
概述
在语言处理中,用向量 x 表示文本数据,以反映文本的各种语言属性。 ——约阿夫 • 戈尔德贝格
对于任何机器学习问题,特征提取都是一个重要的步骤。不管建模算法有多好,差的特征肯定会导致差的结果。在计算机科学中,这通常称为“垃圾进,垃圾出”。前两章已经介绍了自然语言处理的概述,所涉及的不同任务和挑战,以及典型的自然语言处理流水线。 本章将讨论这样一个问题:
如何对文本数据进行特征工程。
换句话说,如何将给定的文本 转换成数值形式,从而可以将其输入自然语言处理和机器学习算法中。在自然语言处理 中,这种将原始文本转换为适当数值形式的过程叫文本表示。本章将研究文本表示(将文本表示为数值向量)的不同方法。在自然语言处理流水线中,本章的讨论范围如图 3-1 的 虚线框所示。
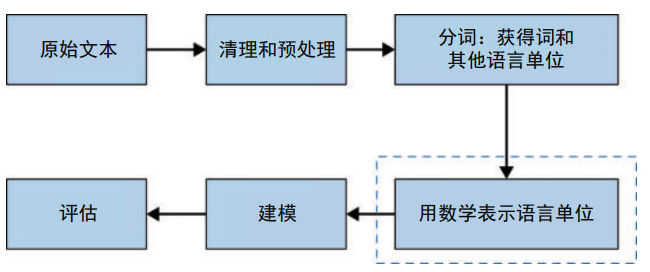
图 3-1:本章在自然语言处理流水线中的位置
无论数据是文本、图像、视频还是语音,特征表示是机器学习项目的通用步骤。然而,与其他格式的数据相比,文本的特征表示往往要复杂得多。为了理解这一点,先来看其他数据格式是如何用数值表示的。首先,考虑图像的情况。假如现在要构建一个猫狗图像分类器。为了训练机器学习模型来完成这个任务,需要向它提供标注好的图像。
如何将图像馈送到机器学习模型中?
图像在计算机中是以像素矩阵的形式存储的,矩阵中的每个元素 [i,j] 表示图像的像素 i,j。存储在元素 [i,j] 处的实数值表示图像中相应像素的强度,如 图 3-2 所示。这种矩阵表示精确地表示了完整的图像。视频也是类似的:视频只是帧的集 合,其中的每一帧都是一幅图像。因此,任何视频都可以表示为矩阵的顺序集合,其中每帧一个矩阵,按顺序排列。

图 3-2:人类眼中的图像和计算机眼中的图像(参见 Suraj Bansal 的文章“Convolutional Neural Networks Explained”)
现在考虑语音,语音是以波的形式传输的。为了在数学上表示语音,需要对波进行采样并记录其振幅(高度),如图 3-3 所示。
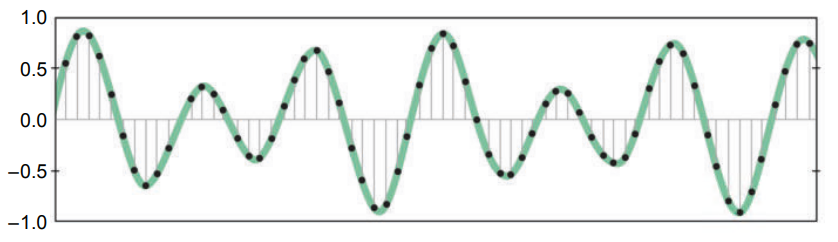
图 3-3:对语音波形进行采样
采样后得到一个数值数组,表示声波在固定时间间隔的振幅,如图 3-4 所示。

图 3-4:用数值向量表示的语音信号
从上面的讨论中,可以清楚地看到,用数学形式表示图像、视频和语音是非常简单的。 那么文本呢?事实证明,表示文本并不简单,因此本章会集中讨论解决这个问题的各种方法。给定一段文本,找到用数学形式来表示它的方法,这叫文本表示。在过去的几十 年里,尤其是在最近的十年里,文本表示一直是活跃的研究领域。本章将从简单的方法开始,然后一直讨论到文本表示的最新技术。这些方法分为以下四类:
- 基本的向量化方法
- 分布式表示
- 通用语言表示
- 人工特征
接下来,本章将逐一介绍这四类方法,包括每类方法中的各种算法。但在深入研究各种方法之前,先考虑以下场景:给定一个标注好的文本语料库,构建一个情感分析模型。为了 正确预测句子的情感,模型需要理解句子的意思。为了正确提取句子的意思,需要把握以下关键点。
- 把句子切分成词素、词和短语等词法单位。
- 推导每个词法单位的意义。
- 理解句子的句法(语法)结构。
- 理解句子所在的语境。
句子的语义(意义)是由以上关键点的结合而产生的。因此,任何好的文本表示方法都必须全力促成这些关键点的提取,以反映文本的语言属性。否则,文本表示方法就不会有多大的效果。
在自然语言处理领域,与其将顶级算法应用于普通的文本表示,不如向普通 算法提供优秀的文本表示,后者会让你走得更远。
先来看一个贯穿本章的关键概念:向量空间模型。
1.向量空间模型
从上述引言中可以清楚地看到,为了使机器学习算法能够处理文本数据,必须先将文本数据转换成某种数学形式。在本章中,数字向量将用于表示文本单元(字符、音素、词、短 语、句子、段落和文档)。这叫向量空间模型(vector space model, VSM)。
向量空间模型是 一个简单的代数模型,广泛用于表示任何文本对象。向量空间模型是文档评分、文档分类 和文档聚类等许多信息检索操作的基础。向量空间模型是将文本单元表示为向量的数学模 型。向量的最简单形式是标识符向量,例如语料库词汇表索引号向量。在这种情况下,计 算两个文本对象之间相似度的最常用方法是使用余弦相似度:对应向量之间夹角的余弦。 0°的余弦为 1,180°的余弦为 –1,且余弦从 0°到 180°单调下降。给定两个向量 A 和 B, 每个向量都有 n 个分量,它们之间的相似度计算如下:
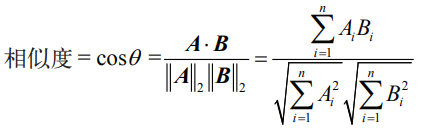
其中 Ai 和 Bi 分别是向量 A 和 B 的第 i 个分量。有时,人们也使用向量之间的欧氏距离来 捕捉相似性。 本章研究的所有文本表示方法都属于向量空间模型的范畴。但是,不同方法之间的区别在 于,产生的向量能否更好地捕捉文本的语言属性。好了,现在可以开始讨论各种文本表示方法了。
2.基本的向量化方法
先从文本表示的基本思想开始:将文本语料库词汇表(V)中的每个词映射到一个唯一的 ID(整数值),然后将语料库中的每个句子或文档表示为 V 维向量。那么这一思想是如何 实现的?为了更好地理解这一点,假设语料库只有四个文档——D1、D2、D3、D4,如表 3-1 所示。
表3-1:简易语料库
| 文档编号 | 文档内容 |
|---|---|
| D1 | Dog bites man. |
| D2 | Man bites dog. |
| D3 | Dog eats meat. |
| D4 | Man eats food. |
将文本转换成小写格式并忽略标点符号后,这个语料库的词汇表由六个词组成:[dog, bites, man, eats, meat, food]。词汇表可以按任何顺序组织。本例直接使用词汇在语料库中出现的顺序。现在,语料库中的每个文档都可以用六维向量表示。本节将讨论实现这 一目标的多种方法。
假设文本已经按照第 2 章的预处理步骤进行了预处理(转换成小写、 删除标点符号等)并进行了分词(将文本字符串拆分为词)。现在从独热编码(one-hot encoding)开始。
2.1独热编码
在独热编码中,语料库词汇表中的每个词 w 被赋予一个介于 1 和 |V| 之间的唯一整数 ID, wid,其中 V 是语料库词汇的集合。然后,每个词都由 V 维二进制向量(若干 0 和 1)表 示。在索引 =wid 处,只需简单地设置成 1,其余元素都用 0 填充。多个词表示经组合后形 成句子表示。
现在通过简易语料库来理解这一点。首先将这六个词映射到唯一的 ID:
dog=1, bites=2, man=3, meat=4, food=5, eats=62。
根据该方法,每个词是一个六维向量。由于“dog”映 射到 ID 1,因此 dog 表示为 [1 0 0 0 0 0]。bites 表示为 [0 1 0 0 0],以此类推。因此, D1 表示为 [ [1 0 0 0 0] [0 1 0 0 0] [0 0 1 0 0 0] ]。D4 表示为 [ [0 0 1 0 0] [0 0 0 0 1 0] [0 0 0 0 0 1] ]。语料库中的其他文档也可以类似地表示。 现在从基本原理的角度看一下在 Python 中实现独热编码的简单方法。以下简化的示例实现了独热编码。现实世界的项目主要使用 scikit-learn 实现的独热编码,它的优化程度要高很多。 因为文本需要分词,所以在这个例子中可以在空白处拆分文本。
def get_onehot_vector(somestring):
onehot_encoded = []
for word in somestring.split():
temp = [0]*len(vocab)
if word in vocab:
temp[vocab[word]-1] = 1
onehot_encoded.append(temp)
return onehot_encoded
