
写在前面
如何向平台化迈进——引入数据湖和 GraphQL
本文一如既往,坚持问题导向,先介绍 我们面临的问题 ⇨ AWS解决方案 ⇨ 数据湖和 GraphQL ⇨ 未来的挑战 ⇨ 总结,请跳到相关章节对应阅读。
要解决的问题
让我们直入主题,看看面临的挑战和需要解决的问题。
实际应用中,Text-to-SQL 作为核心引擎,接入到各种产品中,用户端可能是商业智能(Business Intelligence, BI)界面,数据端是各种各样的产品数据库。尤其是现在 AI 快速发展,多模态大模型使得各种多模态数据也能被模型理解,极大丰富了数据来源,比如:流媒体(摄像头监控)、视频、图片、雷达数据、PDF文件、Json文件、CSV文件等。多样是机遇,也是挑战。
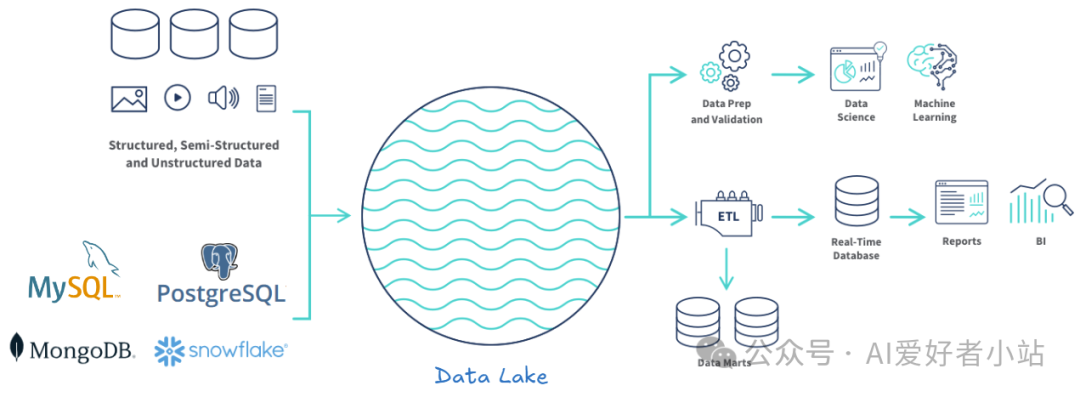
如上图,左边部分,多样性体现在:
- 数据类型多样:
数据类型多样带来的是存储方式的多样,检索方式的多样,如果需要调用图片内容、摄像头监控的内容、车载雷达的数据等,是需要预先加入元数据(meta data),然后接入平台。接入哪个平台,这个平台可能长的样子和用到的技术,这就是本文重点讨论的内容。
结构化数据(Structured Data):有明确的结构和格式,能够用固定的模式或表格来表示的数据。它通常以行和列的形式存储在关系型数据库中。比如:各类信息表、服务器日志(记录了用户的访问时间、访问页面、IP 地址等信息,这些信息按照一定的格式进行记录)等。
半结构化数据(Semi-Structured Data):介于结构化和非结构化之间的数据形式,它具有一定的结构,但不像结构化数据那样严格遵循固定的表格模式。比如:HTML 网页、Json文件等。
非结构化数据(Unstructured Data):没有预定义的结构或格式,数据内容自由、灵活,难以用传统的表格形式进行表示和组织的数据。比如:文本、图像、音频、视频等。它们的价值往往隐藏在数据的整体内容中,需要通过复杂的算法和技术进行分析和挖掘。
- 数据库类型多样:
数据库类型多样带来的问题是:不同的数据库有语法差异(SQL dialect),当数据库变化时需要重新训练、微调或者更换调试不同的提示词模板。原来的方案终究兼容性不够。除了兼容性的问题,还有一个更不好解决的问题是跨数据库的信息聚合,比如:我需要做不同产品的数据对比,但是这些产品的数据很可能一个放在 Oracle,一个放在 MongoDB,作为一个上层的产品,如果强制要求产品迁移数据库,无疑是不现实的。
下面简单总结了可能会接入的数据库类型:
关系型数据库:MySQL、PostgreSQL、Oracle、SQL Server ...
非关系型数据库:MongoDB、Redis、Cassandra、HBase ...
分布式数据库:Hadoop HDFS、Cassandra、Apache HBase、ClickHouse、Amazon S3 ...
以上的两点特性,就要求系统具有强大的兼容性以及平台化的特点
业界有哪些解决方案?
