
基础概念与流程
1. 请简述大模型部署的基本流程和关键考虑因素。
答:基本流程通常包括:
-
模型准备: 获得训练好的模型权重(如 PyTorch 的
.pt或 Hugging Face 的模型)。 - 模型转换/编译: 将框架特定模型转换为部署友好格式(如 ONNX),或针对特定硬件(如 NVIDIA GPU)进行编译优化(如使用 TensorRT)。
- 推理服务封装: 将模型嵌入到推理服务器中(如 Triton Inference Server, TFServing),并提供 API(通常是 HTTP/REST 或 gRPC)。
- 资源管理与编排: 使用容器化(Docker)和编排工具(Kubernetes)来部署和管理服务实例。
- 监控与扩缩容: 实施监控(性能、资源利用率、QPS)并根据负载自动扩缩容。
关键考虑因素:
- 延迟: 单个请求的响应时间。
- 吞吐量: 单位时间处理的请求数量。
- 成本: 硬件(GPU/CPU)和云服务成本。
- 硬件兼容性: GPU (NVIDIA), CPU (x86/ARM), 专用AI芯片(如 AWS Inferentia, Google TPU)。
- 模型精度: FP32, FP16, INT8 等,需要在精度和性能之间权衡。
2. 解释一下什么是模型量化?它有哪些主要类型和好处?
答:模型量化是一种将模型权重和激活值从高精度(如32位浮点数,FP32)转换为低精度(如16位浮点数FP16,16位整数INT16,或8位整数INT8)的技术。
-
主要类型:
- FP16: 半精度浮点,GPU(尤其是Tensor Cores)上计算效率高,精度损失极小。
- INT8: 8位整数,大幅减少模型大小和内存占用,需要校准来确定缩放因子,可能带来一定精度损失。
- 量化感知训练: 在训练过程中模拟量化行为,让模型适应低精度计算,从而在部署时获得更高的精度。
-
好处:
- 减少模型大小: INT8 模型大约是 FP32 的 1/4,节省存储和传输带宽。
- 降低内存带宽需求: 更小的数据位宽意味着在读写内存时带宽压力更小。
- 加速计算: 特定硬件(如 NVIDIA Tensor Cores)对低精度计算有巨大优化,能显著提升计算吞吐量。
3. 动态批处理与静态批处理有什么区别?分别适用于什么场景?
答:
静态批处理: 在模型启动前就固定好批处理大小。所有请求都必须填充或截断到这个固定尺寸。
- 优点: 实现简单,推理引擎可以预先优化。
- 缺点: 不灵活。如果请求大小不一,会造成计算资源浪费(填充导致)或信息丢失(截断导致)。
场景: 请求尺寸固定且已知的应用(如处理固定大小的图像)。
动态批处理: 推理服务器持续接收请求,并将多个请求动态地组合成一个批次送入模型计算。它允许每个请求有不同的输入尺寸。
- 优点: 极大提高吞吐量和GPU利用率,尤其适合处理流式、不定长的请求(如文本生成)。
- 缺点: 实现更复杂,需要服务器端支持(如NVIDIA Triton)。
场景: 绝大多数在线推理服务,特别是自然语言处理任务。
4. 什么是计算图?在部署时为什么常需要将动态图转换为静态图?
答:
- 计算图: 是描述模型计算过程的数据结构,由节点(运算符)和边(张量)组成。
- 动态图: 如 PyTorch 的默认模式,边定义边执行,非常灵活便于调试。
- 静态图: 如 TensorFlow 1.x,先完整定义整个图,然后再执行。
转换原因:
- 性能优化: 静态图允许框架进行全局的优化,如算子融合、常量折叠等,减少运行时开销。
- 跨平台部署: 静态图是跨平台部署的标准中间表示(如 ONNX),可以被各种推理引擎(TensorRT, OpenVINO等)读取和执行。
- 序列化: 静态图可以轻松地序列化到文件,独立于原始Python代码,便于在生产环境中部署。
5. 解释ONNX是什么以及它在部署流水线中的作用。
答: ONNX 是一种开放的格式,用于表示深度学习模型。它定义了一套可扩展的计算图模型及其运算符的标准。
作用:
- 互操作性: 充当“中间人”角色。你可以将PyTorch, TensorFlow, JAX等框架训练的模型转换为ONNX格式,然后使用另一个支持ONNX的推理引擎(如ONNX Runtime, TensorRT, OpenVINO)来运行它。实现了训练框架和推理引擎的解耦。
- 性能优化: 专门的推理引擎(如ONNX Runtime)可以对ONNX图进行大量图优化,提升推理速度。
- 硬件适配: 通过不同的ONNX Runtime执行提供者,同一份ONNX模型可以在不同硬件(NVIDIA GPU, Intel CPU, ARM等)上运行。
6. 在GPU推理中,CUDA和CuDNN分别扮演什么角色?