get_onehot_vector(processed_docs[1])输出:[[0, 0, 1, 0, 0, 0], [0, 1, 0, 0, 0, 0], [1, 0, 0, 0, 0, 0]]。
前面已经介绍了这个方法,现在来讨论它的优点和缺点。从积极的方面来看,独热编码是直观的,易于理解和实现。但是,它有以下几个缺点。
- 独热向量的大小与词汇量的大小成正比,而大多数真实世界的语料库有很大的词汇量。 这将造成稀疏表示,其中向量中的大多数元素是零,使得存储、计算和学习的计算效率 低下(稀疏导致过拟合)。
- 独热编码的文本表示并非固定长度,也就是说,如果文本有10 个词,那么与 5 个词文本相比,得到的表示将更长。对于大多数学习算法,特征向量需要具有相同的长度。
- 独热向量把词看作基本单位,没有词与词之间相似性的概念。例如,考虑三个词:run、 ran 和 apple。run 和 ran 意思相似,run 和 apple 意思不同。但是如果取它们各自的向量, 计算它们之间的欧氏距离,那么它们之间的距离都是相等的(根号 2 )。因此,从语义上 来说,独热向量很难捕捉一个词相对于其他词的意义。
- 假设现在使用简易语料库训练一个模型。在运行时,如果出现句子“man eats fruits”, 由于训练数据中不包括“fruits”,因此模型无法表示它。这就是所谓的未登录词(out of vocabulary, OOV)问题。独热编码方法无法处理此问题。唯一的处理办法是扩展词汇表、 给新词分配 ID、重新训练模型等。
目前,独热编码方法已经很少有人使用。
独热编码的部分缺点可以通过下一节中描述的词袋方法来解决。
2.2词袋
词袋(bag of words, BoW)是一种经典的文本表示技术,在自然语言处理中得到了广泛的 应用,特别是在文本分类问题中(见第 4 章)。词袋背后的关键思想是,忽略顺序和语境, 将所考虑的文本表示为“一袋词”(也就是词的集合)。词袋背后的基本直觉是,在数据集中属于给定类别的文本由一组唯一的词来表征。如果两个文本片段具有几乎相同的词,那 么它们就属于同一个袋子(类别)。
因此,通过分析文本中出现的词汇,可以识别出文本所属的类别(袋子)。 类似于独热编码,词袋也将词映射到 1 和 |V| 之间的唯一整数 ID。区别在于,语料库中的每个文档直接转换为 |V| 维向量,向量的第 i 个分量(i=wid),就是词 w 在文档中出现的次数。也就是说,只需根据词在文档中出现的次数来给 V 中的每个词打分。 因此,对于简易语料库(见表 3-1),词 ID 分别为 dog=1, bites=2, man=3, meat=4, food=5, eats=6,D1 变为 [1 1 1 0 0 0]。这是因为词汇表中的前三个词在 D1 中正好出现了一次, 后三个词根本没有出现。D4 变为 [0 0 1 0 1 1]。下面的代码显示了其中的关键部分。
from sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer()
# 为语料库构建词袋表示
bow_rep = count_vect.fit_transform(processed_docs)
# 打印词汇表映射
print("Our vocabulary: ", count_vect.vocabulary_)
# 打印前两个文档的词袋表示
print("BoW representation for 'dog bites man': ", bow_rep[0].toarray())
print("BoW representation for 'man bites dog: ",bow_rep[1].toarray())
# 使用此词汇表获取新文本的表示
temp = count_vect.transform(["dog and dog are friends"])
print("Bow representation for 'dog and dog are friends':",
temp.toarray())运行这段代码,就会注意到,在“dog and dog are friends”这个句子中,词“dog”这一 维度的值为 2,表示它在文本中出现的频率。有时,我们并不关心词在文本中出现的频 率,只想表示一个词是否存在于文本中。研究人员已经表明,这种不考虑频率的表示对于情感分析是有用的(见 Daniel Jurafsky 和 James H. Martin 的著作 Speech and Language Processing (3rd ed. draft) 中的第 4 章)。在这种情况下,只需使用 binary=True 选项初始化CountVectorizer,如以下代码所示。
count_vect = CountVectorizer(binary=True)
bow_rep_bin = count_vect.fit_transform(processed_docs)
temp = count_vect.transform(["dog and dog are friends"])
print("Bow representation for 'dog and dog are friends':", temp.toarray())以上是同一句子的不同表示。CountVectorizer 还支持字符和词的 n-gram。
下面来看看这种编码的优点。
- 与独热编码一样,词袋也很容易理解和实现。
- 使用词袋向量表示后,具有不同词汇的文档距离更远,具有相同词汇的文档距离更近。 D1 和 D2 之间的距离为 0,而 D1 和 D4 之间的距离为 2。因此,词袋方法产生的向量空间捕获了文档的语义相似性。因此,如果两个文档有相似的词汇表,那么它们在向量空间中会更接近,反之则会更远。
- 任意长度的句子,都具有固定长度的编码。
然而,词袋表示也有以下缺点。
- 向量的大小随着词汇表的增大而增大。因此,稀疏性仍然是一个问题。控制稀疏性的一 种方法是将词汇表限制在前 n 个最频繁的词汇中。
- 词袋表示不能捕捉到同义词之间的相似性。假设有三个文档:“I run”, “I ran”和“I ate”。这三个文档的词袋向量的距离是相等的。
- 词袋表示无法处理未登录词(即语料库中从未出现过的新词)。
顾名思义,词袋是词汇的“袋子”,语序信息在词袋表示中丢失了。在词袋方法中,D1 和 D2 具有相同的表示。 然而,尽管存在这些缺点,但由于原理简单、易于实现,词袋仍是一种常用的文本表示方法,尤其是对于文本分类问题。
2.3n-gram袋
到目前为止,所有的文本表示方法都将词视为独立的单元,并没有涉及短语或词序的概念。n-gram 袋(bag-of-n-grams, BoN)方法试图解决这一问题。它将文本分成多个块,每一块由 n 个连续词组成。这有助于捕获一定的语境,而早期的方法无法做到这一点。每个块叫 n-gram。语料库词汇表 V 则是文本语料库中所有不同 n-gram 的集合。语料库中的每个文档由长度为 |V| 的向量表示。该向量只统计文档中出现的 n-gram 的频率计数,对于不 存在的 n-gram,频率计数为零。
为了展开说明,考虑示例语料库。现在构造 2-gram 模型(亦称二元语法模型)。语料库中所有的 2-gram 集合为:{dog bites, bites man, man bites, bites dog, dog eats, eats meat, man eats, eats food}。每个文档的 n-gram 袋表示由一个八维向量组成。前两个文档的 2-gram 袋,D1 表示为 [1,1,0,0,0,0,0,0],D2 表示为 [0,0,1,1,0,0,0,0]。其余两个文件也遵循同样的方法来表示。注意,词袋方法是 n-gram 袋方法的一个特例,此时 n=1。 n=2 时叫“二元语法模型”,n=3 时叫“三元语法模型”,以此类推。此外需要注意,通过增大 n 的值,可以体现更多的语境。然而,这进一步增强了稀疏性。在自然语言处理中,n-gram 袋方法也叫“n-gram 特征选择”。
