
1.概述
在日常生活中,我们可能会碰到各种各样的自然语言处理应用程序。上一章已经介绍了一些常见的例子。那么一个自然语言处理应用程序应该如何构建?通常,我们会遍历需求并将问题分解成若干子问题,然后尝试开发一个过程,逐步解决这些子问题。由于涉及语言处理,因此还要列出每一步所需的各种文本处理。这种分步骤处理文本的过程叫流水线(pipeline)。流水线是构建自然语言处理模型所涉及的一系列步骤。这些步骤在每个自然语言处理项目中都很常见,因此通过本章来研究它们是理所当然的。理解自然语言处理流水线中的一些常见步骤后,就可以开始处理工作场所中遇到的自然语言处理问题了。设计和开发文本处理流水线被视为任何自然语言处理应用程序开发的起点。本章将介绍各种相关步骤,以及它们在解决自然语言处理问题中的重要作用。关于使用哪个步骤、何时使用、如何使用,本章也会提供一些指南。后面的内容还将讨论各种自然语言处理任务的特定流水线(例如第 4~7 章)。
数据驱动的现代自然语言处理系统在开发中使用了通用的流水线。图 2-1 显示了其中的主要组件。流水线中的关键阶段列举如下:
- 数据获取;
- 文本清洗;
- 预处理;
- 特征工程;
- 建模;
- 评估;
- 部署;
- 监控和模型更新。
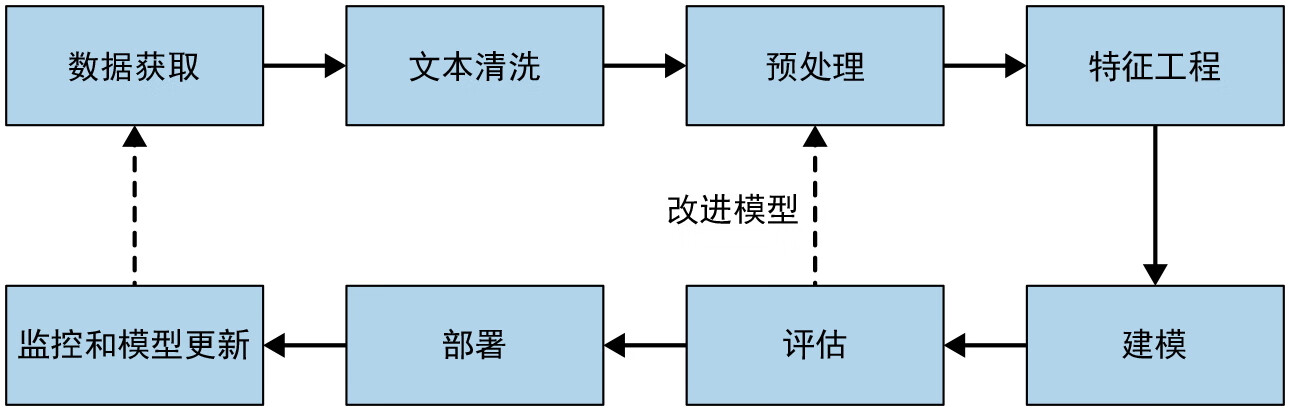
图 2-1:自然语言处理的通用流水线
开发任何自然语言处理系统的第一步是收集给定任务的相关数据。即使构建一个基于规则的系统,也仍然需要一些数据来设计和测试规则。由于获得的数据很少是干净数据,因此需要进行文本清洗。经过清洗后,文本数据往往具有很多不同的形式,因此需要将其转换成规范形式。这是在预处理这一步中完成的。接下来是特征工程,其目的是精心设计出最能表征当前任务的若干指标,并将这些指标转换成建模算法可以理解的格式。然后是建模和评估阶段,即构建一个或多个模型,并采用相关的评估方法对它们进行比较。一旦从中选择了最佳模型,就可以开始在生产中部署该模型。最后一步是定期监控模型的性能,并在需要时更新模型以保持其性能。
注意,在现实世界中,这个过程可能并不总像图 2-1 中所示的流水线那样一帆风顺——它经常会在各个步骤之间,例如在特征提取和建模之间,在建模和评估之间等出现来回反复。而且,步骤之间可能还有循环,最常见的循环是从评估到预处理、特征工程、建模,再回到评估的循环。此外,在项目这个级别上,还会出现从监控回到数据获取的整体循环。
注意,具体采取什么样的步骤可能取决于当前的具体任务。例如,文本分类系统需要的特征提取步骤可能不同于文本摘要系统。本书的后续内容将关注特定于应用的流水线阶段。此外,不同的步骤可能需要不同的时间,这取决于项目所处的阶段。在初始阶段,大部分时间会用于建模和评估,而一旦系统成熟,特征工程就会花费更多的时间。
本章接下来将结合示例,详细介绍流水线的各个阶段,描述每个阶段的一些常见步骤,并讨论一些用例来说明它们。现在开始第一步:数据获取。
2.数据获取
数据是机器学习系统的核心。在大多数行业项目中,成为瓶颈的往往是数据。本节将讨论自然语言处理项目中收集相关数据的各种策略。
假如现在要开发一个自然语言处理系统,它能识别传入的客户查询(比如通过聊天界面)是销售查询还是客服查询,并根据查询的类型,自动将其发送到对应的团队。怎样才能构建这样一个系统呢?答案取决于数据的类型和数量。
在理想的情况下,所需的数据集拥有成千上万个数据点。在这种情况下,我们不必担心数据获取的问题。例如,在刚才描述的场景中,不仅有来自前几年的历史性查询,而且销售团队和支持团队还将这些查询标注为“销售”“支持”或“其他”类别。因此,我们不仅有数据,还有标注。然而,在很多人工智能项目中,我们就没有那么幸运了。那么在不太理想的场景中,我们可以做些什么?下面来看一看。
如果只有很少的数据或者没有数据,可以先看一看数据中是否存在某些模式,表明传入的消息是销售查询还是支持查询。然后使用正则表达式和其他启发式来匹配这些模式,从而将销售查询和支持查询分开。接下来是评估这一方案,方法是从两个类别中收集一组查询并计算消息被系统正确识别的百分比。结果可能还凑合。我们希望提高系统性能。
现在可以开始考虑使用自然语言处理技术了。为此,我们需要标注好的数据,也就是查询集合中的每个查询都被标注为“销售”或“支持”。那么怎样才能得到这样的数据?
