
内容
隐藏
一、获取语料
数据集
语料是NLP的生命之源,所有的NLP问题都是从语料中学到数据分布的规律
语料的分类
- 单语料
- 平行语料
- 复杂结构
| 类型 | 说明 | 例子 |
|---|---|---|
| 单语料 | 只有句子和句子集合 | 整理好的英文文档,中文古诗数据集 |
| 平行语料 | 有句子和句子之间的1 vs 1对应关系,有标注的句子,对话问答和翻译中比较多 | 中英文翻译数据集,对话数据集 |
| 复杂结构 | 复杂的结构 知乎的回答和评论数据 | 知乎的回答和评论数据 |
语料和数据集例子
- Penn Treebank
- Daily Dialog
- WMT-1x翻译数据集
- 中文闲聊数据集
- 中国古诗数据集
英文语言模型语料总结
http://nlpprogress.com/english/language_modeling.html
获取方法
- 公开数据集
- 爬虫
- 社交工具埋点
- 数据库
Penn Treebank
-
Pytorch集成的数据集DataLoader:
https://pytorchnlp.readthedocs.io/en/latest/_modules/torchnlp/datasets/penn_treebank.html
-
Benchmark结果:
https://paperswithcode.com/sota/language-modelling-on-penn-treebank-word
例句:
no price for the new shares has been set instead the companies will leave it up to the marketplace to decide cray computer has applied to trade on nasdaq
Daily Dialog
英文对话经典bench mark数据集
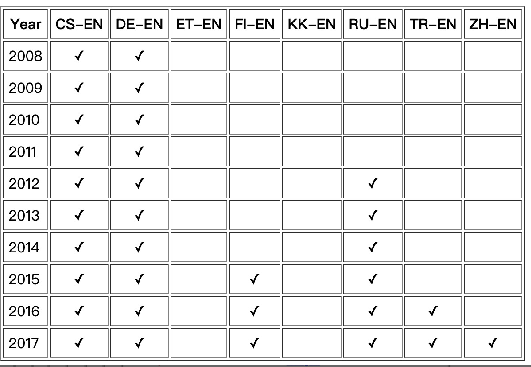
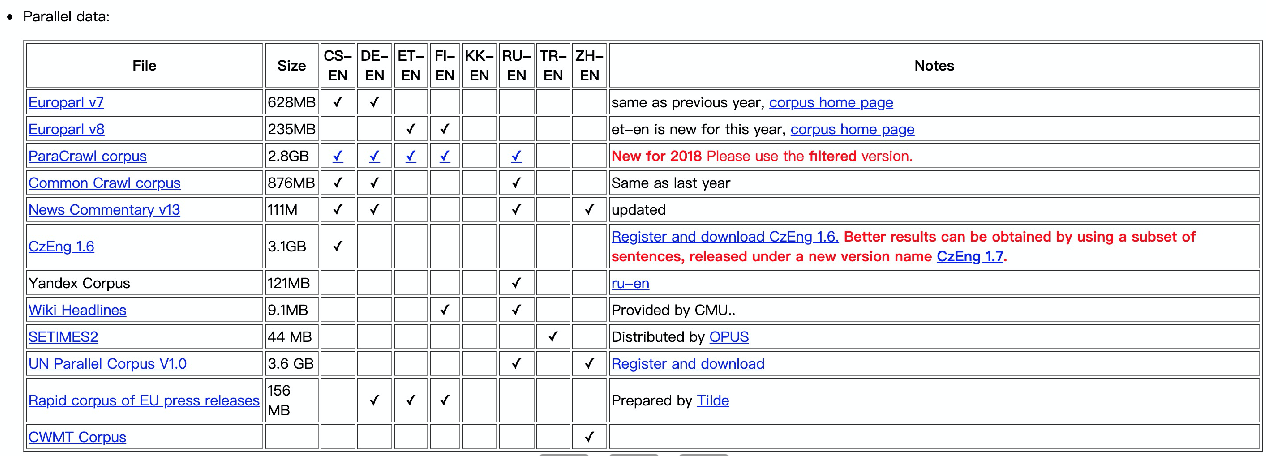
WMT-1x翻译数据集
官网:http://www.statmt.org/wmt18/translation-task.html
测试集:
平行语料:
中文闲聊数据集
- 50万中文闲聊数据:https://drive.google.com/file/d/1nEuew_KNpTMbyy7BO4c8bXMXN351RCPp/view?usp=sharing
- 日常闲聊数据: https://github.com/codemayq/chinese_chatbot_corpus
中国古诗数据集