亚马逊 AWS 的解决方案
先看看亚马逊 AWS 的架构方案,然后再详细分析:
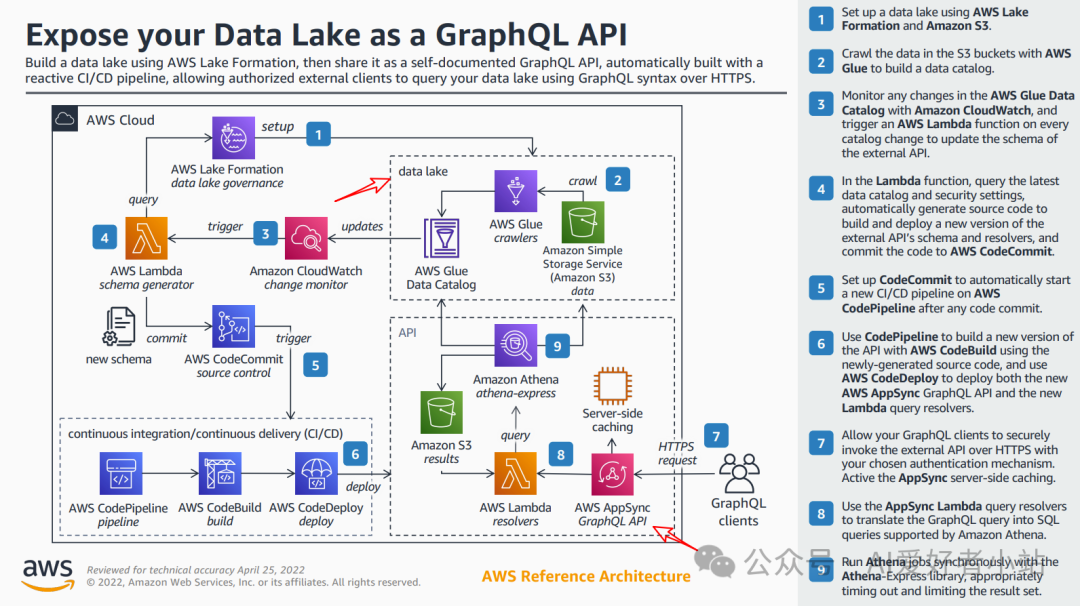
上图是 2022 年 AWS 介绍自家的 AWS Lake 数据湖和 GraphQL API 调用的架构图。主要包含以下几个部分:
①数据湖搭建:利用 AWS Lake Formation 和 Amazon S3 构建数据湖,通过 AWS Glue 爬取 S3 数据构建数据目录,实现数据湖治理和数据管理。
②API 暴露与更新:将数据湖以 GraphQL API 形式对外提供服务。借助 Amazon CloudWatch 监测 AWS Glue 数据目录的变化,一旦有变化就触发 AWS Lambda 函数。Lambda 函数会根据最新数据目录和安全设置自动生成构建和部署 API 架构及解析器的源代码,并提交到 AWS CodeCommit。
③CI/CD 流程设置:配置 AWS CodeCommit,使其在代码提交后自动触发 AWS CodePipeline 新的 CI/CD 流程。CodePipeline 联合 AWS CodeBuild 和 AWS CodeDeploy,使用新生成的源代码构建并部署新的 AWS AppSync GraphQL API 和 Lambda 查询解析器。
④API 调用与解析:GraphQL 客户端通过 HTTPS 和选定的认证机制安全调用 API,并启用 AppSync 服务器端缓存提升性能。AppSync Lambda 查询解析器将 GraphQL 查询转换为 Amazon Athena 支持的 SQL 查询,借助 Athena-Express 库同步运行 Athena 作业,同时合理设置超时和限制结果集。
这一整套复杂的方案,涉及数据抓取、数据同步、数据治理、数据暴露,CI/CD等。我们聚焦在其中的 2 个非常重要的概念:数据湖 和 GraphQL。毫不夸张地说,这2个概念里的任何一个,都要一本甚至几本书才能讲明白。
数据湖和 GraphQL
下面我们分析下:
- 引入数据湖(Data Lake)
数据湖(Data Lake)是一个不断发展的概念,在2010年10月纽约的 Hadoop World 大会上提出,上承数据仓库(Data Warehouse),下启数据湖仓(Data Lakehouse),目的是为了更好地进行数据管理,AI 时代,数据的重要性越发凸显,数据管理技术可能成为未来的基础设施。