使用公开数据集
可以看看是否有可以利用的公开数据集。如果找到了与手头任务相似的合适数据集,那么太好了!下一步就是构建模型并进行评估。如果没有,那么接下来该怎么办?
抓取数据
可以在互联网上找到相关数据的来源,例如发布了销售或支持查询的消费者论坛或产品页面讨论区。从那里抓取数据,然后进行人工标注。
对于许多行业场景,从外部来源收集数据是不够的,因为外部数据不包含产品名称或特定于产品的用户行为等细微信息,因此可能与生产环境中看到的数据非常不同。这就需要在组织内部寻找数据。
产品干预
在大多数行业场景中,人工智能模型很少是单独存在的。它们主要通过某项功能或某个产品为用户提供服务。在这种情况下,人工智能团队应该与产品团队合作,开发更好的产品监测指标来收集更多、更丰富的数据。在科技界,这叫产品干预。
在行业场景中构建智能应用程序,产品干预通常是收集数据的最佳方式。谷歌、Facebook、微软、Netflix 等科技巨头早就深谙此道,并努力从尽可能多的用户那里收集尽可能多的数据。
数据增强
虽然监测产品是收集数据的好方法,但这需要时间。即使从现在开始监测产品,那也要等 3~6 个月才能收集到一个规模庞大、内容丰富的数据集。那么在此期间,我们可以做些什么?
可以在小数据集上使用某些技巧来创建更多的数据。这些技巧也叫数据增强。数据增强试图利用语言特性,来生成句法相似的文本。数据增强可能看起来像是在篡改数据,但在实践中效果很好。自然语言处理中有很多数据增强的技术。下面来看看其中的一些。
同义词替换
在句子中随机选择 k 个非停用词,然后用同义词进行替换。可以使用 WordNet 的 Synsets 来获取同义词。
回译
假设有一个英语句子 S1。使用谷歌翻译等机器翻译库把它翻译成其他语言,比如德语。令对应的德语句子为 S2。现在,再次使用机器翻译库,将 S2 翻译回英语,令输出句子为 S3。
不难发现,S1 和 S3 意思非常接近,但又稍有不同。现在可以把 S3 添加到数据集中。这个技巧非常适合文本分类。图 2-2(参见 Qizhe Xie、Zihang Dai、Eduard Hovy 等人的文章“Unsupervised Data Augmentation for Consistency Training”)显示了回译的一个实例。
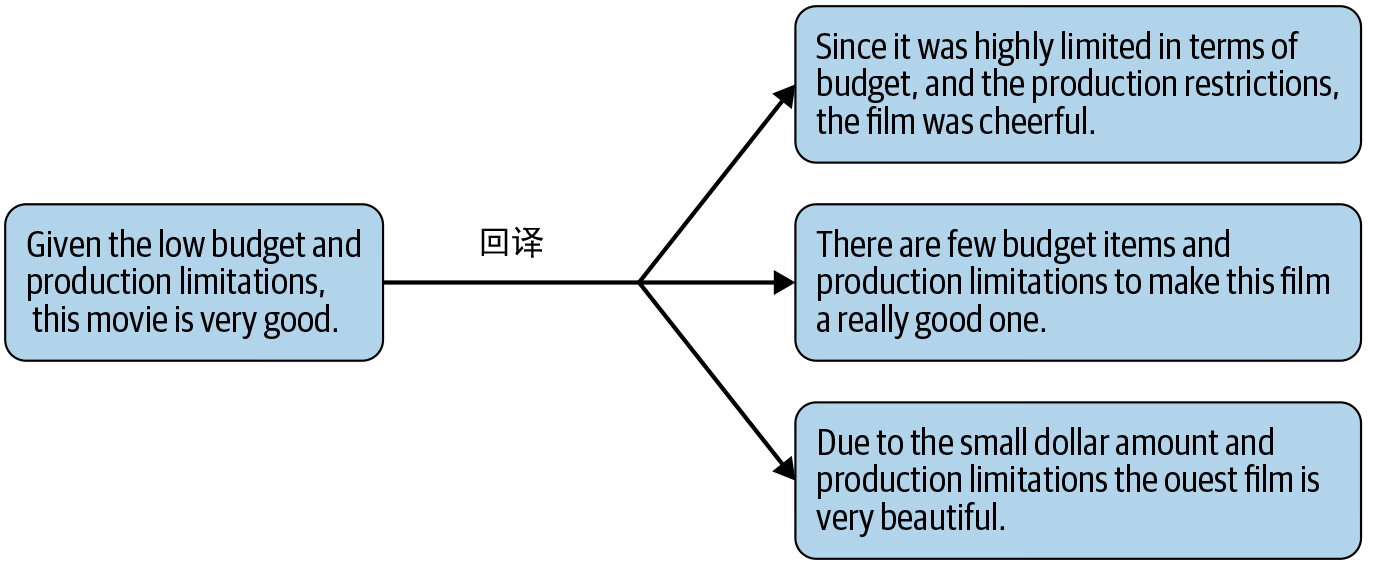
图 2-2:回译
基于 TF-IDF 的词替换
回译后,句子中的某些重要词语可能会丢失。在 Qizhe Xie、Zihang Dai、Eduard Hovy 等人的文章“Unsupervised Data Augmentation for Consistency Training”中,作者使用 TF-IDF 来处理这个问题,第 3 章将引入这一概念。
