
这是 Text2SQL 系列第七篇,主要讨论 Text2GraphQL(Text-to-GQL),这个主题是平台化和数据治理的延续,致力于减少非标,用一套统一标准系统兼容底层不同数据的产品,不用换了产品和数据库便需要重新微调、换提示词。
之前系列分享了Text-to-SQL数据集、耶鲁大学 Spider 2 TOP1 实现、选择适合的开源项目、准确率和效率的评估指标、成熟的 AI 系统——在线实时评估设计、数据治理与平台化——引入 GraphQL和数据湖。感兴趣的读者可以从文末合集跳转或者去公众号首页查找阅读。
写在前面
P.S: 澄清一下,这里的 GraphQL 不同于 图数据库的 GraphQL,两者单词一样,容易混淆。本文讨论的 GraphQL 是 Facebook 在2015年开源的用于 API 的查询语言,资料链接:https://graphql.cn/learn/
上一篇文章提到 GraphQL 和 数据湖,这两者的引入有一种工程学上的设计哲学:高内聚、低耦合。GraphQL 语法一致,避免了不同数据库的语法(SQL Dialect)差异,每一种 SQL 都需要微调或者不同的提示词工程;它没有和任何特定数据库或者存储引擎绑定,而是依靠现有的代码和数据支撑,基于数据定义来查询;它还可以通过一个单一入口端点得到所有的数据,非常适合数据聚合和分析。回味第六篇文章第 3 章节(数据湖和 GraphQL 洞察):Text2SQL / NL2SQL(六)数据治理与平台化:数据湖和 GraphQL
这些优美的特质,让我们可以聚焦于一种方案,形成标准产品,而不是给每种产品做一个定制,往成熟的商业化迈进一大步。
- 有多少人工就有多少智能。不管是数据集准备、Semantic Layer 设置、提示词模板调试,都需要大量高质量的人工工作,不然只能是Garbage in, Garbage out。
- 没有适用于全部任务的提示词和工作流,必须在准确性和细分程度做取舍。尤其在 Text-to-SQL 领域,任何一个条件的变化,都会影响到最终的结果。
- 一个好的 AI 产品的关键在于:
- 明确能力边界
- 数据分析深入
- 业务逻辑理解深入
- 架构设计合理,尽量让 LLM 少做不确定的事,不擅长的活
- LLM 现有能力扩展,可以增加 tools 调用、MCP
看看架构
跟 Text2SQL 类似,可以理解为另一种 SQL,不同的是有业务预定义的语义层(Semantic Layer),调用的数据来源为数据湖,或数据湖仓。
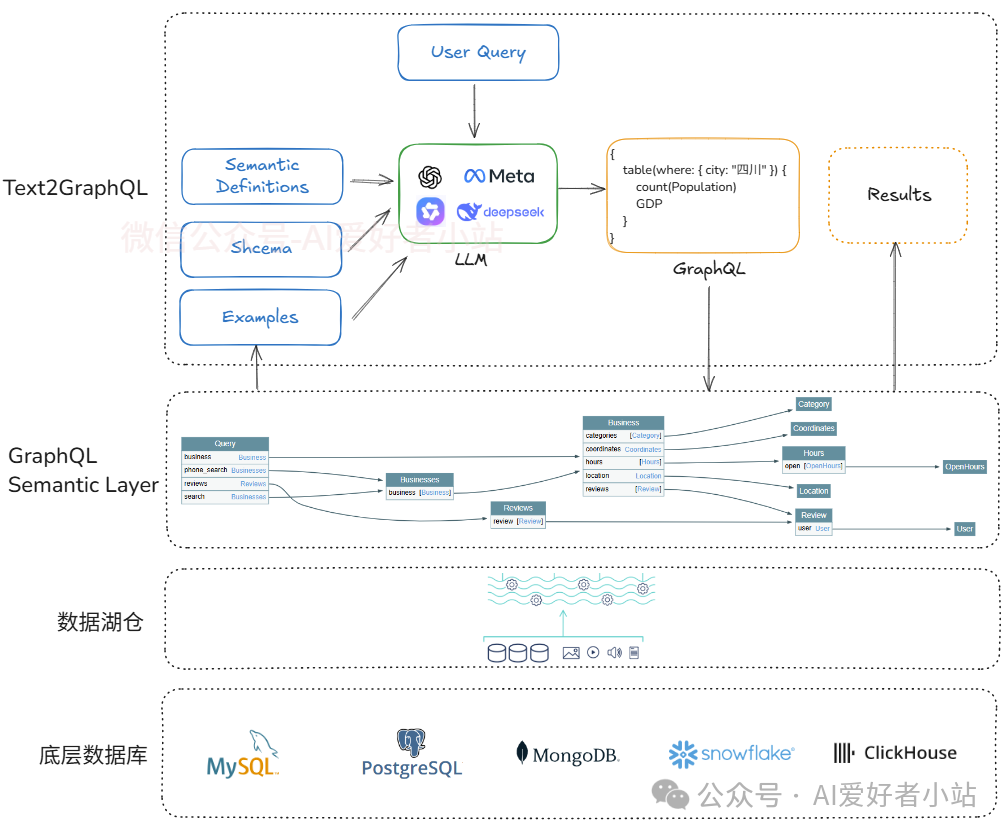
最底层的产品数据库,可能会有多种来源,关系型数据库(MySQL、PostgreSQL)、非关系型数据库(MongoDB、Redis)、Cassandra、HBase ...分布式数据库(Hadoop HDFS)等;
这些会接入到数据湖仓统一管理,作为基础设施完善 meta 信息(写好描述,打好标签);
