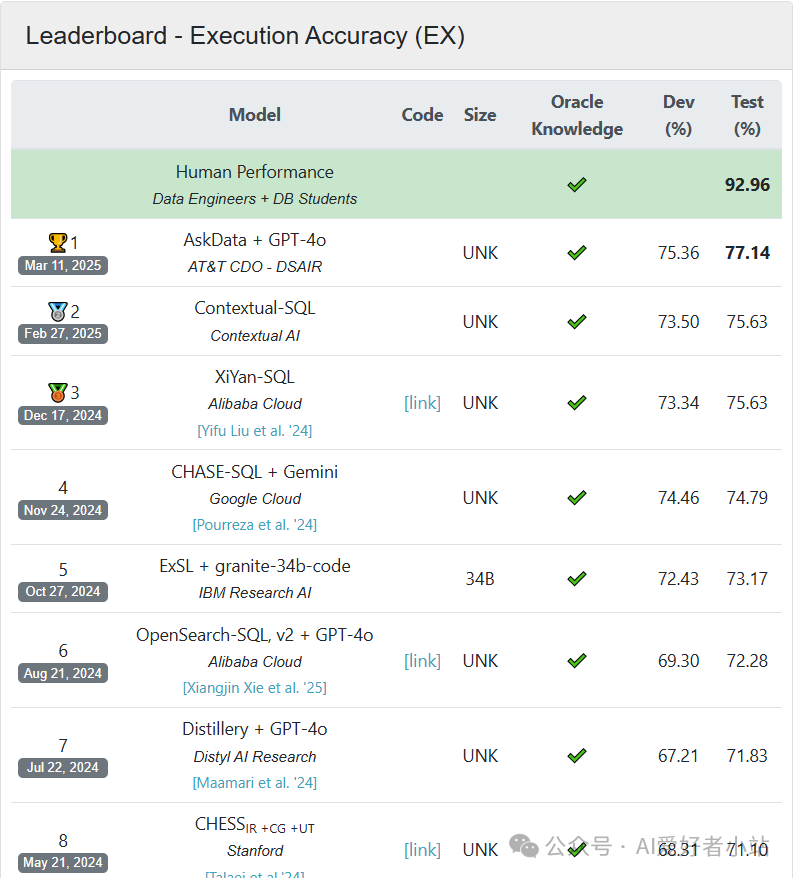
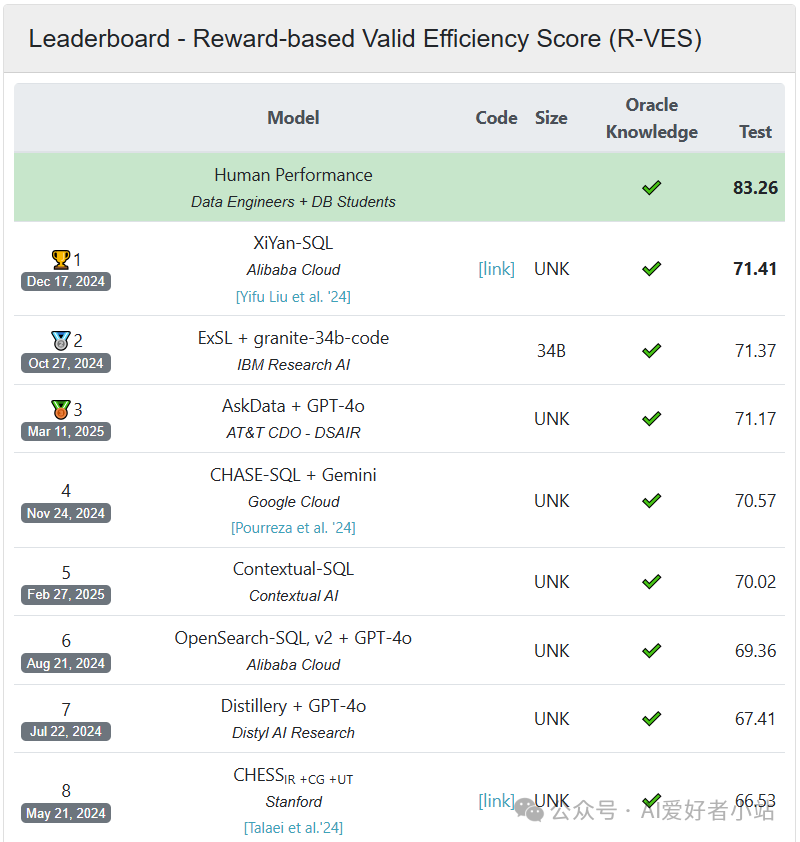
Spider 使用 EX 和 EM:https://yale-lily.github.io/spider
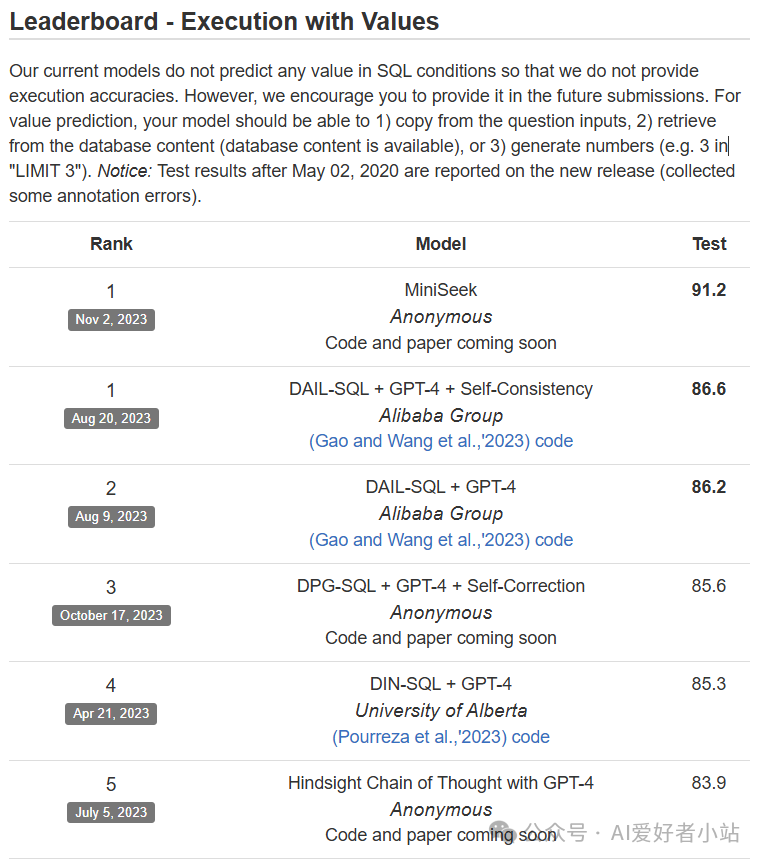
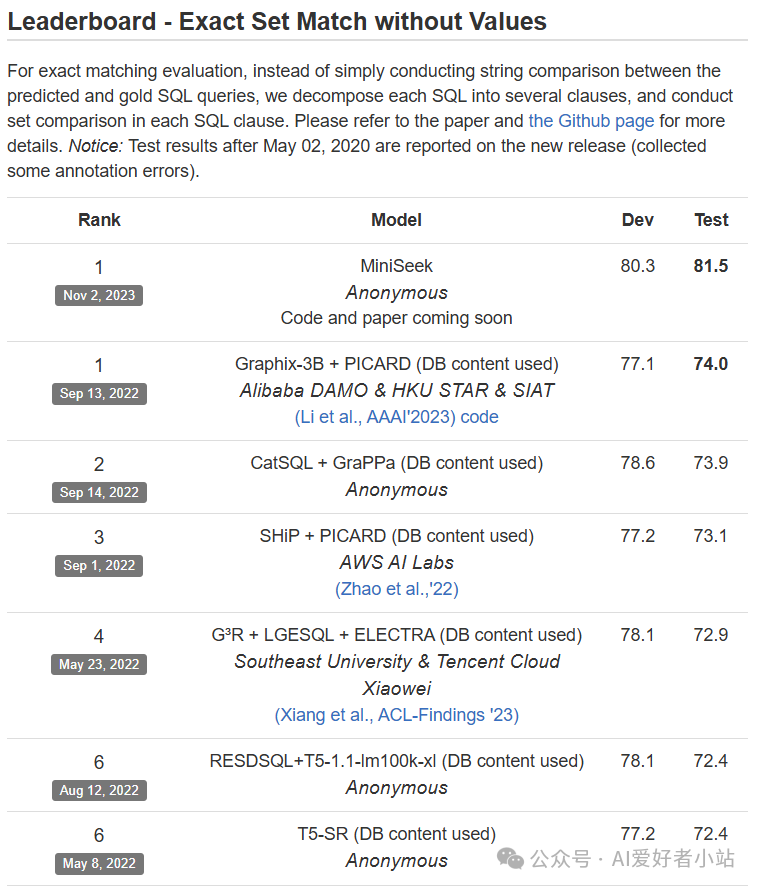
2023 TPAMI 论文:A Heterogeneous Graph to