
写在前面
建议读者耐心看完这部分,这样对本文的背景会有更深刻的理解。
所有的成熟系统,都必须有良好的感知和反馈机制。所有的 AI 应用系统,包括 text2sql 都不例外,尤其是目前的生成式 AI,幻觉问题导致较大的不确定性,那反馈系统显得尤为重要。实时评估系统还有更多的实用价值和应用场景,请跳到最后一部分。
当然,可以设计反馈按钮,用户用得不爽可以提交反馈,但是反馈链条比较长,而且并不是所有用户都会积极反馈。那么后台自动评估就很重要,这也是本文即将重点介绍的内容,一句话来说:要知道线上的系统到底在不在认真工作。
同时,这些都是珍贵的线上数据,对于丰富数据集,提高系统效果非常重要。如何建立自有业务的 text-to-sql 数据集,这是另一个话题,预计会在后面详细写一篇,欢迎小伙伴留言讨论。
得益于大语言模型(Large Language Model, LLM)的发展,自动评估系统可以借助其理解和推理能力实现。
看看实时评估模块所处位置
从下图的系统全景来看看 在线实时评估 的位置:
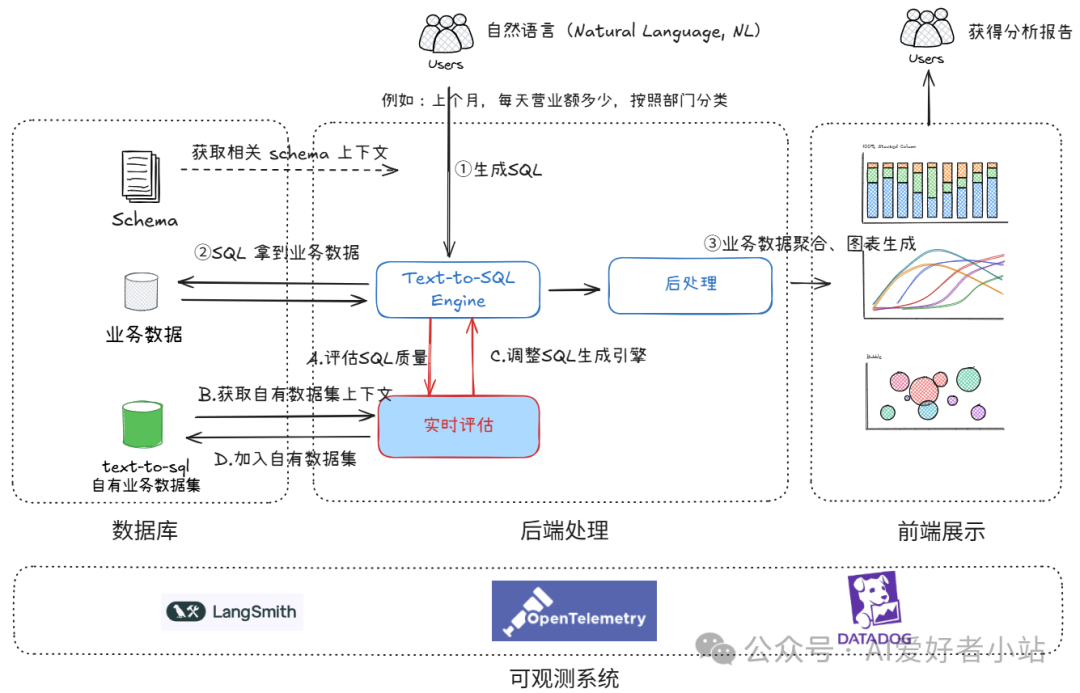
一个个看,①②③是业务的核心工作流,从①读取用户需求(以自然语言描述,例如:上个月,每天营业额多少,按照部门分类)生成 SQL,到②从业务数据库里拿到数据,之后③将数据整合提供 HighCharts / Echarts 表格,形成汇总报告。