然后通过 GraphQL 暴露 API 接口,统一调用,这一层还有重要的功能便是 schema 梳理、GraphQL dimension / measurement / metric 配置,是准确率的关键,需要与业务对齐,一半的工作量便在这里;
最上层便是使用 Agentic Workflow 完成 GraphQL 的生成,校验,执行,获得所需答案。图中举了个例子,
Query:获取四川的人口和GDP
GraphQL:
{
table(where: { city: "四川" }) {
count(Population)
GDP
}
}乍一看没什么问题,但是,实际上如果用户问10次,很可能会出现几个结果,因为人口数和 GDP 是动态变化的,用户的问题里没有明确这个信息,不加明确的话,LLM 有可能返回2025年的,2024年的,近5年的。有以下解决办法:多轮对话引导用户明确意图(未来进化方向)、或者在 Semantic Layer 指定类似默认的限定条件并呈现给用户。
来看一点点细节
这一章是 Text2GraphQL 的 Agentic Workflow 流程,模块设计引入了很多 AI Agent 处理任务,同时应用了 RAG 技术。
ps. 部分参考了 snowflake 的设计
图里用 GQL 代指 GraphQL
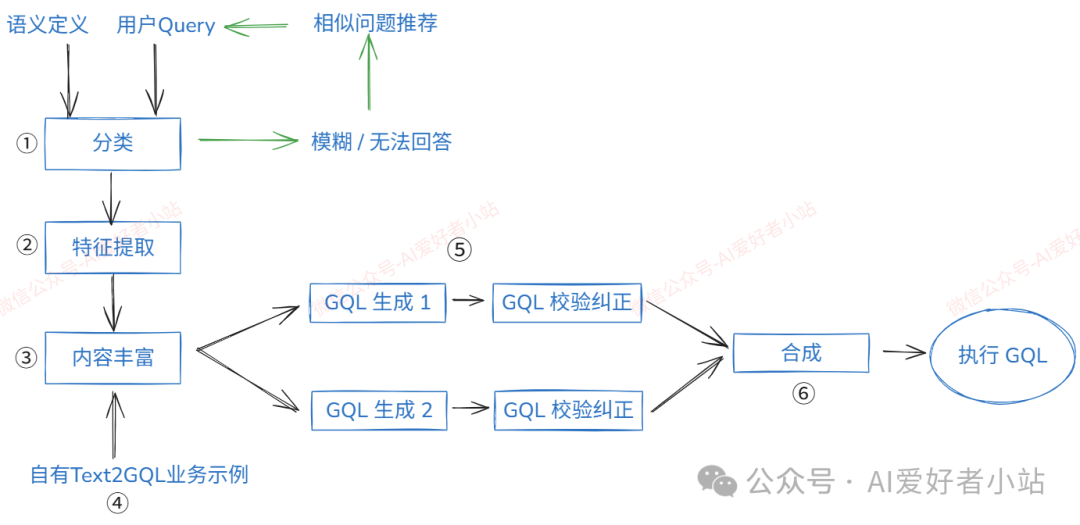
下面用一点点细节,分别说明每一步的作用:
①分类 Agent
用户的问题有时会很模糊,不能可靠地回答。例如,“去年最好的产品是什么?”,最好这个概念本身就比较模糊。为了避免幻觉并赢得用户信任,预先拒绝此类问题而不是用潜在的误导性答案来回答。(可以引入多轮对话来引导用户明确需求,这是另一个挑战了)
分类 Agent 将传入的 用户Query 分类为模棱两可、非数据问题、非SQL数据问题 等,它只回答那些没有模棱两可且可以使用SQL回答的问题。其他类别的问题被拒绝,并提供稳定回答的相似问题推荐。
②特征提取 Agent
分类后,特征提取 Agent 分析问题,提取特征。例如,时间序列问题、涉及排序问题、涉及多产品聚合问题... 这些特征提供给接下来工作流使用,可能会调用不同的提示词,以提高生成的准确性。\没有适用于全部任务的提示词和工作流,必须在准确性和细分程度做取舍**,或者增加工作流,做细粒度。因为在 Text-to-SQL 领域,任何一个条件的变化,会影响到最终的结果。业内也经常调侃,有多少人工就有多少智能。**
③内容丰富 Agent
\这种扩充对于回答业务用户的问题至关重要,这些问题有时缺乏必要的上下文,来源可以是自有业务的 Text-to-GraphQL 数据集。\这个 Agent 多用 RAG 混合检索获取得到相关内容。**
④自有业务 Text-to-GraphQL
自有业务的 Text-to-GraphQL 数据集,作为上下文传入 LLM,以提高生成 GraphQL 的准确率,减少幻觉。这里以 Hugging Face 上一个数据库为例:https://huggingface.co/datasets/smjain/api_graphql