二、预处理
NLTK
- https://www.nltk.org/
- 基本的英文NLP操作均支持
Tokenize :


命名实体识别

句法树构造

Jieba分词


SnowNLP
- https://github.com/isnowfy/snownlp
- pip install snownlp

Pyrouge
- 评测文本摘要好坏开源库

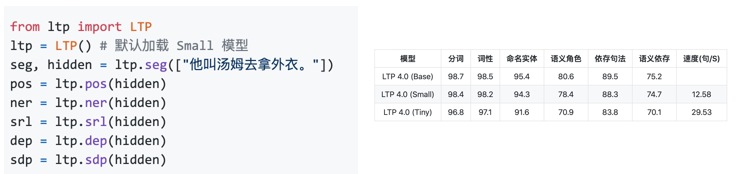
LTP
-
哈工大做的强大开源NLP工具
常用python-based机器学习框架
- Pytorch
- 本门课程正课主要示例代码框架
- 从诞生起即是动态图
- 对NLP任务非常友好
- https://pytorch.org/
- Tensorflow
- Keras
Sklearn
- https://scikit-learn.org/stable/
- 机器学习和数据处理辅助神器
Gensim
- 知乎教程:https://zhuanlan.zhihu.com/p/37175253
- 关键技能:
- Tf-Idf
- LSA
- LDA
- Word2vec
- 从语料构建词典

三、特征工程
简单的特征工程
- Numpy https://numpy.org/
- Tf-Idf
- Word2vec
Numpy
TF-IDF
-
Term Frequency
- The specihcity of a term can be quantihed as an inverse function of the number of documents in which it occurs.
- 高频词往往能够反馈文章的主要思想
- 购买、折扣、优惠==>广告、电商等
- 恐怖主义、叙利亚、斩首==>国际政治
- 威尼斯、圣托里尼、极光、洲际酒店==>旅游
-
Inverse Document Frequency
- The specihcity of a term can be quantihed as an inverse function of the number of documents in which it occurs.
- 很多无实际意义的虚词词频也很高
- 的、是、好==>无实际意义的虚词,几乎所有文章都存在
- 一个直观结论:词频高但是文档频率低的词往往能反馈文档的主题