二元语法翻转
把句子按二元语法进行切分。随机取一组二元语法,将其翻转。例如,在“我要去超市”中,取二元语法“要去”,翻转成“去要”,并进行替换。
替换实体
找出人名、地点、组织等实体,用其他同类实体进行替换,即用其他人名替换原有人名,用其他城市替换原有城市等。例如,在“我住在加州”中,用“伦敦”替换“加州”。
数据加噪
在很多自然语言处理应用程序中,输入数据本身就带有拼写错误。这主要是由数据平台的自身特点决定的,例如 Twitter。在这种情况下,可以在数据中添加一点噪声,从而训练出稳健的模型。例如,在句子中随机选择一个词,然后用拼写相近的词进行替换。另外,移动键盘上因误碰触按键而导致的打字错误也可以产生噪声。这时可以用全键盘上的相邻字符来替换正常字符,从而模拟键盘输入错误。
高阶技术
其他一些高阶技术和系统也可以增强文本数据。以下是值得注意的几个。
本节中讨论了很多技术。但要想发挥它们的作用,一个关键的要求是数据集必须干净。即使数据集不够大,根据我们的经验,也可以使用数据增强技术来增加数据量。另外,在日常的机器学习实践中,数据集还可以有不同的来源。在早期阶段,通常没有大规模数据集供自定义场景使用,因此在这个阶段构建生产模型时,就可以组合利用公开数据集、标注数据集和增强数据集。一旦有了给定任务所需的数据,就可以进入流水线的下一步:文本清洗。
3.文本提取和清洗
文本提取和清洗是指从输入数据中提取原始文本的过程,它会删除标记、元数据等所有其他非文本信息,并将文本转换为所需的编码格式。通常,这一过程取决于组织中可用数据的格式,例如来自 PDF、HTML 或图像文本等的静态数据,如图 2-3 所示。
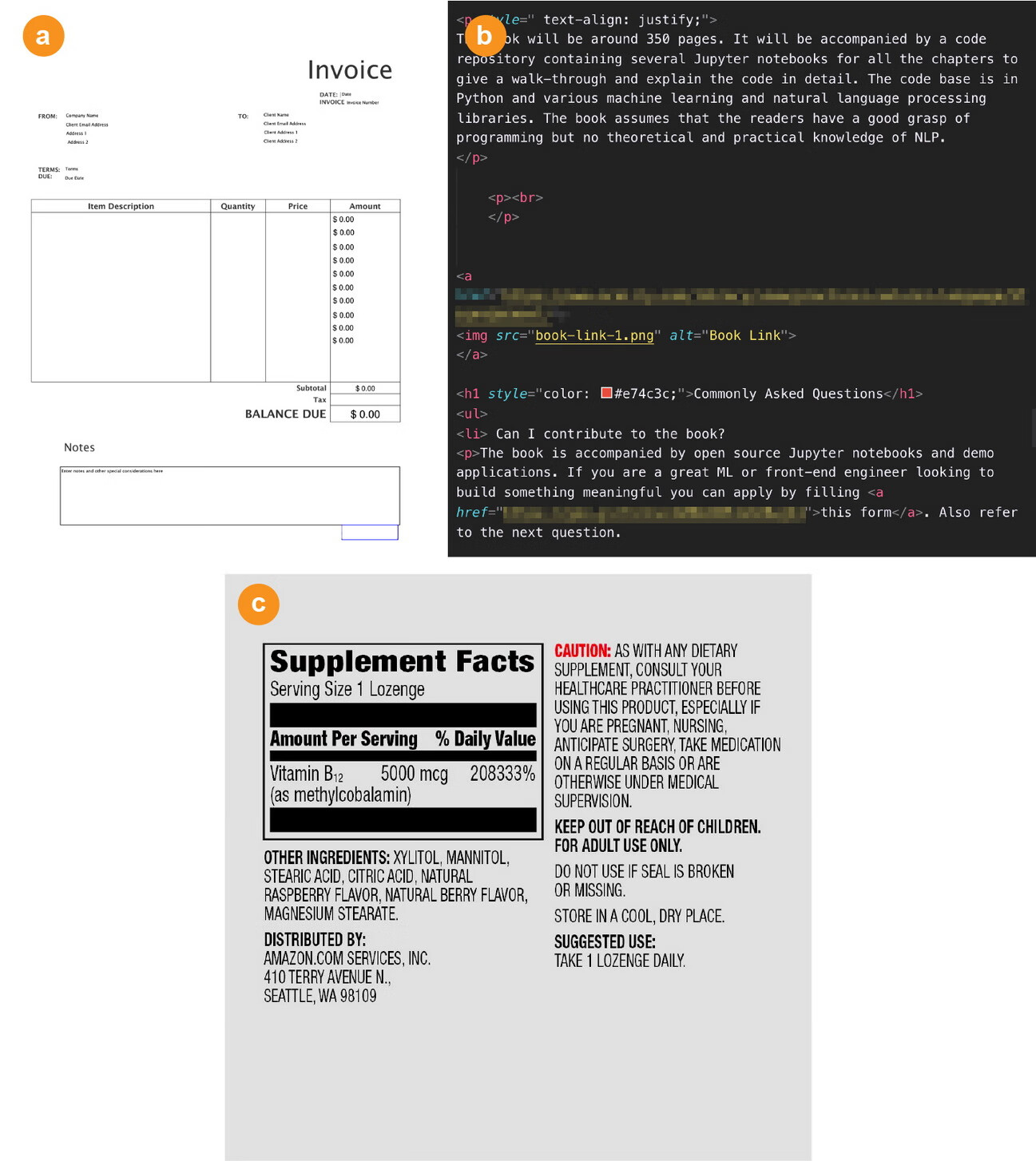
图 2-3:(a) PDF 发票;(b) HTML 文本;(c) 图像中嵌入的文本
文本提取是一个标准的数据整理步骤。这个过程通常不需要特定的自然语言处理技术。然而,这一步非常重要,如果处理不好就会影响自然语言处理流水线的所有后续步骤。此外,文本提取可能也是项目中最耗时的部分。虽然文本提取工具的设计超出了本书的讨论范围,但本节会通过几个示例来说明这一步骤中涉及的各种问题。另外,本节还将讨论从各种来源提取文本的一些重要问题,包括文本清洗,以便其在下游流水线中使用。
3.1HTML解析和清洗
以建立编程问答论坛搜索引擎项目为例。假如已经确定 Stack Overflow 为数据来源,并决定从该网站中提取问题和最佳答案对。在这种情况下,应该如何完成文本提取的步骤?如果观察 Stack Overflow 问题页面的 HTML 标记,就会注意到问题和答案都有特殊的标记。从 HTML 页面提取文本时,可以利用这些信息。虽然编写自己的 HTML 解析器似乎是一种可行的方法,但对于大多数情况来说,更可行的方法是利用现有的库,如 Beautiful Soup 和 Scrapy,它们提供了一系列解析网页的实用程序。下面的代码片段展示了如何使用 Beautiful Soup 来解决这里描述的问题,即从 Stack Overflow 网页中提取问题及其最佳答案对:
from bs4 import BeautifulSoup
from urllib.request import urlopen
myurl = "https://stackoverflow.com/questions/415511/
how-to-get-the-current-time-in-python"
html = urlopen(myurl).read()
soupified = BeautifulSoup(html, "html.parser")
question = soupified.find("div", {"class": "question"})
questiontext = question.find("div", {"class": "post-text"})
print("Question: \n", questiontext.get_text().strip())
answer = soupified.find("div", {"class": "answer"})
answertext = answer.find("div", {"class": "post-text"})
print("Best answer: \n", answertext.get_text().strip())这里,提取想要的内容依赖于对 HTML 文档结构的了解。此代码显示以下输出:
Question:
What is the module/method used to get the current time?
Best answer:
Use:
>>> import datetime
>>> datetime.datetime.now()
datetime.datetime(2009, 1, 6, 15, 8, 24, 78915)
>>> print(datetime.datetime.now())
2009-01-06 15:08:24.789150
And just the time:
>>> datetime.datetime.now().time()
datetime.time(15, 8, 24, 78915)
>>> print(datetime.datetime.now().time())
15:08:24.789150
See the documentation for more information.