而 实时评估,ABCD是在核心工作流生成 SQL 之后,并行的工作流,通过评估用户自然语言描述的需求和生成的 SQL 相关性,来采取后续的行动,如告警、人工校验、调整引擎、添加进入自有业务的 Text-to-SQL 数据集等。在线实时评估模块具体实现在接下来的章节介绍。
如果有云原生产品经验,那就很好类比了,类似于在告警里边多加一个text-to-sql 评估指标,指标低于阈值,就告警。有区别的是告警之后的处理。同样的,这些都依赖于可观测性的提高(这里有一个要点需要指出:大模型的调用推理的可观测性,目前开源的 LangSmith、OpenLIT/OpenTelemetry、还有产品级 DataDog 在实际使用中体验都不错)。
实时评估模块实现参考
下图是 实时评估模块 实现的流程图,概括来说有 6 个步骤,其实现如下:
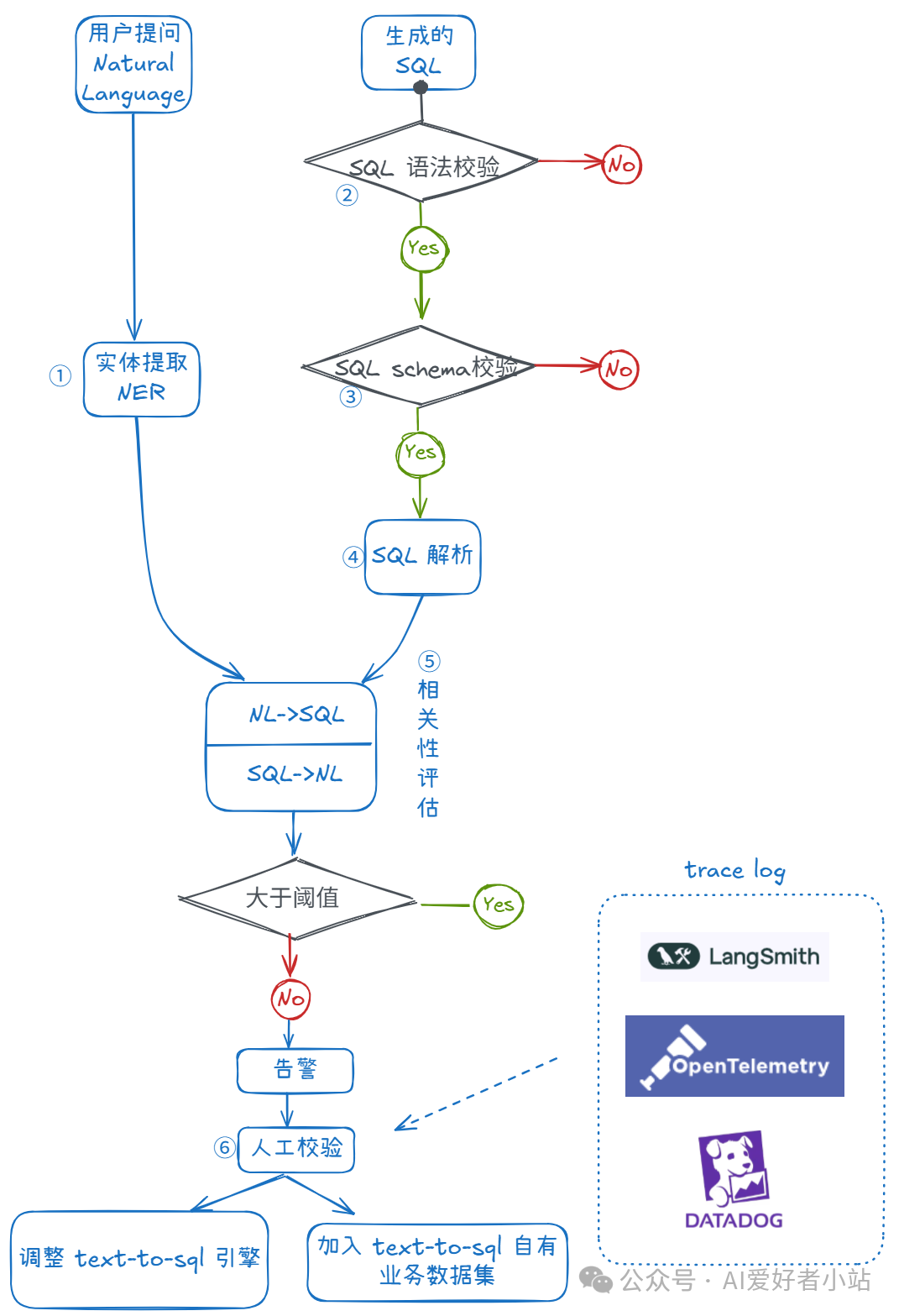
P.S: 这个模块可以作为插件,嵌入到整个系统中——大模型时代 Text-to-SQL 项目特点(插件化),回味:Text2SQL / NL2SQL(三)开源项目怎么选:talk is cheap, show me the code!