-
词云制作

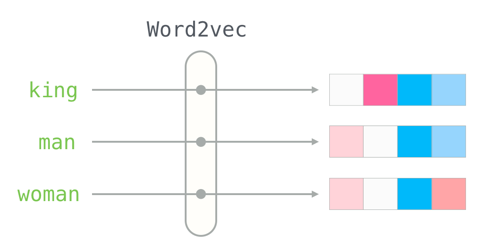
Word2Vec
- 使用一个欧式空间向量表示词汇
四、模型介绍
- 朴素贝叶斯
- 线性回归模型
- 逻辑回归
- CNN
- LSTM
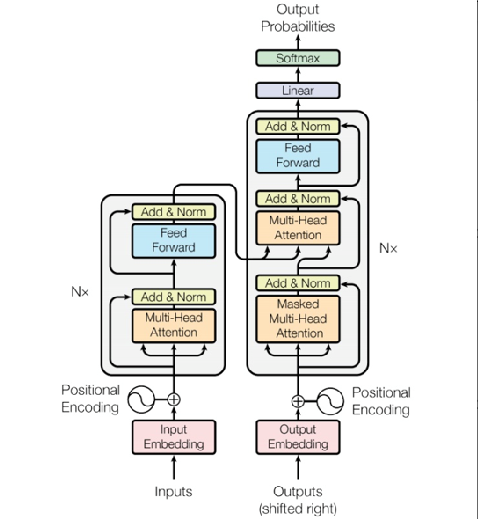
- Transformer
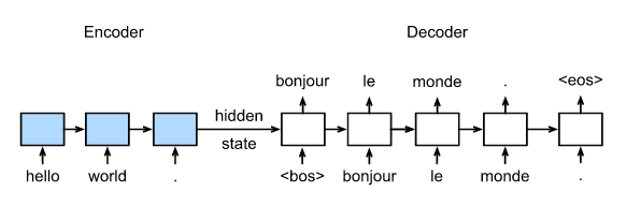
- Sequence to Sequence
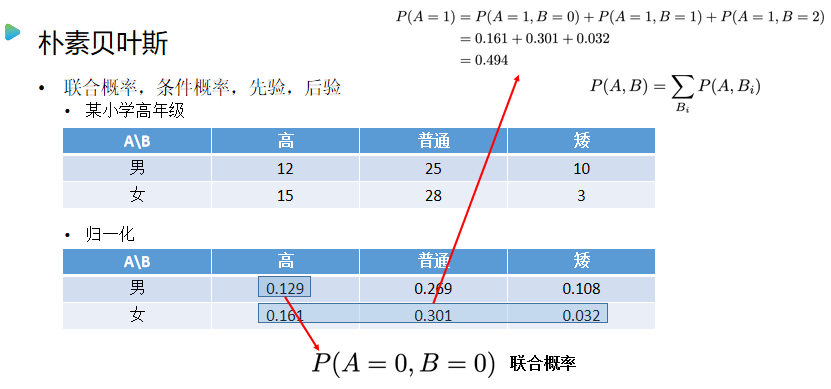
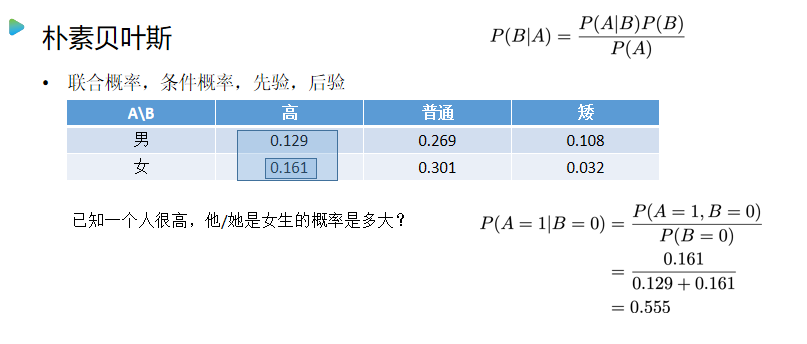
朴素贝叶斯
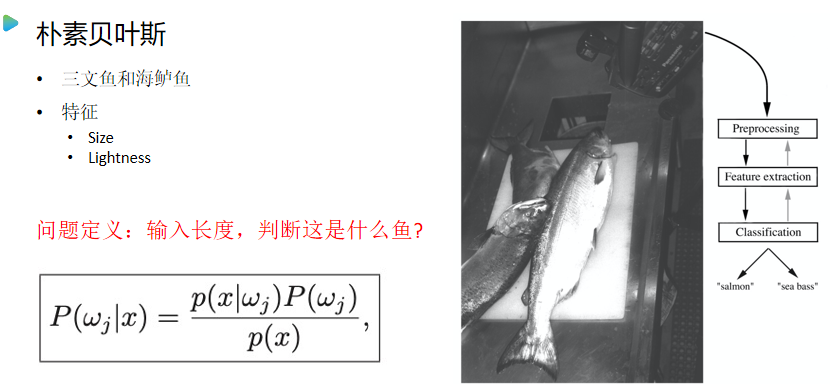
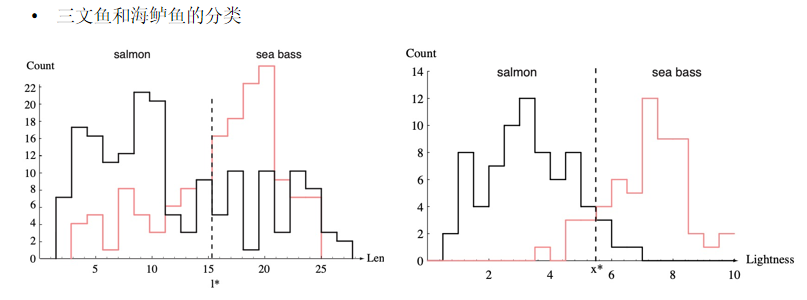
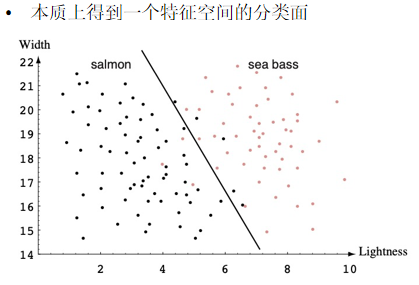
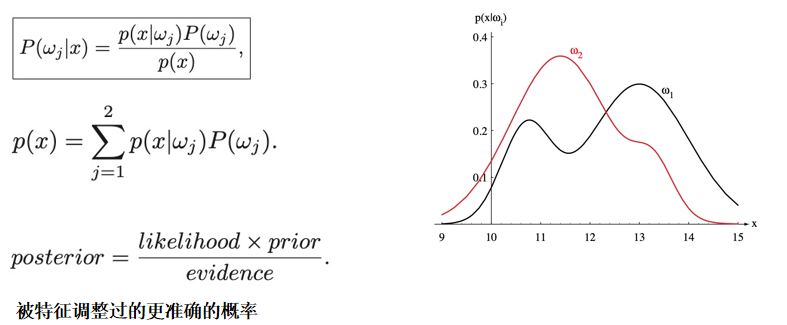
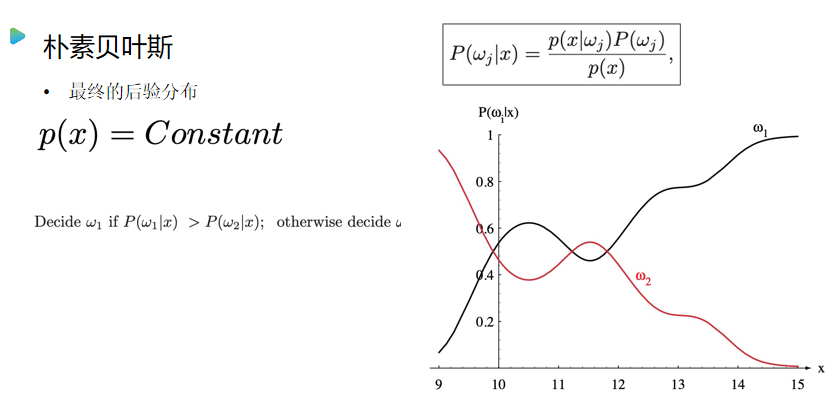