To save typing, you can import the datetime object from the datetime module:
>>> from datetime import datetime
Then remove the leading datetime. from all of the above.这个例子有一个特定的需求:提取问题及其答案。在某些场景中,例如从网页中提取邮寄地址,则是先从网页中获取所有文本(而不是部分文本),然后再执行其他操作。通常,所有的 HTML 库都有一些函数,可以剥离所有的 HTML 标记,并只返回标记之间的内容。但这通常会导致噪声输出,并且可能会在提取的内容中看到大量的 JavaScript。在这种情况下,应该只提取网页中包含文本的内容。
3.2Unicode 规范化
在开发代码清洗 HTML 标记时,还可能遇到各种 Unicode 字符,包括符号、表情符号和其他图形字符。图 2-4 中显示了一些 Unicode 字符。

图 2-4:Unicode 字符
为了解析这些非文本符号和特殊字符,需要使用 Unicode 规范化。这意味着我们看到的文本应该转换成某种形式的二进制表示来存储在计算机中。这个过程称为文本编码。忽略编码问题可能会导致后续流水线中出现处理错误。
编码方案有多种,对于不同的操作系统,默认编码可能不同。在很多情况下,特别是在处理多语言文本、社交媒体数据等时,可能需要在文本提取过程中在这些编码方案之间进行转换。以下是 Unicode 处理的一个示例:
text = 'I love 🍕 ! Shall we book a 🚕 to get pizza?'
Text = text.encode("utf-8")
print(Text)输出:
b'I love Pizza \xf0\x9f\x8d\x95! Shall we book a cab \xf0\x9f\x9a\x95
to get pizza?'处理后的文本是机器可读的,可以在下游流水线中使用。第 8 章将用这个相同的例子详细讨论处理 Unicode 字符的问题。
3.3拼写更正
在速记问题和误触键盘问题的世界中,传入的文本数据经常存在拼写错误。这在搜索引擎、文本聊天机器人、社交媒体等很多数据来源中可能很普遍。虽然删除了 HTML 标记并处理了 Unicode 字符,但拼写错误仍然是一个独特的问题,可能会损害对数据的语义理解,而微博中的速记文本消息往往会妨碍语言处理和上下文理解。以下是两个这样的例子。
速记问题:Hllo world! I am back!
误触键盘问题:I pronise that I will not bresk the silence again!
速记问题在聊天界面中很普遍,而误触键盘问题在搜索引擎中也很常见,而且大多是无意间造成的。尽管这个问题不难理解,但目前还没有可靠的方法来解决这个问题。即便如此,我们仍然可以尝试应对。微软发布了一个 REST API,可以在 Python 中用于拼写检查。
import requests
import json
api_key = "<此处输入密钥>"
example_text = "Hollo, wrld" # 需要拼写检查的文本
data = {'text': example_text}
params = {
'mkt':'en-us',
'mode':'proof'
}
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'Ocp-Apim-Subscription-Key': api_key,
}
response = requests.post(endpoint, headers=headers, params=params, data=data)
json_response = response.json()
print(json.dumps(json_response, indent=4))输出(仅显示部分结果):
"suggestions": [
{
"suggestion": "Hello",
"score": 0.9115257530801
},
{
"suggestion": "Hollow",
"score": 0.858039839213461
},
{
"suggestion": "Hallo",
"score": 0.597385084464481
}完整的教程参见微软文档中的“Quickstart: Check spelling with the Bing Spell Check REST API and Python”。
除了 API 之外,还可以使用特定语言的大词典来构建自己的拼写检查器。一个简单的解决方案是寻找所有改动(添加、删除、替换)最少的词。例如,如果“hello”是词典中已经存在的有效单词,那么在“hllo”中只添加“e”(改动最少)就可以进行拼写更正。
3.4特定于系统的错误更正
互联网上获取的 HTML 和原始文本只是文本数据的两个来源。考虑另一个场景,假设数据集是 PDF 文档。在这种情况下,流水线的第一步是从 PDF 文档中提取纯文本。然而,不同的 PDF 文档具有不同的编码方式。有时,提取全部文本可能非常困难,或者文本的结构可能会变得混乱。如果需要全部文本,或者文本必须符合语法,或者文本必须是完整的句子,那么这可能会影响我们的应用程序,例如根据报纸文本提取新闻中不同人物之间的关系。虽然有几个库可以从 PDF 文档中提取文本,比如 PyPDF、PDFMiner 等,但它们还远远不够完美,而且这种库无法处理 PDF 文档的情况并不少见。我们把这些库的探索留给读者作为练习。
文本数据的另一个常见来源是扫描文档。从扫描文档中提取文本通常使用 Tesseract 等库的光学字符识别(optical character recognition, OCR)来完成。考虑下面的示例图片,如图 2-5 所示,它摘自 1950 年的某期刊文章片段。

图 2-5:扫描文本示例
下面的代码片段显示了如何使用 Python 库 pytesseract 来提取图片文本:
from PIL import Image