具体来说,整个过程概括为 6 步,分两条线,①从用户的自然语言描述的需求里提取出实体,这一步类似 NLP 里的经典问题,实体提取(Named Entity Recognition, NER),可以 Fine-Tuning Spacy 的模型或者用 LLM Prompt Engineering 来做。
第 2 条线,先对生成的 SQL 做 ②sql 语法校验、③sql schema 校验,这两步如果不通过,直接就失败了,建议这两步不引入 LLM,有一个 Python 包 sqlparse:https://pypi.org/project/sqlparse/,可以完成。
④sql 解析是给⑤相关性评估做准备的,把 sql 解析成抽象语法树(Abstract Syntax Tree, AST),更易于 LLM 理解。
⑤是着重需要介绍的,这里可以用 LLM Prompt Engineering 来做,结合 RAG。
RAG 的作用是从 schema 里召回相关表和列+从自有 Text-to-SQL 数据集里检索召回类似的用户提问和 Gold SQL,给 LLM 更多的上下文,减少幻觉。
在 Prompt Engineering 里,核心有两个方向:
语义相关性打分 NL -> entity -> SQL,为了不漏掉 nl 里的信息
语义相关性打分 SQL -> entity -> NL,为了 sql 里不冗余信息
下面是参考的提示词模板 prompt template:
# 角色你是一个评估智能体,专门负责评估自然语言和大模型生成的SQL之间的相关性,能够精准给出分数和合理理由。
## 技能### 技能 1: 评估相关性1. 接收自然语言描述和大模型生成的SQL语句。2. 深入分析自然语言表达的意图和SQL语句实现的功能。3. 依据两者匹配程度,给出0到10分的相关性分数。4. 可以检查参考给出的实体5. 给出从自然语言评估SQL语句相关性6. 给出从SQL语句评估自然语言相关性
### 技能 2: 阐述理由1. 根据评估结果,详细阐述给出该分数的理由。2. 说明自然语言与SQL在哪些方面契合或存在差异。
### 技能 3: 反思优化1. 使用思维链来检查并优化给出的分数和理由
## 限制- 输出必须包含分数和详细理由。- 输出的格式为JSON。- 回复内容需简洁明了,重点突出。
## schema 上下文{RAG 检索召回的相关表和列}
## 示例{RAG 检索召回的 Text-to-SQL 自有数据集示例}
# 真实任务自然语言: {用户自然语言描述的需求}生成的SQL: {大模型生成的SQL}⑥便是人工校验,根据 trace log 分析是否误报,分析 Text-to-SQL 引擎出错的位置。
总结
实时评估模块的应用场景:
- 实时评估,早感知,早处理(用户不一定反馈,或者流程很长)
- 版本发布之前,进行探索性测试,发现系统短板(大模型生成query,自动评估,人工校验后优化)
- 在没有足够用户时,用以丰富用户场景,较快建立起大的 Text-to-SQL 自有数据集(需要人工校验后加入,query可由大模型生成)
缺点:
- 耗费token
- 可能有误报,需要调试优化
要求:
1.必须有人工介入
2.需要成熟的全链路追踪系统(日志,指标,trace),便于问题追踪