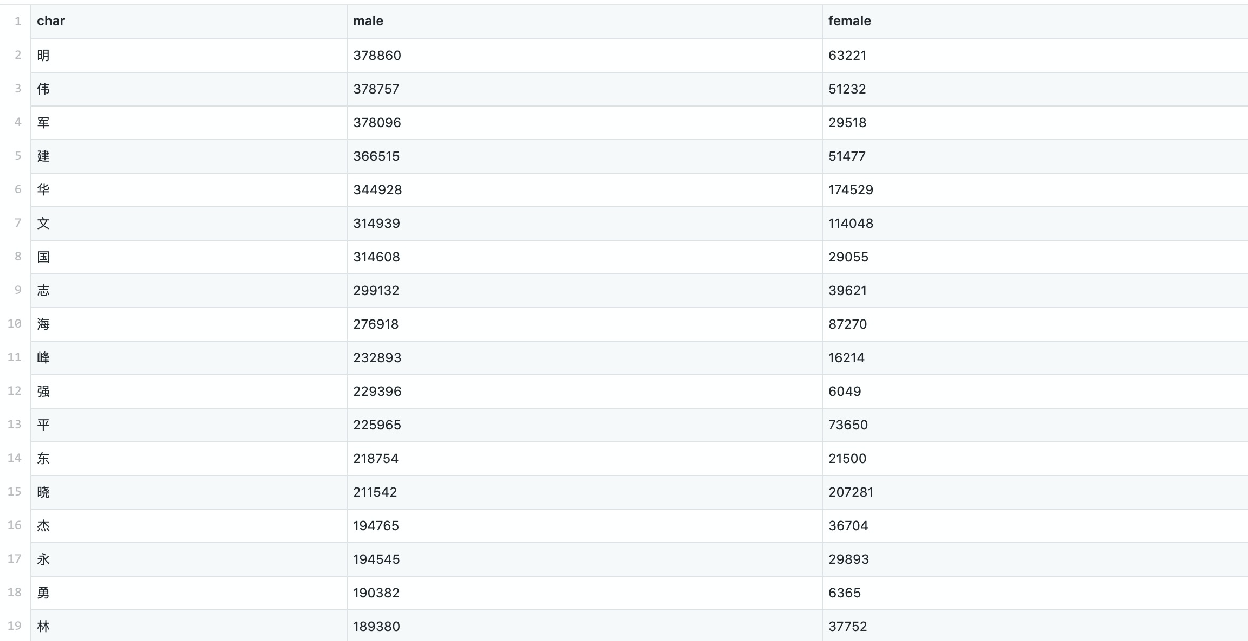
数据集:https://github.com/observerss/ngender
-
代码示例
- 初始化
- 统计频率
- 得到先验概率、联合概率
- 根据后验概率判决