from pytesseract import image_to_string
filename = "somefile.png"
text = image_to_string(Image.open(filename))
print(text)这段代码将打印如下输出,其中 \n 表示换行符:
'in the nineteenth century the only Kind of linguistics considered\nseriously
was this comparative and historical study of words in languages\nknown or
believed to Fe cognate—say the Semitic languages, or the Indo-\nEuropean
languages. It is significant that the Germans who really made\nthe subject what
it was, used the term Indo-germanisch. Those who know\nthe popular works of
Otto Jespersen will remember how fitmly he\ndeclares that linguistic
science is historical. And those who have noticed'不难发现,在这种情况下,OCR 系统的输出有两个错误。在其他情况下,OCR 输出可能存在更多的错误,这取决于原始扫描件的质量。在进入流水线的下一个阶段之前,应该如何清洗文本?一种方法是使用拼写检查器(如 pyenchant)检查文本,识别拼写错误并提出替换方案。近些年的方法则使用神经网络架构来训练基于词 / 字符的语言模型,然后使用这些语言模型根据上下文来校正 OCR 的文本输出。
回到第 1 章介绍过的语音助手示例。在这种情况下,文本提取的来源是自动语音识别(automatic speech recognition, ASR)系统的输出。与 OCR 一样,ASR 中的错误也很常见,这是由方言、俚语、非母语英语、新词或专业术语等各种因素造成的。这里也可以遵循上述拼写检查器或神经语言模型的方法来清洗提取的文本。
以上只是文本提取和清洗过程中可能出现的潜在问题的一些示例。虽然自然语言处理在这个过程中起到的作用非常有限,但这些示例表明,文本提取和清洗可能会给典型的自然语言处理流水线带来挑战。接下来的相关内容中,还会涉及这些方面。现在进入流水线的下一步:预处理。
4.预处理
先从一个简单的问题开始:既然上一步已经对文本做了一些清洗,那为什么还要进行预处理?考虑这样一个场景:处理维基百科人物页面的文本,提取传记信息。数据获取从抓取页面开始。然而,抓取的数据都是 HTML 格式的,其中有很多维基百科的样板文本(例如,左侧面板中的所有链接),同时还可能存在指向多种语言的链接(在脚本中)等。大多数情况下,这些信息与文本特征提取无关。文本提取步骤已经移除了这些信息,并给出了所需文章的纯文本。然而,所有的自然语言处理软件通常是在句子级别上工作的,并且至少需要分词。因此,需要某种方法将文本分解成词和句子,然后在流水线中进一步处理。有时,特殊字符和数字需要删掉;有时,大小写不重要,所有内容需要转换成小写。在处理文本时,还有很多类似的决定。这些决定都属于自然语言处理流水线的预处理步骤。以下是自然语言处理软件中常用的一些预处理步骤。
预备步骤
句子切分和分词。
常用步骤
停用词删除、词干提取和词形还原、数字 / 标点符号删除、大小写转换等。
停用词(Stop words)是在文本处理中被忽略的常见词语,因为它们通常对文本的含义贡献较小。这些词语在处理文本时被过滤掉,以减小数据维度、提高处理效率,并集中注意力在更重要的词语上。停用词通常包括一些常见的连接词、介词、代词和其他无实际语义的词。
停用词的具体列表可能因应用、语言和任务而异,但通常包括以下类型的词语:
1. **连接词(Conjunctions):** 如"and"、"but"、"or"等,用于连接词语、短语或句子。
2. **介词(Prepositions):** 如"in"、"on"、"at"等,用于表示空间、时间关系。
3. **代词(Pronouns):** 如"he"、"she"、"it"、"they"等,用于替代名词。
4. **冠词(Articles):** 如"a"、"an"、"the",用于指定名词的特定性。
5. **助词(Auxiliary verbs):** 如"am"、"is"、"are"、"was"、"were"等,用于构成各种时态和语态。
6. **常见的高频词:** 在一些应用中,一些常见的高频词也被视为停用词,因为它们在大多数文本中都出现,对区分文本的重要信息贡献有限。
在文本处理的预处理阶段,通常会对文本进行分词,并将其中的停用词移除,以减小文本数据的维度。这有助于提高后续文本分析任务的效率,并且通常不会影响对文本语义的理解。停用词的具体选择可以根据具体任务和语境进行调整。有些应用中,一些原本被认为是停用词的词语可能对任务有重要作用,因此可能需要重新考虑停用词的列表。其他步骤
规范化、语言检测、语码混用、音译等。
高级处理
词性标注、句法解析、共指消解等。
虽然并非所有的自然语言处理流水线都会遵循以上步骤,但前两个步骤或多或少是随处可见的。下面来看一看这些步骤的含义。
4.1预备步骤
如前所述,自然语言处理软件在分析文本之前通常需要先将文本分解成词(词符,token)和句子。因此,任何自然语言处理流水线都必须可靠地将文本切分成句子(句子切分),并进一步将句子切分成词(分词)。从表面上看,这些似乎是简单的任务,但为什么还需要特殊处理?接下来解释其中的原因。
-
句子切分
在句号和问号出现时将文本切分成句子来进行句子切分,这是一个简单的规则。但是,缩写、称呼(Dr.、Mr. 等)或者英文省略号(...)可能会打破这个简单的规则。