以下代码展示了 n-gram 袋表示的示例,它考虑了从一元、二元、三元语法模型的特征来表 示上述语料库。这里通过设置 ngram_range = (1,3) 来使用一元、二元、三元语法向量。
# 使用CountVectorizer和一元、二元、三元语法构建n-gram向量示例
count_vect = CountVectorizer(ngram_range=(1,3))
# 为语料库构建词袋表示
bow_rep = count_vect.fit_transform(processed_docs)
# 打印词汇表映射
print("Our vocabulary: ", count_vect.vocabulary_)
# 使用此词汇表获取新文本的表示
temp = count_vect.transform(["dog and dog are friends"])
print("Bow representation for 'dog and dog are friends':", temp.toarray())以下是 n-gram 袋表示的主要利弊。
- n-gram 袋以 n-gram 的形式捕捉了一定的语境和语序信息。
- 因此,得到的向量空间能够捕捉一定的语义相似性。具有不同 n-gram 的文档距离更远, 具有相同 n-gram 的文档距离更近。
- 随着 n 的增大,维数(以及稀疏性)将会迅速增加。
- n-gram 袋仍然没有解决未登录词的问题。
2.4TF-IDF
在以上三种方法中,文本中的所有词汇都被视为同等重要——不存在某些词比其他词更重要的概念。
TF-IDF,即词频 – 逆文档频率,解决了这个问题。TF-IDF 的目的是量化给定词相对于文档和语料库中其他词的重要性。
TF-IDF 是信息检索系统中常用的表示方法,用于从语料库中提取所查询的相关文档。
TF-IDF 背后的直觉是,如果词 w 在文档 di 中出现多次,但在语料库的其他文档 dj 中出现的次数不多,那么词 w 对文档 di 一定非常重要。w 的重要性应该与 w 在 di 中的频率成正比;同时,w 的重要性应该与 w 在语料库中其他文档 dj 中的频率成反比。在数学上,这是 使用 TF 和 IDF 两个量来得到的。将两者结合起来可以算出 TF-IDF 分值。
TF(词频)测量的是词在给定文档中出现的频率。由于语料库中的不同文档可能具有不同的长度,因此一个词在较长文档中出现的频率可能高于较短的文档。为了计数的归一化, 将出现的次数除以文档的长度。词 t 在文档 d 中的 TF 定义为:

IDF(逆文档频率)测量的是词在语料库中的重要性。在计算 TF 时,所有词都被赋予同等的重要性(权重)。然而,众所周知的事实是,is、are、am 等停用词并不重要,即使它们 经常出现。为了解释这种情况,IDF 对语料库中非常常见的词降低了权重,并对罕见的词 增加了权重。词 t 的 IDF 计算如下:

TF-IDF 分值是以上两项的乘积。因此,TF-IDF=TF × IDF。下面来计算简易语料库的 TFIDF 分值。有些词只出现在一个文档中,有些出现在两个文档中,而另一些则出现在三个 文档中。语料库的大小是 N=4。因此,每个词的 TF-IDF 值如表 3-2 所示。
表3-2:简易语料库的TF-IDF值

文档的 TF-IDF 向量表示则是该文档中每个词的 TF-IDF 值。因此,对于 D1,得:
| dog | bites | man | eats | meat | food |
|---|---|---|---|---|---|
| 0.136 | 0.17 | 0.136 | 0 | 0 | 0 |
以下代码演示了如何使用 TF-IDF 来表示文本。
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer()
bow_rep_tfidf = tfidf.fit_transform(processed_docs)
print(tfidf.idf_) # 词汇表中所有词的IDF
print(tfidf.get_feature_names()) # 词汇表中所有的词
temp = tfidf.transform(["dog and man are friends"])
print("Tfidf representation for 'dog and man are friends':\n", temp.toarray())实际使用的 TF-IDF 公式与上述基本公式之间有一定的区别。因此,表 3-2 中计算的 TFIDF 值可能与 scikit-learn 给出的 TF-IDF 值不同。这是因为 scikit-learn 使用了稍微不同的 IDF 公式。这是因为要考虑除数为零的情况,并且不能完全忽略那些所有文档中都出现的词。感兴趣的读者可以查看 TF-IDF vectorizer 文档来获得确切的公式。
和词袋类似,TF-IDF 向量也可用于计算两个文本之间的相似度,比如使用欧氏距离或余弦相似度等。TF-IDF 是信息检索和文本分类等应用场景中常用的表示方法。然而,尽管 TFIDF 在捕捉词相似性方面优于之前的向量化方法,但它仍然面临着维数灾难的问题。
即使在今天,TF-IDF 仍然是许多自然语言处理任务的常用表示方法,尤其是 在构建初步解决方案的时候。
回顾前面的讨论,不难发现,所有的表示方法都存在以下三个基本缺陷。
- 它们是离散的表示,也就是说,它们将语言单位(词、n-gram 等)视为基本单位。这种离散性妨碍了它们捕捉词与词之间关系的能力。
- 特征向量是稀疏的高维表示。维数随着词汇表的增大而增加,但向量中的大多数值是零。 这会妨碍学习能力。此外,高维表示还会导致计算效率低下。
- 它们无法处理未登录词的问题。
好,基本的向量化方法就介绍到这里。下面开始讨论分布式表示。
3.分布式表示
上一节讨论了基本向量化方法普遍存在的主要缺点。为了克服这些局限性,人们设计了学习低维表示的方法。本节所述的这些方法在过去六七年中取得了突飞猛进的发展。它们使用神经网络结构来创建稠密、低维的词和文本表示。但是在研究这些方法之前,需要先了解以下关键术语。
-
分布相似性
分布相似性背后的思想是,词的意思可以通过其所在的语境来理解。这也叫内涵 (connotation):词义由语境定义。这与外延(denotation)相反:词义由字面意思定义。 例如,“NLP rocks”。“rocks”的字面意思是“石头”,但从语境来看,此句中“rocks” 是动词,形容某些事物非常棒。
-
分布假说
在语言学中,分布假说(distributional hypothesis)认为:语境相似的词,其语义也相似。例如,英语单词“dog”和“cat”经常出现在相似的语境中,因此,根据分布假说,这两个词一定具有相似的语义。根据向量空间模型,词义由向量表示。因此,如果两个词经常出现在相似的语境中,那么对应的向量表示也肯定是彼此接近的。
-
分布表示
分布表示(distributional representation)是指根据语境中词的分布而获得的表示方法。 分布表示方法基于分布假说。分布的性质是从语境(周围的文本)中归纳出来的。在 数学上,分布表示方法使用高维向量来表示词。这些向量是从词和语境的共现矩阵中获得的,矩阵的维数等于语料库词汇量的大小。前面看到的四种方法——独热、词袋、 n-gram 袋和 TF-IDF——都属于分布表示的范畴。
-
分布式表示
分布式表示(distributed representation)也是一个基于分布假说的相关概念。如前一段所述,分布表示中的向量是非常高维和稀疏的。这使得它们计算效率低下,妨碍了学习。为了应对这种情况,分布式表示方法显著地压缩了维数。这会产生紧凑(即低维) 和稠密(即几乎没有零)的向量。由此产生的向量空间称为分布式表示。本章后面讨论的所有方法都属于分布式表示。
-
嵌入
嵌入(embedding)是将语料库中的词汇从分布表示的向量空间映射到分布式表示的向量空间。
降维?