答:
- CUDA: 是NVIDIA推出的通用并行计算平台和编程模型。它允许开发者使用C++等语言直接利用NVIDIA GPU的强大计算能力。在推理中,它提供了启动GPU内核、管理设备内存等底层基础。
- CuDNN: 是NVIDIA基于CUDA平台打造的深度神经网络加速库。它提供了高度优化的、针对深度学习基本操作(如卷积、池化、归一化、激活函数)的实现。大多数深度学习框架(如PyTorch, TensorFlow)在GPU上的后端都调用了CuDNN库来获得极致的性能。
关系: CuDNN构建在CUDA之上,为深度学习提供了更高级、更专业的API。
7. 请列举几个常用的模型推理框架/服务器,并简述其特点。
答:
- NVIDIA Triton Inference Server: 当前业界标杆。支持多种框架(TensorRT, ONNX, PyTorch, TensorFlow等),支持动态批处理、模型队列、多GPU多节点部署,功能极其强大。
- TensorFlow Serving: 专为部署TensorFlow模型而设计,与TF生态无缝集成。
- TorchServe: PyTorch官方推出的服务框架,适合PyTorch模型,但生态和功能相比Triton稍弱。
- ONNX Runtime: 轻量级、高性能的推理引擎,完美支持ONNX模型,跨平台跨硬件。
- OpenVINO: Intel推出的工具包,主要用于在Intel硬件(CPU, GPU, VPU)上优化和部署模型。
8. 在Kubernetes中部署模型服务,通常涉及哪些关键K8s资源?
答:
- Docker镜像: 将模型、推理代码和依赖环境打包成一个容器镜像。
- Deployment: 定义Pod的副本数、更新策略等,用于无状态服务的部署和扩缩容。
- Service: 为一组Pod提供稳定的网络入口和负载均衡。
- Horizontal Pod Autoscaler: 根据CPU/内存使用率或自定义指标(如QPS)自动扩缩容Deployment的副本数。
- ConfigMap / Secret: 用于存储配置信息(如模型路径)和敏感信息(如API密钥),并以卷的形式挂载到Pod中。
9. 如何监控一个已部署的模型服务的健康状况和性能?
答: 基础设施监控:监控Pod/节点的CPU、内存、GPU利用率(如使用Prometheus + Grafana)。