幸运的是,大多数自然语言处理库实现了一定的句子切分和分词,因此不必担心如何解决这些问题。一个常用的库是“自然语言工具包”(Natural Language Tool Kit, NLTK)。下面的代码以本章第一段英文原文为输入,展示了如何使用 NLTK 的句子切分和分词器:
from nltk.tokenize import sent_tokenize, word_tokenize mytext = "In the previous chapter, we saw examples of some common NLP applications that we might encounter in everyday life. If we were asked to build such an application, think about how we would approach doing so at our organization. We would normally walk through the requirements and break the problem down into several sub-problems, then try to develop a step-by-step procedure to solve them. Since language processing is involved, we would also list all the forms of text processing needed at each step. This step-by-step processing of text is known as pipeline. It is the series of steps involved in building any NLP model. These steps are common in every NLP project, so it makes sense to study them in this chapter. Understanding some common procedures in any NLP pipeline will enable us to get started on any NLP problem encountered in the workplace. Laying out and developing a text-processing pipeline is seen as a starting point for any NLP application development process. In this chapter, we will learn about the various steps involved and how they play important roles in solving the NLP problem and we’ll see a few guidelines about when and how to use which step. In later chapters, we’ll discuss specific pipelines for various NLP tasks (e.g., Chapters 4–7)." my_sentences = sent_tokenize(mytext) -
分词
与句子切分类似,要将句子切分成词,也可以从一个简单的规则开始:根据标点符号将文本切分成词。NLTK 库实现了这一功能。仍然使用前面的例子:
for sentence in my_sentences: print(sentence) print(word_tokenize(sentence))对于第一个句子,输出打印如下:
In the previous chapter, we saw a quick overview of what is NLP, what are some of the common applications and challenges in NLP, and an introduction to different tasks in NLP. ['In', 'the', 'previous', 'chapter', ',', 'we', 'saw', 'a', 'quick', 'overview', 'of', 'what', 'is', 'NLP', ',', 'what', 'are', 'some', 'of', 'the', 'common', 'applications', 'and', 'challenges', 'in', 'NLP', ',', 'and', 'an', 'introduction', 'to', 'different', 'tasks', 'in', 'NLP', '.']虽然现成的解决方案可以满足大多数需求,而且大多数自然语言处理库附带分词器和句子切分器,但重要的是,它们还远远不够完美。例如,考虑这样一个句子,“Mr. Jack O'Neil works at Melitas Marg, located at 245 Yonge Avenue, Austin, 70272”。使用 NLTK 分词器分词后,“O”“'”和“Neil”被识别为三个独立的词。类似地,如果通过这个分词器运行这个句子,“There are $10,000 and € 1000 which are there just for testing a tokenizer”,“$”和“10,000”被识别为两个词,而“€1000”被识别为一个词。另外,如果要对推文进行分词,这个分词器会将标签切分成两个词:“#”号和后面的字符串。在这种情况下,可能需要使用专门构建的自定义分词器。回到刚才的例子,总之,在执行句子切分之后,还要执行分词。
需要注意,NLTK 还有一个推文分词器。第 4 章和第 8 章会讲述它的用法。总而言之,尽管词和句子的切分方法看起来是初级的和易于实现的,但它们可能并不总能满足特定的切分需求,正如以上示例所示。请注意,以上是 NLTK 的示例,但是这些观察结果同样适用于其他库。这里把其他库的探索留给读者作为练习。