概率计算

线性回归
逻辑回归
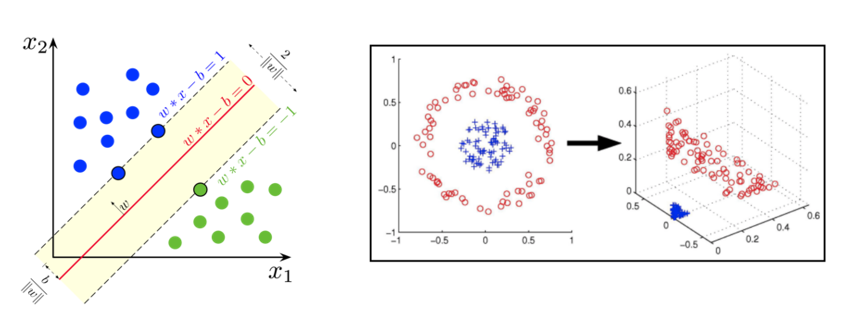
SVM
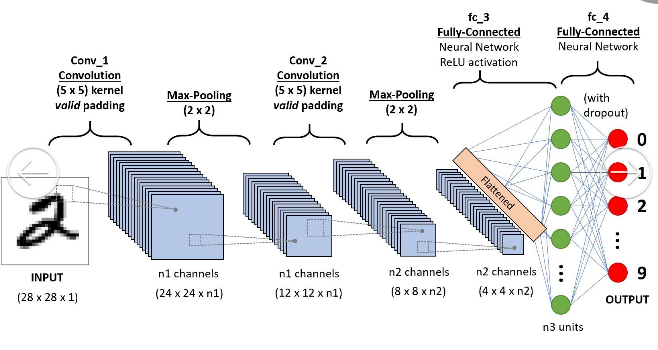
CNN
RNN
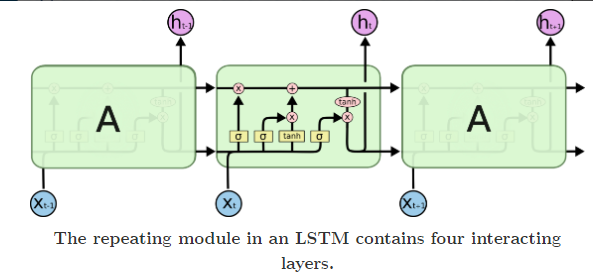
Transformer
Sequence to Sequence
五、评测标准
NLP常见评测标准
-
Accuracy
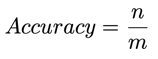
-
F1-Score