-
向量语义学
向量语义学(vector semantics)是指根据词在大型语料库中的分布性质来学习词的向量表示的自然语言处理方法。
在对这些术语有了基本的了解之后,现在开始讨论第一种方法:词嵌入。
3.1词嵌入
文本表示应该捕捉“词之间的分布相似性”,这是什么意思?考虑几个例子。
对于“美国”一词,分布相似的词可能是其他国家(如加拿大、德国、印度等)或美国的城市。对于“美丽”一词,与该词有某种关系的词(如同义词、反义词)可以被认为是分布相似的 词。这些词很可能出现在相似的语境中。基于“分布相似性”和神经网络的词表示模型 “Word2vec”可以捕捉到词的类比关系,例如:国王 – 男人 + 女人 ≈ 女王
该模型能够正确回答很多类似的类比问题。图 3-5 显示了某个基于 Word2vec 的类比回答系统的快照。Word2vec 模型在很多方面是现代自然语言处理的鼻祖。
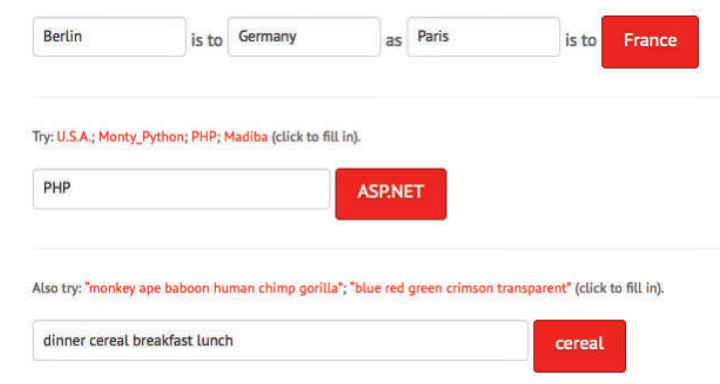
图 3-5:基于 Word2vec 的类比回答系统
除了学习丰富的语义关系,Word2vec 还确保了学习到的词表示是低维的(向量维数为 50~500,而非几千)和稠密的(向量中的大多数值为非零)。低维和稠密的词表示使机器 学习任务更加易于处理和高效。在使用神经网络来学习文本表示的方向上,Word2vec 产生 了大量的理论成果和应用成果。这种表示也叫“嵌入”。那么嵌入是如何工作的?如何使用嵌入来表示文本?下面先来建立直观理解。
给定文本语料库,Word2vec 的目标是学习语料库中每个词的嵌入,使得嵌入空间中的词向量能最好地捕捉词的意义。为了“推导”词的意义,Word2vec 使用分布相似性和分布假说。也就是说,Word2vec 从词的语境(出现在周围的词)中推导出词的意义。因此,如果两个不同的词经常出现在相似的语境中,那么它们的意思很可能也是相似的。
Word2vec 的实现方法是,将词的意义投射到向量空间中,其中具有相似语义的词会趋向于聚集在一 起,而具有不同语义的词则会距离较远。
从概念上讲,Word2vec 以大型文本语料库作为输入,并基于词在语料库中出现的语境, “学习”在公共向量空间中表示词。给定词 w 和语境 C 中的词,如何找到最能表示该词含义的向量?对于语料库中的每个词 w,首先用随机值来初始化向量 vw。然后,Word2vec 模 型会根据语境 C 中的词的向量来预测 vw,从而改善 vw 中的值。
Word2vec 使用两层神经网络来实现这一点。在继续讨论如何训练自己的嵌入之前,先来看看预训练嵌入,借此深入研究这个问题。
3.1.1 预训练词嵌入
训练自己的词嵌入需要耗费大量的时间和计算资源。值得庆幸的是,对于许多场景,通常不需要训练自己的词嵌入,直接使用预训练词嵌入就够了。那什么是预训练词嵌入?有人已经使用大型语料库(例如维基百科、新闻文章,甚至整个互联网)训练好了词嵌入,并把词和对应的向量放在了网上。困难的工作已经完成。下载这些嵌入可以直接获得所需的词向量。预训练词嵌入可以被认为是键 – 值对的大集合,其中键是词汇表中的词,值是对 应的词向量。谷歌的 Word2vec、斯坦福的 GloVe 和 Facebook 的 fastText 词嵌入等都是最常见的预训练词嵌入。此外,它们还提供多种维数选择,如 d = 25, 50, 100, 200, 300, 600。
下面的代码涵盖了关键步骤。这里找到了语义上与“beautiful”一词最相似的词,最后一行返回单词“beautiful”的嵌入向量。
from gensim.models import Word2Vec, KeyedVectors
pretrainedpath = "NLPBookTut/GoogleNews-vectors-negative300.bin"
w2v_model = KeyedVectors.load_word2vec_format(pretrainedpath, binary=True)
print('done loading Word2Vec')
print(len(w2v_model.vocab)) # 词汇表中词的数量
print(w2v_model.most_similar['beautiful'])
W2v_model['beautiful']most_similar('beautiful') 返回与“beautiful”最相似的词,输出如下所示。每个词都附 有相似度分值,分值越高,表示该词与查询词越相似。
[('gorgeous', 0.8353004455566406),
('lovely', 0.810693621635437),
('stunningly_beautiful', 0.7329413890838623),
('breathtakingly_beautiful', 0.7231341004371643),
('wonderful', 0.6854087114334106),
('fabulous', 0.6700063943862915),
('loveliest', 0.6612576246261597),
('prettiest', 0.6595001816749573),
('beatiful', 0.6593326330184937),
('magnificent', 0.6591402292251587)]w2v_model 返回查询词的向量。对于“beautiful”这个词,得到的向量如图 3-6 所示。

图 3-6:预训练 Word2vec 中表示“beautiful”的词向量
注意,如果搜索的词在 Word2vec 模型中不存在(例如,“practicalnlp”),将出现“key not found”错误。因此,作为一种良好的编程实践,建议在尝试检索词向量之前,先检查该词 是否存在于模型的词汇表中。这个代码片段中使用的 Python 库 gensim 还支持训练和加载 GloVe 预训练模型。
如果对词嵌入不熟悉,那么在项目的开始阶段,最好使用预先训练好的词嵌 入。了解它们的优缺点后,再考虑构建自己的嵌入。使用预先训练的嵌入可 以很快为手头任务提供一个强大的基线。
下面来看如何训练自己的词嵌入。
3.1.2训练自己的嵌入
现在着重讨论训练自己的词嵌入。为此,这里先看看 Word2vec 最初提出的两种结构变体。 它们分别是:
- 连续词袋(CBOW)模型;
- 跳词(SkipGram)模型。
两者具有很多相似之处。下面分别介绍 CBOW 模型和 SkipGram 模型。本节将使用“The quick brown fox jumps over the lazy dog”这句话作为简易语料库。
CBOW 模型。
CBOW 的首要任务是构建语言模型,即在给定周围语境词的情况下,正确地预测中心词。
那什么是语言模型?语言模型是一种统计模型,它试图给出词序列的概率分布。 例如,给定一个含有 n 个词的句子,语言模型试图给出整个句子的概率 Pr(w1 , w2 , …, wn )。 语言模型的目标是给“好句子”分配高概率,给“坏句子”分配低概率。所谓“好句子”, 指的是语义和句法都正确的句子。所谓“坏句子”,指的是语义或句法不正确的句子。因此,对于像“The cat jumped over the dog”这样的句子,语言模型会尝试分配一个接近于 1.0 的概率,而对于像“jumped over the the cat dog”这样的句子,语言模型会尝试分配一 个接近于 0.0 的概率。
CBOW 试图学习一种根据语境词来预测“中心词”的语言模型。下面使用简易语料库来理 解这一点。如果把“jumps”这个词作为中心词,那么它的语境就由它附近的词构成。如果语境大小k取 2,那么上述示例的语境就是 brown、fox、over 和 the。CBOW 使用语境词来预测目标词 jumps,如图 3-7 所示。CBOW 尝试对语料库中的每个词都做这样的处理, 也就是说,CBOW 把语料库中的每一个词都当作目标词,并试图根据对应的语境词来预测目标词。
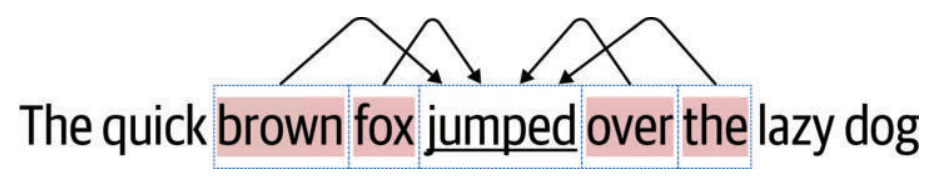
图 3-7:CBOW:给定语境词,预测中心词
将上述思想扩展到整个语料库,以构建训练集。具体而言,就是在文本语料库上运行大小 为 2k+1 的滑动窗口。在刚才的例子中,k取值为 2。窗口中的每个位置构成了当前正在考 虑的 2k+1 个词的集合。窗口中的中心词是目标词,中心词两侧的 2k 个词构成了语境。这是一个数据点。如果数据点表示为 (X, Y),则语境为 X,目标词为 Y。每个数据点由一组 数字组成:(2k 个语境词的索引 , 1 个目标词的索引 )。为了得到下一个数据点,只需将语 料库上的窗口向右移动一个词,然后重复这个过程。这样,在整个语料库上滑动窗口就可以创建出训练集,如图 3-8 所示,其中目标词用蓝色表示,k=2。

图 3-8:为 CBOW 准备数据集
现在训练数据已经准备好了,接下来构建模型。这里构建的是一个浅层网络(之所以是浅 层,是因为只有一个隐藏层),如图 3-9 所示。假设要学习的是 D 维词嵌入。令 V 为文本 语料库的词汇表。
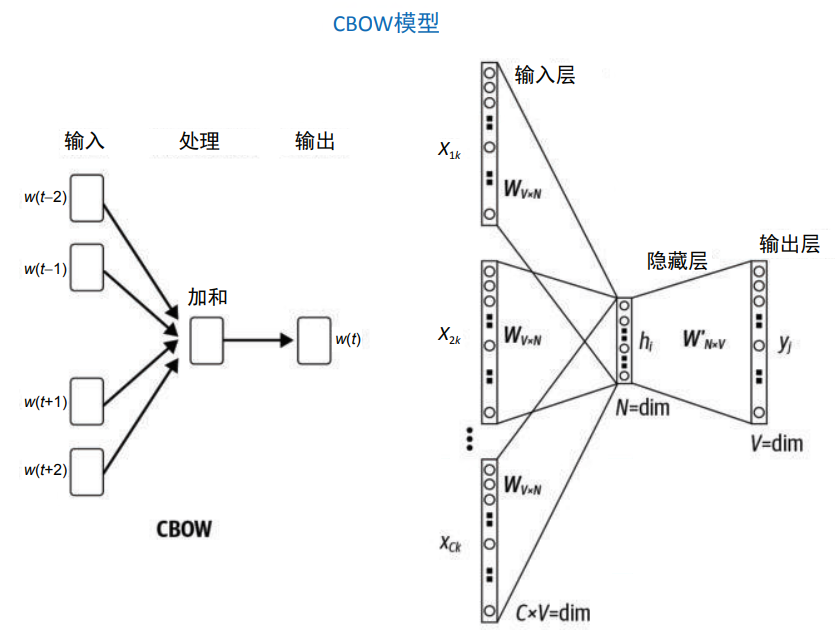
图 3-9:CBOW 模型
建模的目标是学习嵌入矩阵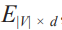 ,其中 |V| 是语料库词汇表的大小,d 是词嵌入的维数。 首先,需要将嵌入矩阵随机初始化。接下来看一下图 3-9 中所示的浅层网络。在输入层中, 使用语境词的索引从嵌入矩阵
,其中 |V| 是语料库词汇表的大小,d 是词嵌入的维数。 首先,需要将嵌入矩阵随机初始化。接下来看一下图 3-9 中所示的浅层网络。在输入层中, 使用语境词的索引从嵌入矩阵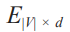 中获取相应的行,再将获取的向量相加,得到一个 d 维向量,并将其传递到下一层。下一层直接将 d 维向量与矩阵
中获取相应的行,再将获取的向量相加,得到一个 d 维向量,并将其传递到下一层。下一层直接将 d 维向量与矩阵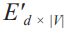 相乘,得到 1× |V|的向量,送入 softmax 函数后,得到它在词汇表空间上的概率分布。然后将该分布与标签进 行比较,并使用反向传播来相应地更新矩阵 E 和 E'。在训练结束时,E 就是学习到的嵌入矩阵(从技术上讲,E 和 E' 是两个不同的嵌入矩阵。可以使用其中的任何一个,也可以直接求平均,将两 者合二为一)。
相乘,得到 1× |V|的向量,送入 softmax 函数后,得到它在词汇表空间上的概率分布。然后将该分布与标签进 行比较,并使用反向传播来相应地更新矩阵 E 和 E'。在训练结束时,E 就是学习到的嵌入矩阵(从技术上讲,E 和 E' 是两个不同的嵌入矩阵。可以使用其中的任何一个,也可以直接求平均,将两 者合二为一)。
SkipGram 模型。SkipGram 与 CBOW 非常相似,只是有一些细微的变化。在 SkipGram 中,模型的任务是根据中心词来预测语境词。对于刚才的简易语料库,如果语境大小为 2, 则使用中心词“jumps”来预测各个语境词——“brown”“fox”“over”“the”,如图 3-10 所示。这构成流程中的一步。SkipGram 会以语料库中的每个词为中心词重复这一步。

图 3-10:SkipGram:给定中心词,预测各个语境词
训练 SkipGram 的数据集按如下方式准备:在文本语料库上运行大小为 2k+1 的滑动窗口, 获得当前正在考虑的 2k+1 个词的集合。窗口中的中心词是 X,中心词两边的 2k 个词是 Y。 与 CBOW 不同,这里提供了 2k 个数据点。每个数据点由一对数字组成:( 中心词索引 , 目标词索引 )。然后将语料库上的窗口向右移动一个词,重复这个过程。这样,在整个语 料库上滑动窗口就可以创建出训练集,如图 3-11 所示。

图 3-11:为 SkipGram 准备数据集
如图 3-12 所示,训练 SkipGram 模型所用的浅层网络,与 CBOW 所用的网络非常相似, 只是有一些细微的变化。在输入层中,利用目标词的索引从嵌入矩阵 E|V| × d 中获取相应 的行。获取的向量随后被传入下一层。下一层直接将 d 维向量与矩阵 E'd × |V| 相乘,得到 1×|V| 的向量,输入 softmax 函数后,得到它在词汇表空间上的概率分布。将该分布与标 签进行比较,并使用反向传播来相应地更新矩阵 E 和 E'。在训练结束时,E 就是所要学习 的嵌入矩阵。