我们可以从 databricks 公司的架构图获得直观印象,链接:https://www.databricks.com/glossary/data-lakehouse
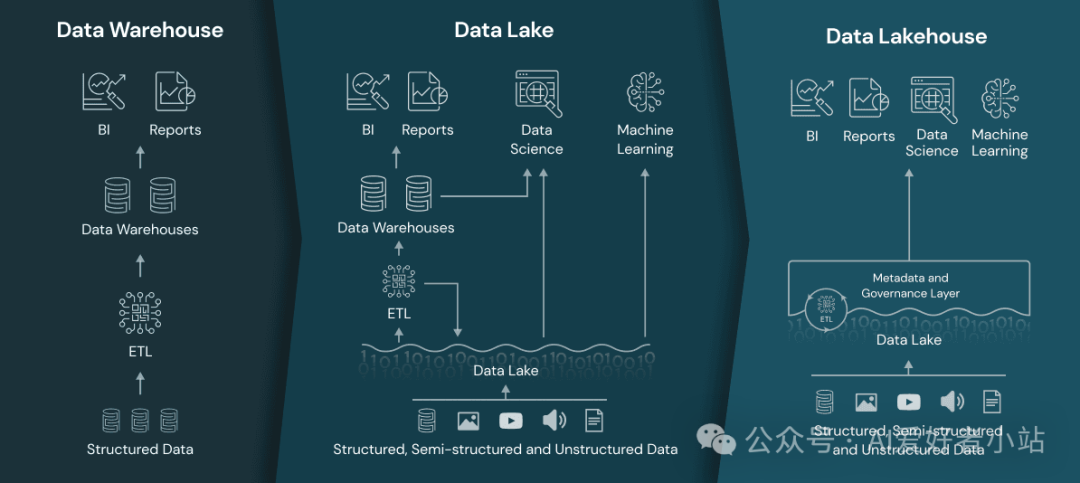
数据湖一个显著优点在于其对象存储机制。它通过元数据标签和唯一标识符存储数据,让跨产品检索变得可能;同时原始数据与结构化数据以及提炼原始数据过程中生成的中间数据表一同被抓取和存储,避免了源头上的信息丢失。数据湖能够处理所有数据类型,包括图像、视频、音频和文档等非结构化和半结构化数据。这些数据对于当今的机器学习和高级分析应用场景至关重要。
- 引入 GraphQL
如何提供数据湖或者数据湖仓的信息给外部,GraphQL 是其中比较好的方案。GraphQL 是 Facebook 在 2012 年创立的一门查询语言,2015年开源。它没有和任何特定数据库或者存储引擎绑定,而是依靠现有的代码和数据支撑,基于数据定义来查询;它还可以通过一个单一入口端点得到所有的数据,非常适合数据聚合和分析;另外,它还提供自定义聚合dimension、measurement 和 metric,供外部直接调用,省去了原有 SQL 的联表复杂聚合等操作。
这个中文网站提供了很好的资料,链接:https://graphql.cn/

来看一个请求和返回的例子:
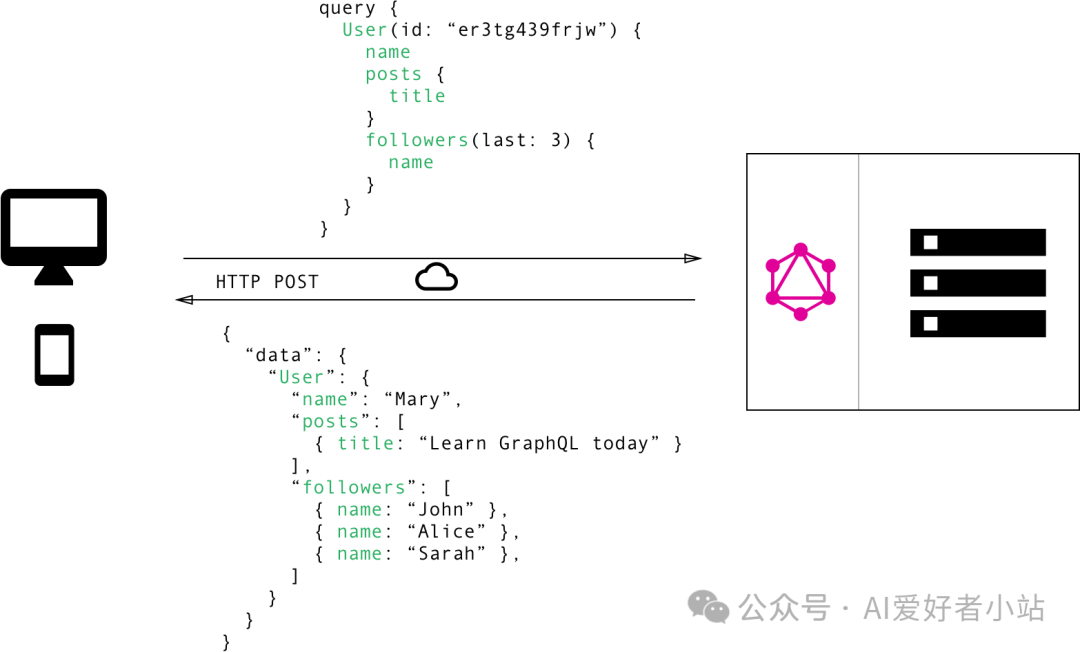
上图获取筛选条件为特定 id 的用户,返回用户名,推文的标题和推文最近的3个点赞的用户,可以看到有高级语言的感觉,query 语句比纯 SQL 要简单,更语义化很多。
未来的挑战
同时也引入了新的问题和挑战:
- 源数据库和数据湖之间数据的一致性和数据同步问题
- Text-to-SQL 要转变为 Text-to-GraphQL (下期内容重点讨论,请关注公众号获取最新内容。)
- 实时性要求更强,需要流处理能力 ⇨ 批流一体
总结
数据湖、湖仓一体、GraphQL ... 大家看完可能也有一种感觉:越来越脱离了单纯的 text2sql。对的,这就是产业界应用的特点,实际应用会遇到各种问题,涉及到各个领域,需要综合各个领域的技术形成解决方案。这也正是其中的魅力,攻克一个个难关之后,打通任督二脉,实实在在提供价值,造福产业界。