-
AUC
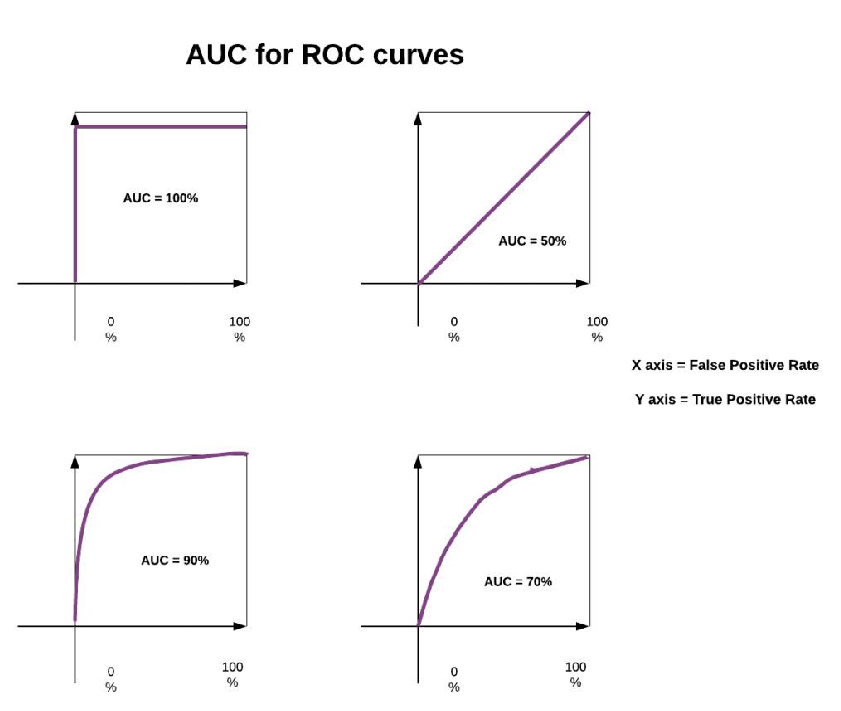
-
BLEU
- 多用于翻译和文本生成
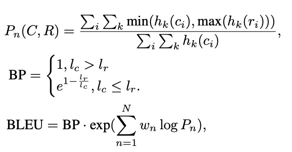
-
Rouge-L
- 文本摘要中重要指标
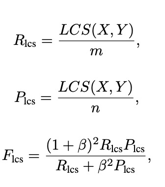
六、项目介绍
有趣的NLP项目
- 狗屁不通文章生成器


-
GPT-2闲聊
- 地址:https://github.com/yangjianxin1/GPT2-chitchat
- 基于hugging face的GPT
- 和Microsoft的paper
- 经过作者的调优和MMI
- 做出的效果很好的中文闲聊工具


-
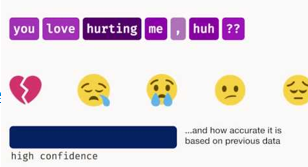
Deep Moji
- Github地址: https://github.com/bfelbo/DeepMoji
- 输入一句话,转化成表情
-
根据文章返回文章主要内容摘要和思想