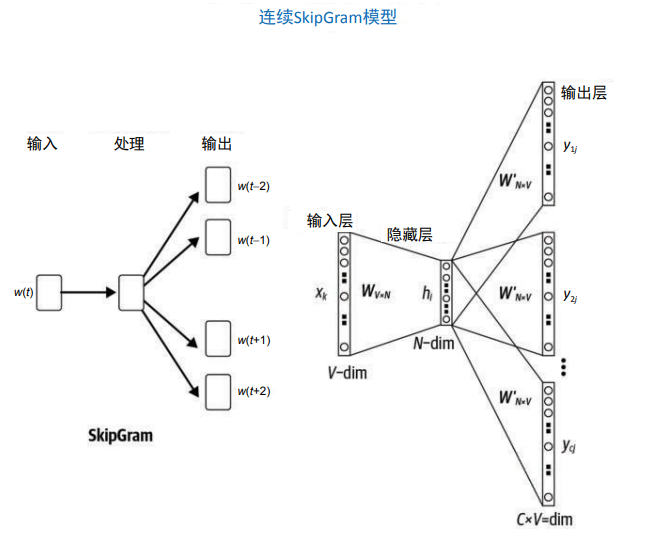
图 3-12:SkipGram 结构
CBOW 和 SkipGram 模型还有许多其他细节。感兴趣的读者可以参考 Xin Rong 的文章 “word2vec Parameter Learning Explained”,其中有对 Word2vec 参数的详细推导。另一个需 要牢记的要点是模型的超参数,例如窗口大小、向量维数、学习率、轮数(epoch)等。众 所周知,超参数对模型的最终质量起着至关重要的作用。 要在实践中使用 CBOW 和 SkipGram 算法,可以使用现成的库,它们抽象了其中的数学细 节。最常用的库是 gensim。 尽管有现成的库可以使用,但仍然需要对超参数(即训练之前需要设置的变量)进行设 置。下面来看两个例子。
-
词向量的维数
词向量的维数决定了嵌入空间的维数。虽然维数不存在一个理想的数字,但通常会构造维数在 50 和 500 之间的词向量,并在任务中对它们进行评估,以选择最佳维数。
-
语境窗口
学习向量表示所需的语境的长度。
另外,在学习词嵌入时,还会面临其他选择,例如究竟是使用 CBOW 还是 SkipGram。在 这一点上,这种选择更像是一门艺术,而非科学。而且,关于选择正确超参数的方法,有很多研究仍在进行当中。
从代码的角度来看,使用 gensim 等包可以非常容易地实现 Word2vec。下面的代码展示了如何使用gensim 中提供的 common_texts 简易语料库来训练自己的 Word2vec 模型。如果使用自己领域的语料库,沿用下面的代码片段也能很快地得到自己的词嵌入。
# 导入gensim中提供的测试数据集来训练模型
from gensim.test.utils import common_texts
# 选择参数,并构建模型
our_model = Word2Vec(common_texts, size=10, window=5, min_count=1, workers=4)
# 保存模型
our_model.save("tempmodel.w2v")
# 检查模型:找出与测试词最相似的词
print(our_model.wv.most_similar('computer', topn=5))
# 看看computer的10维向量是什么样子的
print(our_model['computer'])现在,只需在模型中查找一下,就可以得到语料库中任何词的向量表示,前提是该词存在 于模型的词汇表中。但是如何得到一个短语(例如“word embeddings”)的向量呢?
3.2词语之上
前面展示了使用预训练词嵌入,以及训练自己的词嵌入的例子。最后得到的是紧凑和稠密的词表示。然而,大多数自然语言处理应用程序不会直接处理词这种基本单元,它们处理的是句子、段落,甚至是全文。因此,需要一种方法来表示更大的文本单元。那么能否使用词嵌入来获取更大文本单元的特征表示呢?
一种简单的方法是将文本分解成词,取每个词的嵌入,并将它们组合起来形成文本的表 示。组合的方法有很多,最常见的是求和、取平均值等。虽然这些方法可能无法捕捉词序等文本的整体特征,但令人惊讶的是,这些方法在实践中效果非常好(见第 4 章)。事实 上,在 CBOW 中,对语境词向量求和已经证明了这一点。得到的向量表示整个语境,可以用来预测中心词。
在选择其他表示之前,最好先对上述方法进行实验。下面的代码展示了如何使用 spaCy 库 来对词向量求平均,从而获得文本的向量表示。
import spacy
import en_core_web_sm
# 加载spaCy模型。这需要几秒钟
nlp = en_core_web_sm.load()
# 使用模型处理句子
doc = nlp("Canada is a large country")
# 获取单个词的向量
#print(doc[0].vector) # 文本中第一个词Canada的向量
print(doc.vector) # 整个句子的平均向量预训练和自训练的词嵌入都依赖于它们在训练数据中看到的词汇。但是,应用程序的生产 数据不可能只出现这些词汇。尽管使用 Word2vec 等词嵌入可以很容易地从文本中提取特征,但是处理未登录词还没有比较好的方法。到目前为止,在上文所述的所有表示中,未登录词是一个反复出现的问题。怎么办?
一种简单有效的方法是在特征提取过程中排除这些未登录词,这样就不必担心如何获得未登录词的表示。如果使用的模型是用大型语料库训练的,那么应该不会出现太多的未登录 词。但是,如果生产数据中出现了大量未登录词,那么就不可能有好的性能。这种词汇重 叠度是衡量自然语言处理模型性能的一个有效方法。
如果语料库和词嵌入的词汇重叠度低于 80%,那么自然语言处理模型的性能 就可能不是很好。
即使重叠度超过 80%,模型效果可能仍然很差,这取决于哪些词处于这 20% 的范围中。如 果这些词对于任务很重要,那么模型效果很可能较差。例如,在癌症医疗文档和心脏病医 疗文档的分类任务中,心脏病、癌症等词对于区分这两种文档非常重要。如果这些词没有 出现在词嵌入的词汇表中,分类器效果就可能较差。
另一种处理词嵌入未登录词问题的方法是创建随机初始化的向量,其中每个分量在 –0.25 和 +0.25 之间,并在构建的整个应用程序中一直使用这些向量。根据经验,这可以使性能 提高 1%~2%。
此外,在训练时引入字符、子词等语言成分,也可以处理未登录词问题。下面来看其中的 一种方法。其关键思想是,使用词法属性(如前缀、后缀、词尾)等子词信息,或使用字 符表示来处理未登录词问题。Facebook 人工智能研究院的 fastText 就是使用这种方法的常 见算法之一。一个词可以用它的字符 n-gram 来表示。fastText 采用类似于 Word2vec 的结 构,同时学习词和字符 n-gram 的嵌入,并将词嵌入向量视为其字符 n-gram 的聚合。如此 一来,即使词汇表中不存在的词,也可以生成嵌入。例如,“gregarious”如果在嵌入的词 汇表中不存在,就可以将该词分解成字符 n-gram——gre, reg, ega, ..., ous——并将这些字符 n-gram 的嵌入结合起来,就得到了“gregarious”的嵌入。