-
业务指标监控:
- 吞吐量: QPS(每秒查询数)。
- 延迟: P50, P95, P99分位的请求延迟。
- 错误率: HTTP 5xx错误的数量或比例。
- 自定义指标: 如模型的输入/输出分布,用于检测数据漂移。
- 日志: 收集和分析应用日志(如使用ELK/EFK栈)。
10. 解释一下“冷启动”问题以及如何缓解它。
答:
- 冷启动: 指当一个模型服务实例从完全停止状态到能够处理第一个请求所需的时间。这个过程包括加载容器镜像、加载模型到内存/GPU、初始化推理运行时等,耗时可能从几秒到几分钟,导致第一个请求延迟极高。
-
缓解方案:
-
保持最小副本数: 在K8s中,设置
Deployment的replicas至少为1,确保始终有实例在运行。 - 使用更轻量的运行时: 优化容器镜像大小,移除不必要的依赖。
- 模型预加载: 在容器启动脚本中主动加载模型,而不是在第一个请求时懒加载。
- 基于请求预测的扩容: 在预期流量增长前提前扩容。
-
保持最小副本数: 在K8s中,设置
深入优化与技术
11. 请详细说明NVIDIA TensorRT的优化流程和核心优化技术。
答:
TensorRT是NVIDIA推出的高性能深度学习推理SDK和运行时。其优化流程如下:
- 导入模型: 从框架(PyTorch/TF)或ONNX导入模型。
- 转换与优化: 在构建阶段进行一系列图级和层级优化。
- 生成引擎: 生成一个针对目标GPU平台高度优化的序列化文件(plan文件)。
- 部署推理: 运行时加载plan文件进行高效推理。
核心优化技术:
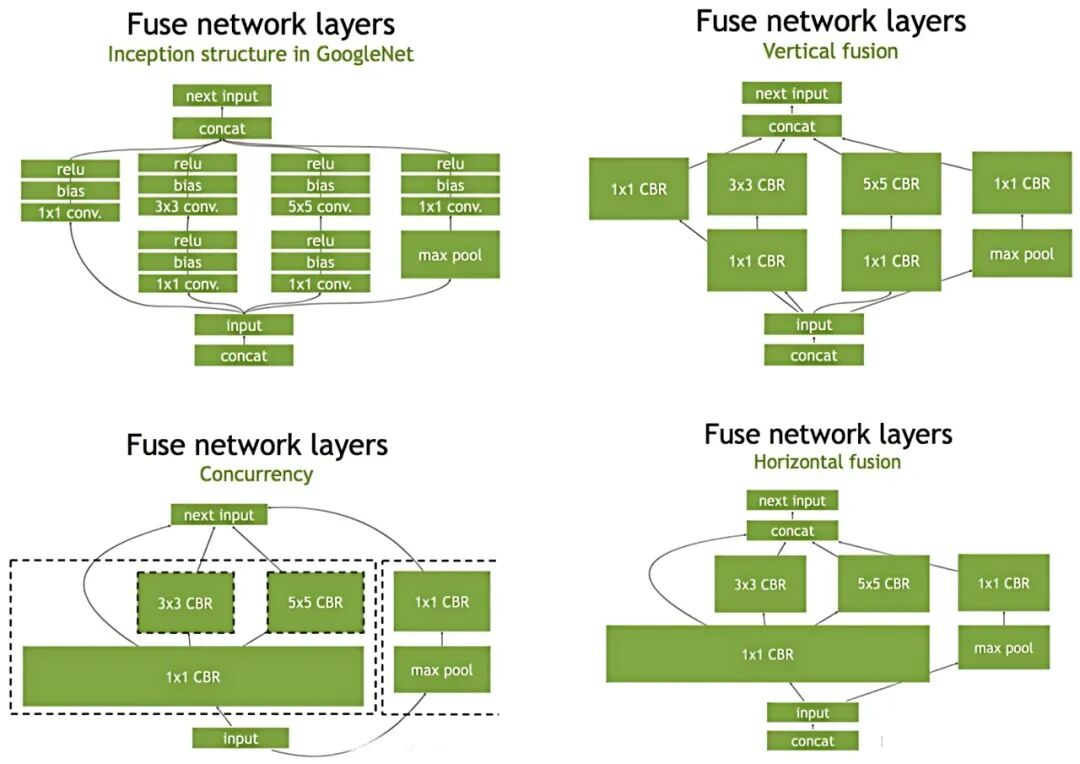
-
层与张量融合: 将多个层合并为一个更复杂的核函数。例如,将卷积、偏置和ReLU激活函数融合为一个单一操作。这减少了内核启动次数和全局内存的访问次数,是提升性能的关键。
-
精度校准: 支持FP16和INT8量化,通过校准过程确定缩放因子,在最大限度保持精度的前提下提升速度。
-
内核自动调优: 基于目标GPU的架构(SM数量、内存带宽等),为每一层选择最优的内核实现。
-
动态张量内存: 重用中间张量的内存,减少内存占用和分配开销。
-
多流执行: 高效地并行处理多个输入流。
12. 什么是KV Cache?它在自回归模型(如LLM)推理中如何优化性能?
