
大模型微调(Fine-tuning)是在预训练模型的基础上,通过特定领域或任务的数据进行针对性训练,以提升模型在目标场景中的性能。其核心流程如下:
1、明确目标和数据准备
明确模型的目标,比如是文本类型,还是图片类型,还是推理类型。并且做好评估模型的指标。
数据准备,尽量多收集更多场景的数据,确保数据的真实性和多样性,将数据分为训练集,验证集,测试集(常用的比例如80%-10%-10%)
2、数据预处理
将数据进行清洗,格式转换成模型识别的格式,还有使用预训练模型对应的分词
3、基座模型加载和模型参数设置
选择对应的基座模型,并进行模型参数设置,比如序列长度,数据类型,内存优化参数等
调整模型结构,指微调的方法,选择全参数还是参数高效微调,现在大模型微调基本上选择参数高效微调(如LoRA/QLoRA)
4、训练超参数及优化策略
比如设置学习率,通常较少的学习率是1e-5到5e-5,优化器选择,权重衰减,混合精度训练等
5、进行训练和验证
模型训练train()时可以多训练几个批次,拿着验证集去验证模型eval()
6、模型评估和优化
根据模型评估指标去评估,差异大时,需要进行超参数调优,进行多轮训练
7、模型保存及上线部署
模型保存save()导出,最后部署给别人调用。就像代码升级一样。
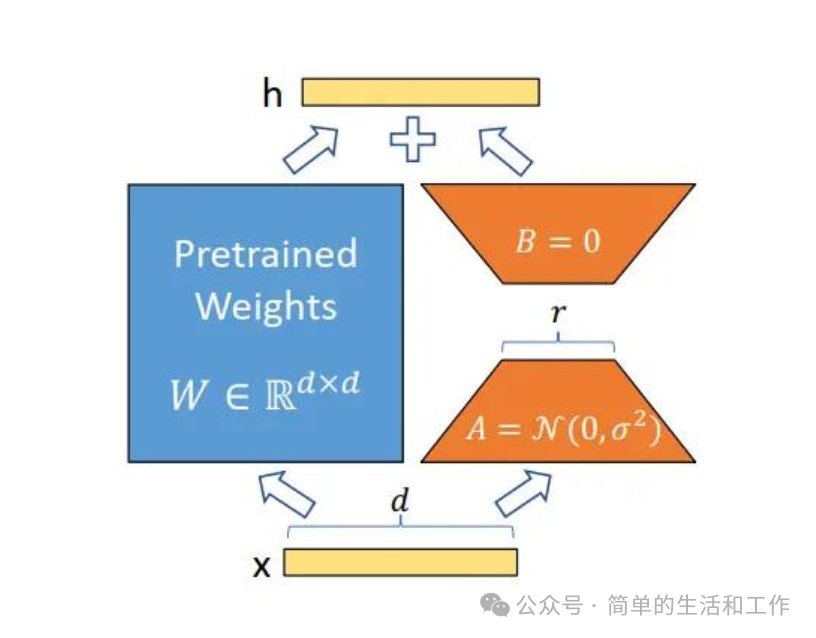
说一说我理解的参数高效微调模型的LoRA原理,是基于数学向量运算为理论基础,看下面的LoRA原理图,左边是基座模型,右边是LoRA层,训练时两边互相不干扰,训练完后进行统一的输出。模型本质是一个非常大的多维度向量,右边LoRA层就是利用2个小维度的向量相乘,得到一个大的向量,最后是2个同纬度的向量进行向量的相加。得出最后的结果输出。改变原模型输出质量,可以输出更准确的答案。
请多互动,多多交流。