gensim 的 fastText 包装器可以用于加载预训练模型,也可以使用 fastText 以类似于 Word2vec 的方式训练模型。这留给读者作为练习。第 4 章将介绍如何使用 fastText 嵌入进行文本分 类。现在来看词语之上的分布式表示。
4.词和字符之上的分布式表示
前面介绍了使用嵌入来实现文本表示的两种方法。Word2vec 学习的是词的表示,词表示经过聚合后形成文本表示。fastText 学习的是字符 n-gram 的表示,字符 n-gram 表示经过 聚合后形成词表示,进而形成文本表示。这两种方法的一个潜在问题是没有考虑到词的语 境。以“狗咬人”(dog bites man)和“人咬狗”(man bites dog)这两个句子为例,在上述 两种方法中,它们得到了相同的表示,但它们显然具有不同的含义。现在来看另一种方法 Doc2vec,它通过考虑文本中词的语境来直接学习任意长度文本(短语、句子、段落和文 档)的表示。
Doc2vec 基于段落向量框架,在 gensim 中已经实现。Doc2vec 的基本结构和 Word2vec 类 似,不同的是,Doc2vec 不仅学习词向量,还要学习“段落向量”来表示整个文本(即通过 语境中的词)。在使用大型语料库(拥有很多文本)进行学习时,段落向量对于给定的文本 (“文本”可以指任意长度的文本)是唯一的,而词向量在所有文本之间共享。学习 Doc2vec 嵌入所用的浅层神经网络(见图 3-13)与 Word2vec 的 CBOW 和 SkipGram 结构非常相似。 这两种结构分别叫分布式存储(DM)和分布式词袋(DBOW),如图 3-13 所示。
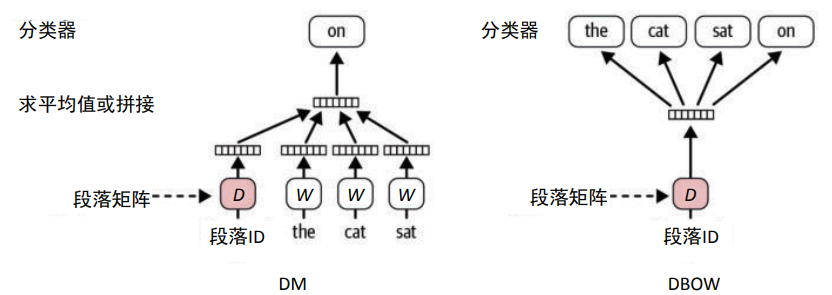
图 3-13:Doc2vec 结构:DM(左)和 DBOW(右)
Doc2vec 模型训练好后,利用训练得到的公共词向量来推断新文本的段落向量。Doc2vec 也许是第一个不直接通过词向量的组合而获得全文嵌入表示的常见方法。由于 Doc2vec 对 语境进行了一定程度的建模,并且可将任意长度的文本编码为固定长度的低维稠密向量, 因此它在文本分类、文档标记、文本推荐和常见问题聊天机器人等自然语言处理应用程序 中得到了广泛的应用。第 4 章将展示如何训练 Doc2vec 表示并将其用于文本分类的示例。 下面继续讨论涉及全文的文本表示方法。
5.通用文本表示
在前面介绍的所有表示中,每一个词都对应一个固定的表示。这有没有问题?在某种程 度上会有问题。词在不同的语境中可能有不同的意思。例如,“I went to a bank to withdraw money”和“I sat by the river bank and pondered about text representations”这两个句子都使 用了“bank”一词,但它们在句子中的意思是不同的。前面介绍的向量方法和嵌入方法都无法直接捕捉这方面的信息。
2018 年,研究人员提出了语境化词表示(contextual word representation)的思想,解决了这一问题。语境化词表示使用“语言建模”,即预测词序列中下一个词的任务。在最早的 形式中,语境化词表示使用 n-gram 频率来估计给定历史词后下一个词的概率。在过去的几 年中,出现了高级的神经语言模型(例如 Transformer),它们利用了前面讨论过的词嵌入, 但使用了复杂的网络结构,包括多次通过文本,以及从左到右和从右到左的多次读取,从 而对语言使用的语境进行建模。
人们使用循环神经网络(RNN)和 Transformer 等神经网络来开发大规模语言模型(例如 ELMo 和 BERT),然后使用这些大规模语言模型作为预训练模型来生成文本表示。这里的 核心思想是利用“迁移学习”,即在大规模语料库中学习语言模型等通用任务的嵌入,然后在特定任务的数据上进行微调学习。这些模型在问题回答、语义角色标注、命名实体识 别和共指消解等基本的自然语言处理任务上都有了显著的改进。第 1 章简要介绍了其中的 一些任务。
前面三节介绍了词嵌入背后的核心思想、训练方法,以及如何使用预训练的词嵌入来获得 文本表示。后面的内容还将进一步介绍如何在不同的自然语言处理应用程序中使用这些表 示。这些表示在现代自然语言处理中非常有用和流行。然而,根据我们的经验,在项目中 使用这些表示时,需要牢记以下几个要点。
- 所有的文本表示都是基于训练数据的,因此会存在固有偏见。例如,用科技新闻或文章 训练的嵌入模型很可能会认为“Apple”更接近微软或 Facebook,而不是橘子或梨。虽 然这不一定是真的,但这种来自训练数据的偏见可能会对依赖于这些表示的自然语言处 理模型以及系统的性能产生严重影响。因此,理解所学嵌入中可能存在的偏见,并开发 相应的解决方法是非常重要的。在开发任何自然语言处理软件的过程中,这些偏见都是 需要考虑的重要因素。
- 不同于基本的向量化方法,预训练的嵌入通常是大型文件(GB 级),这可能会带来一 定的部署问题。因此,需要解决这样的问题,否则它会成为性能上的一个工程瓶颈。 Word2vec 模型大约占用 4.5GB 的内存。一个很好的方法是使用 Redis 这样的内存数据库, 其中的缓存可以解决扩展和延迟的问题。因此,可将嵌入加载到这样的数据库中,并像 在内存中一样使用嵌入。
- 真实应用程序的语言任务不仅仅是使用词嵌入和句子嵌入来捕获信息。仍然需要一些方 法来编码文本的特定属性、句子之间的关系,以及嵌入表示本身可能无法解决的任何其 他特定于领域和应用程序的需求。例如,讽刺语检测任务需要细腻的语言信息,嵌入技 术目前尚不能很好地捕捉。
- 正如前文所说,神经文本表示是自然语言处理中一个不断发展的领域,其技术发展正在 突飞猛进。虽然新闻中的下一个大模型很容易让人忘乎所以,但从业者在尝试将其用于 生产级应用程序之前,需要谨慎行事,并考虑投资回报率、业务需求和基础设施限制等 实际问题。
感兴趣的读者可以参考 Noah A. Smith 的文章“Contextual Word Representations: A Contextual Introduction”,它简要总结了词表示的演变和神经网络文本表示模型的研究挑战。接下来开 始讨论嵌入的可视化技术。
6.可视化嵌入