答:
在生成任务中(如GPT),模型是自回归的,每次 forward 调用只生成一个 token。
-
问题: 在生成第
n个 token 时,需要将前n-1个 token 重新输入模型计算,这导致了大量的重复计算。 - KV Cache: 缓存每个Transformer解码层中Attention机制的Key和Value矩阵。在生成下一个token时,只需计算当前新token的Q, K, V,并与缓存中之前所有token的K, V进行Attention计算,避免了重复计算历史token的K和V。
-
优化效果: 极大减少了计算量,将生成过程的计算复杂度从
O(n^2)降低到O(n),显著降低了延迟。但代价是增加了内存开销,缓存大小与序列长度和批次大小成正比。
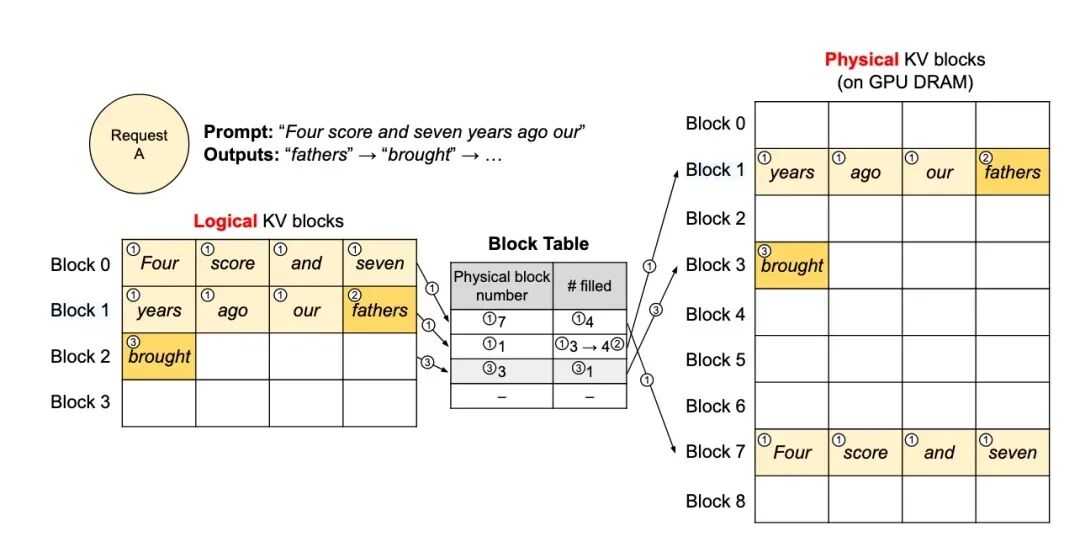
13. 解释PagedAttention的工作原理及其解决的问题。
答: PagedAttention 是 vLLM 项目的核心创新,灵感来自操作系统的虚拟内存和分页思想。
-
问题: 在LLM推理中,由于KV Cache的存在,内存管理成为瓶颈。请求所需的内存是动态变化的(序列长度不确定),且由于并行采样等原因,一个请求可能对应多个输出序列。这会导致内部碎片化和内存浪费。
-
解决方案:
- 分块: 将KV Cache划分为固定大小的块(Block),每个块包含一定数量token的K和V数据。
- 逻辑管理: 为每个请求维护一个逻辑块表,记录该请求的KV Cache实际存储在哪些物理块中。
- 物理管理: 系统维护一个全局的物理块池。当请求需要分配新空间时,就从池中分配一个空闲块。
-
优势:
-
近乎零内部碎片: 按块分配,浪费的空间最多只是一个块的一小部分。
-
高效内存共享: 在并行采样等场景下,多个输出序列可以共享父序列的物理块,只需在逻辑块表中引用即可,避免了物理内存的重复存储。
-
-
14. 在CPU上部署大模型,有哪些关键的优化技术?
答:
- 量化: INT8量化同样适用于CPU,并能利用Intel的VNNI等指令集加速。
- 算子优化与硬件指令集: 使用高度优化的数学核函数库(如Intel oneDNN, formerly MKL-DNN),这些库会利用SSE, AVX2, AVX-512等SIMD指令集来加速计算。
- 模型格式转换: 使用OpenVINO工具包,将模型转换为IR格式,并进行图优化和硬件特定优化。
- 批处理: 同样适用,通过提高CPU的并行度来提升吞吐量。
- 进程绑定: 将推理进程绑定到特定的CPU核上,减少上下文切换带来的开销。
15. 如何解决大模型权重过大导致的加载慢和内存占用高的问题?
答:
- 量化: 最直接有效的方法,INT8模型大小和内存占用降为FP32的1/4。
- 模型分片: 对于多GPU环境,使用Tensor Parallelism或Pipeline Parallelism将模型的不同部分分布到多个GPU上。
-
内存映射文件: 如Hugging Face的
safetensors格式支持内存映射,允许系统按需将权重从磁盘加载到内存,而不是一次性全部加载,极大减少初始加载时间和峰值内存。 - 卸载: 将暂时不用的层或权重换出到CPU内存甚至磁盘,使用时再换入。DeepSpeed等框架支持此功能。
16. 除了延迟和吞吐量,还有哪些指标对衡量模型部署性能至关重要?
答:
- 首Token延迟: 对于流式响应应用,用户接收到第一个字符的时间至关重要。
- Token吞吐量: 每秒生成的token数量,更能准确衡量文本生成服务的效率。
- 资源利用率: GPU利用率、CPU利用率、内存使用率。高吞吐量但GPU利用率低可能意味着存在瓶颈。
- 成本效益: 每1000次请求的成本($/1k tokens),是商业决策的关键指标。
- 可用性: 服务的正常运行时间(uptime)。