
停用词(Stop Words)是指在自然语言处理(NLP)或信息检索中,因出现频率极高、语义贡献低而被自动过滤的词汇。其核心目的是节省存储空间、提升处理效率,并减少语义干扰。以下是详细解析:
📚 一、停用词的定义与作用
-
核心特点
- 高频率低信息量:如中文的“的”“了”“在”,英文的“the”“is”“and”等,在文本中频繁出现但很少携带核心语义。
- 语言依赖性:不同语言需定制专属停用词表(如中文虚词、英文冠词)。
- 功能词为主:包括助词、介词、连词、语气词等语法连接词。
-
主要作用
- 降噪提效:过滤冗余词汇,提升文本分析(如情感分析、主题建模)的准确性。
- 优化存储:减少索引体积,加速搜索引擎响应。
🇨🇳 二、中文典型停用词示例
中文停用词以虚词和常用代词为主,典型类别包括:
| 类别 | 示例词汇 |
|---|---|
| 助词 | 的、了、着、过、呢、啊、吧 |
| 介词 | 在、从、向、以、于、对、关于 |
| 连词 | 和、与、及、或、但、而、因此 |
| 代词 | 我、你、他、这、那、哪、什么 |
| 副词 | 就、也、都、很、非常、太、更 |
| 数量词 | 一、个、些、所有、任何 |
✅ 常用停用词表来源:
- 通用库:
jieba(内置哈工大停用词表)、sklearn的ENGLISH_STOP_WORDS。- 自定义场景:需结合领域添加词汇(如医疗文本需过滤“患者”“治疗”等高频非关键名词)。
⚙️ 三、实际应用场景与注意事项
-
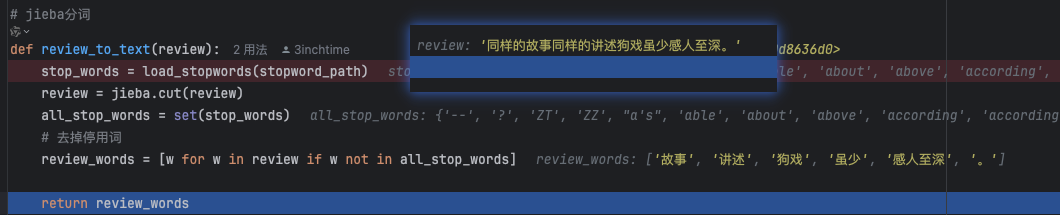
处理流程示例(Python)
import jieba from nltk.corpus import stopwords # 中文停用词过滤 stopwords_cn = set(open("stopwords.txt", encoding="utf-8").read().splitlines()) # 加载自定义词表 text_cn = "我喜欢在周末去公园散步,享受大自然的宁静。" words_cn = [word for word in jieba.lcut(text_cn) if word not in stopwords_cn] # 输出:['喜欢', '周末', '公园', '散步', ',', '享受', '大自然', '宁静', '。'] # 英文停用词过滤 stopwords_en = set(stopwords.words('english')) text_en = "The quick brown fox jumps over the lazy dog." words_en = [word for word in text_en.split() if word.lower() not in stopwords_en] # 输出:['quick', 'brown', 'fox', 'jumps', 'lazy', 'dog.'] -
注意事项
- 避免过度过滤:特定场景需保留功能词(如搜索短语“Take That”中的“The”)。
- 领域适应性:法律/医疗文本需定制词表(如保留“法条”“诊断”等关键术语)。
- 动态更新:网络新词(如“绝绝子”)可能需加入停用词表。
💎 总结
停用词是NLP预处理的核心环节,中文典型停用词以虚词、代词、高频副词为主。实际应用中需结合领域需求动态调整词表,平衡过滤效率与语义完整性。推荐优先使用权威词表(如哈工大、百度停用词库),并通过代码工具(jieba/NLTK)快速集成。