上面介绍了文本表示的各种向量化技术。得到的向量可以用作文本分类、问答系统等自然 语言处理任务的特征。而对特征进行探索是任何机器学习项目的重要环节。那么如何探索 这些必须使用的向量?任何与数据相关的问题通常都会涉及可视化探索。有没有一种方法 可以对词向量进行可视化?虽然嵌入向量已经是低维向量,但仍然具有 100~300 维,维数 还是太高,无法进行可视化。
t-SNE,全称 t 分布随机邻域嵌入(t-distributed Stochastic Neighboring Embedding),是一 种通过将高维数据(如嵌入)简化为二维或三维数据来实现可视化的技术。t-SNE 以嵌入 (或任何其他数据)为输入,并使用较少的维度来最好地表示输入数据,同时在原始高维 输入空间和低维输出空间中保持相同的数据分布。因此,这使得输入数据的绘制和可视化 成为可能。t-SNE 有助于对词嵌入空间有一个直观的感受。
下面来看使用 t-SNE 进行可视化的一些例子。先来看 MNIST 数字数据集特征向量的可视 化。在这里,MNIST 数字图像通过卷积神经网络后形成最终的特征向量。图 3-14 显示了 向量的二维绘图。它清楚地表明,这些特征向量的效果是很好的,因为同一类别的向量集中在一起。

图 3-14:使用 t-SNE 可视化 MNIST 数据(参见 Cyril Rossant 的文章“An illustrated introduction to the t-SNE algorithm”
现在来看词嵌入的可视化。虽然图 3-15 中只显示了几个词,但有趣的是,意思相似的词往 往会集中在一起。
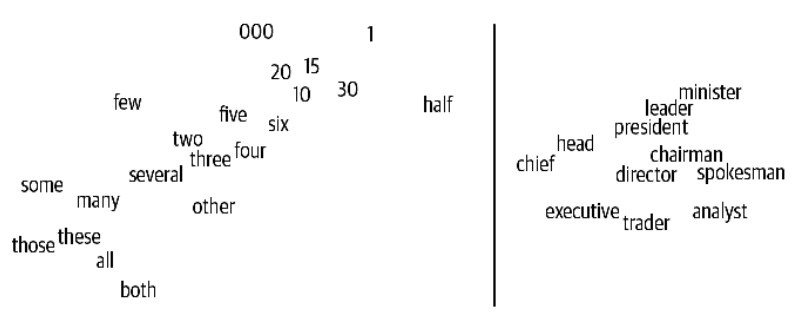
图 3-15:词嵌入的 t-SNE 可视化(左:数字;右:职务)
再看一个词嵌入的可视化,它可能是自然语言处理界最著名的例子。图 3-16 显示了一组词 (男人、女人、叔叔、阿姨、国王、皇后)的嵌入向量的二维可视化。图 3-16 不仅显示了 这些词向量的位置,还显示了向量之间的一个有趣现象——箭头捕捉了词之间的“关系”。 使用 t-SNE 可视化非常有助于人们观察到这类现象。
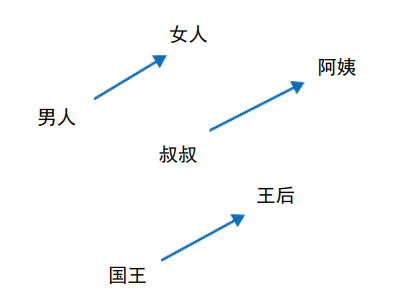
图 3-16:t-SNE 可视化显示了一些有趣的关系
t-SNE 同样适用于文档嵌入的可视化。例如,获取维基百科上不同主题的文章,获得每篇 文章对应的文档向量,然后使用 t-SNE 绘制这些向量。图 3-17 中的可视化清楚地显示了同 一类别的文章会分在同一组。
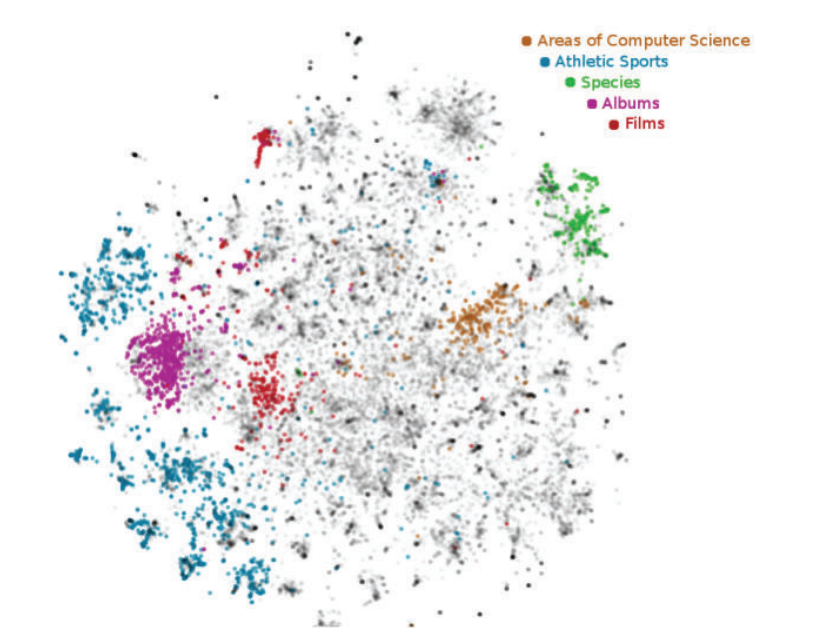
图 3-17:维基百科文档向量的可视化
显然,t-SNE 对于观察特征向量的质量非常有用。可以使用 TensorBoard 中的嵌入投影仪等 工具来可视化日常工作中的嵌入。如图 3-18 所示,TensorBoard 有一个很好的界面,专门 为可视化嵌入而定制。这里把它作为练习留给读者进一步探索。
图 3-18:用于嵌入可视化的 TensorBoard 界面截图
7.人工特征表示
前面已经介绍了各种基于文本语料库的特征表示方法。这些特征表示大都不依赖于特定 的自然语言处理问题或应用领域(除非已经针对手头的任务进行了微调)。无论文本表示用于信息提取还是文本分类,也无论使用 Twitter 语料库还是科技文章语料库,都可以使用相同的方法。
然而,在许多情况下,对于给定的自然语言处理问题,一些特定于领域的知识确实是存在 的。如果希望将这些知识融入构建的模型当中,就需要使用人工特征。下面以真实的自然 语言处理系统 TextEvaluator 为例。TextEvaluator 是美国教育考试服务中心(ETS)开发的 软件。该工具的目的是帮助教师和教育工作者为学生选择相应年级的阅读材料,并找到 文本理解困难的原因。显然,这是一个非常专门的问题。使用通用的词嵌入不会有多大帮 助。它需要从文本中提取专门的特征来对某种形式的年级适当性进行建模。图 3-19 中的屏 幕截图显示了从文本中提取的一些专门特征,从而对文本复杂度的各个维度进行建模。显 然,只将文本转换为词袋表示或嵌入表示是不能计算句法复杂性(syntactic complexity)、 具体性(concreteness)等指标的。它们必须结合领域知识和机器学习算法来人工设计,从 而训练自然语言处理模型。这就是它被称为人工特征表示的原因。

图 3-19:TextEvaluator 软件输出需要人工特征
ETS 的另一个很受欢迎的评分软件是自动作文评分系统,它用于评估 GRE、托福等在线考 试考生的作文。这个工具也需要人工特征。对一篇文章的各个方面进行评估需要专门的特 征来满足这些需求。仅仅依靠 n-gram 或词嵌入是不够的。另外,微软 Word、Grammarly 等工具中使用的拼写和语法纠正功能,可能也需要这种专门的特征工程。在所有这些常用 工具的例子中,通常需要自定义特征来融合领域知识。
显然,自定义特征工程比其他特征工程方法要难得多。正是由于这个原因,向量化方法更 容易上手,特别是在对专业领域没有足够了解的情况下。尽管如此,在一些真实的应用中,人工特征还是非常常见的。在大多数工业应用场景中,人们会将通用的特征表示(基本向 量化表示和分布式表示)与特定于领域的特征相结合,由此来开发混合特征。IBM 研究院 和沃尔玛最近的研究展示了在真实的行业系统中综合使用启发式、人工特征和机器学习来 解决自然语言处理问题的例子。接下来的内容(例如第 4 章、第 5 章)还会涉及使用人工 特征的例子。
8.小结
本章详细介绍了文本表示的不同技术,既包括基本的向量化方法,也包括先进的深度学习 方法。这时自然会出现一个问题:什么时候应该使用向量化特征和嵌入,什么时候应该使 用人工特征?答案取决于手头的任务。对于某些应用,例如文本分类,更常见的是直接将 向量化方法和嵌入作为文本的特征表示。对于其他一些应用,例如信息提取,或者上一节 出现的示例,更常见的是使用特定于领域的人工特征。但在实践中,人们常常会使用结合 这两种特征的混合方法。尽管如此,向量化方法仍然是一个很好的起点。 希望本章的各种讨论和观点能让你很好地理解文本表示在自然语言处理中的作用、文本表 示的不同技术,以及它们各自的优缺点。接下来的内容(第 4~7 章)将继续解决自然语言 处理的基本任务,它们将使用不同的文本表示。