Abstract Syntax Tree Framework for Text-to-SQL
链接:https://rhythmcao.github.io/publication/2023-hg2ast/2023-hg2ast.pdf
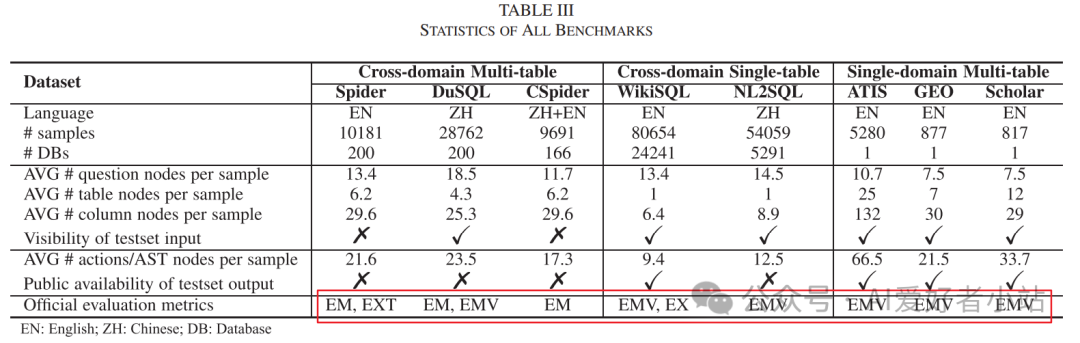
用了如下指标:

结论
EX 用得最多,论文和排行榜里最经常见到;EM 和 test suite accuracy 次之,CM 和 VES 在特殊场景下使用。其他探索性指标,暂时没见到在排行榜或者其他论文里使用。