主要包含以下部分:1.用户提问Query;2.GraphQL schema 上下文;3.用到的数据库表和字段;4.Gold GraphQL
下面是一个示例:下划线标注了主要部分

⑤GraphQL 生成 Agents
将丰富的上下文传递给 GraphQL 生成的多个 Agents,他们可能用了不同的 LLM,可能关注于不同的方面。实际上,这些 Agents 设计擅长回答不同类型的问题。例如,有些能更好地处理与时间相关的概念,而另一些在多产品聚合中更有效。因此,使用多个LLM可以使整个查询生成过程更加健壮和准确。使用从问题中提取的特征来生成为回答特定问题而量身定制的提示词,这些提示词包含更小、更具体的指令集。
⑥合成 Agent
一旦检查并更正了所有生成的 GraphQL,它们将被转发到合成 Agent,它类似于专家数据分析师,接收多个候选语句和附加上下文,例如相关文字和验证查询,同时赋予第②步的特征更多的权重,综合得出最终的 Graph QL。
Semantic Model Layer
介绍下语义模型层的概念
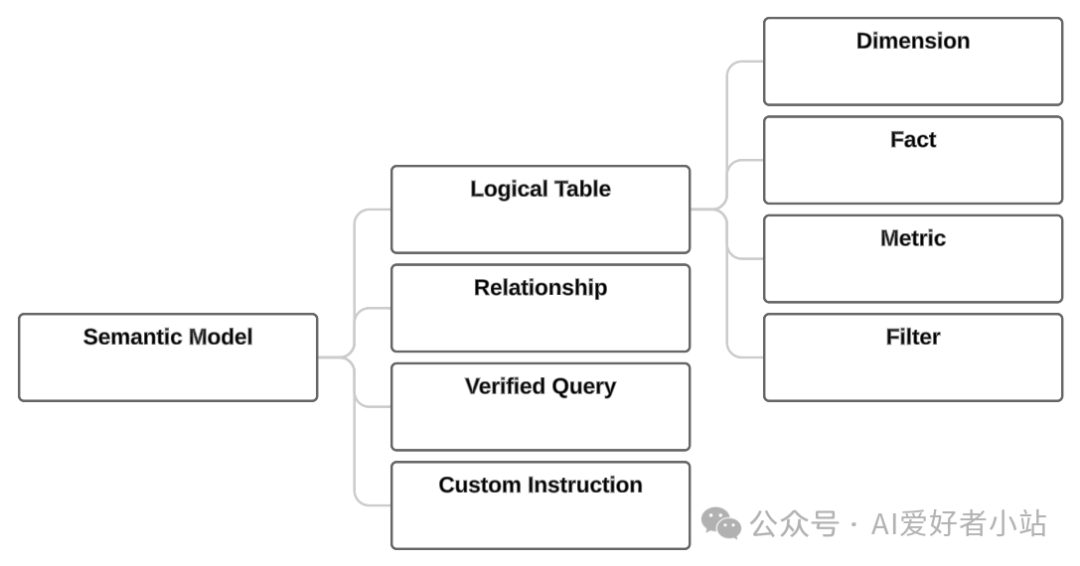
逻辑表(Logical Table)是语义模型的基本概念。它表示物理数据库表或视图。它通常对应于业务实体(如客户、订单或供应商)。逻辑表中的每一行通常代表实体的唯一实例,如客户ID。
逻辑表包含以下类型的列:
- Dimension 维度(谁、什么、在哪里等定性属性)
- Fact 事实(有关业务事件的定量数据)
- Metric 指标(用于量化和评估数据的定量指标,如:数量、频率)
- Filter 筛选
总结
得益于 LLM、RAG、AI Agent 等技术的发展,工程上优化工作流,让 Text2GQL 达到 90% 以上准确率成为可能,让产业界应用看到了曙光。本文分享了一个整体架构和具体实现工作流,以及实际应用中的总结(心得体会 takeaway)。
以下心得与诸位分享:
有多少人工就有多少智能。不管是数据集准备、Semantic Layer 设置、提示词模板调试,都需要大量高质量的人工工作,不然只能是GIGO(garbage in, garbage out,输入的是垃圾,输出的也是垃圾)。
现在 LLM 能力让产品能很轻松做到60分,简单的提示词工程就可以达到,但是产业界没有85分甚至更高是没有实际意义的,因为不可靠,用户不信任,还需要人工大量校验。
同时,没有适用于全部任务的提示词和工作流,必须在准确性和细分程度做取舍。尤其在 Text-to-SQL 领域,任何一个条件的变化,都会影响到最终的结果。
因此,一个好的 AI 产品的关键在于:
- 明确能力边界
- 数据分布分析深入
- 业务逻辑理解深入
- 架构设计合理,尽量让LLM少做不确定的事,不擅长的活(如数学计算)
扩展 LLM 能力,可以调用 tools 或者 MCP(Model Context Protocol)