正如分词可能因领域而异,分词也严重依赖于语言。每种语言都有不同的语言规则和例外情况。图 2-6 显示了一个例子,其中“N.Y.!”共有三个标点符号。但在英语中,N.Y. 代表纽约,因此“N.Y.”应被视为一个词,不应进一步切分。这种特定于语言的例外情况可以在 spaCy 提供的分词器中指定。另外,spaCy 还可以开发自定义规则,用于处理具有丰富屈折变化(前缀或后缀)和复杂形态的语言的例外情况。
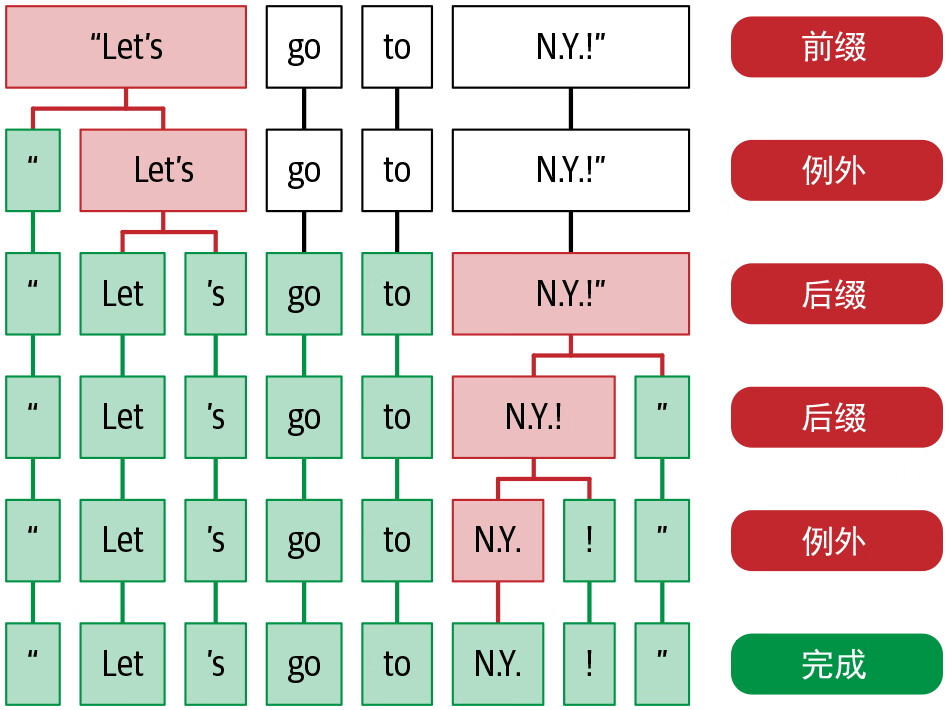
图 2-6:特定于语言(此处为英语)的分词的例外情况(参见 spaCy 网站文章“spaCy 101: Everything you need to know”)
另一个需要记住的重要事实是,任何句子切分器和分词器都会对接收到的输入敏感。假设需求是编写一个软件,从求职信中提取公司、职位和薪水等信息。求职信遵循一定的格式,包括收件人地址、发件人地址、文末签名等。在这种情况下,应该如何决定什么是句子?是整个地址被当作一个“句子”,还是每一行都单独切分?这些问题的答案取决于想要提取的内容,以及流水线其他部分对此类决策的敏感程度。对于识别特定的模式(例如日期或货币表达式),格式良好的正则表达式是第一步。在许多实际场景中,最终可能会使用适合文本结构的自定义分词器或句子切分器,而不是标准自然语言处理库中现有的分词器或句子切分器。
4.2常用步骤
现在来看自然语言处理流水线中其他一些常用的预处理操作。假设需求是设计一个软件,将新闻文章的类别标识为政治、体育、商业和其他四类。假设有一个好的句子切分器和分词器。这时,就必须开始思考什么样的信息对开发分类工具是有用的。英语中的一些常用词,如 a、an、the、of、in 等,对这项任务来说并不是特别有用,因为它们本身不携带任何含义来区分这四个类别。这样的词叫停用词。在这样的问题场景中,停用词通常(但并不总是)需要删除,以便进一步分析。不过,英语没有标准的停用词列表。虽然有一些常见的列表(例如 NLTK 就有一个),不过停用词可能会根据正在处理的内容而有所不同。例如,“news”可能是这个问题场景的停用词,但对于上一步示例中的求职信数据,可能又不是停用词。
类似地,在某些情况下,大写或小写可能对问题没有影响。因此,所有的文本都转换成小写(或者大写,不过小写更常见)。另外,删除标点和 / 或数字也是许多自然语言处理问题的常见步骤,例如文本分类(第 4 章)、信息检索(第 7 章)和社交媒体分析(第 8 章)。这些步骤是否有用,以及如何有用,接下来的内容会给出示例。
下面的代码示例显示了如何删除给定文本集合中的停用词、数字和标点符号,并将其转换成小写:
from nltk.corpus import stopwords
from string import punctuation
def preprocess_corpus(texts):
mystopwords = set(stopwords.words("english"))
def remove_stops_digits(tokens):
return [token.lower() for token in tokens if token not in mystopwords and
not token.isdigit() and token not in punctuation]
return [remove_stops_digits(word_tokenize(text)) for text in texts]需要注意的是,这四个过程在本质上既不是强制的,也不是顺序的。上面的函数只是用于说明如何将这些处理步骤添加到项目中。这里看到的预处理,虽然针对的是文本数据,但并没有涉及语言学特征,也就是除了频率(停用词是出现非常频繁的词)之外,并不关注任何语言特征,而且删除的都是非字母数据(标点符号、数字)。将词级属性考虑在内的两个常用预处理步骤分别是词干提取和词形还原。
词干提取和词形还原
词干提取是指去掉后缀并将一个词简化为某种基本形式的过程,以便该词的所有不同变体都可以用相同的形式表示(例如,“car”和“cars”都被简化为“car”)。这是通过应用一组固定的规则来完成的(例如,如果该词以“es”结尾,则删除“es”)。更多这样的例子如图 2-7 所示。虽然这样的规则可能并不总是得到语言学上正确的基础形式,但词干提取通常用于搜索引擎,以将用户查询与相关文档匹配,也用于文本分类,以减少特征空间来训练机器学习模型。

图 2-7:词干提取和词形还原的区别(参见 Devopedia 网站的文章“Lemmatization”)
下面的代码片段显示了如何使用 NLTK Porter Stemmer 这种词干提取算法:
from nltk.stem.porter import PorterStemmer
stemmer = PorterStemmer()
word1, word2 = "cars", "revolution"
print(stemmer.stem(word1), stemmer.stem(word2))这给出了“cars”的词干“car”,“revolution”的词干“revolut”,不过“revolut”在语言学上并不正确。虽然这可能不会影响搜索引擎的性能,但在其他一些情况下,推导出正确的语言形式是有用的。这可以通过词形还原来完成。词形还原和词干提取很接近。
词形还原是将一个词的所有不同形式映射到其基本词或词元(lemma)的过程。虽然这看起来很接近词干提取的定义,但事实上它们是不同的。例如,形容词“better”在词干提取后保持不变,但在词形还原后,应该变成“good”,如图 2-7 所示。词形还原需要较多的语言学知识,建模和开发高效的词形还原器仍然是自然语言处理研究中的一个遗留问题。
以下代码片段显示了 NLTK 中基于 WordNet 的词形还原器的用法:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("better", pos="a")) # a代表形容词以下代码片段显示了 spaCy 的词形还原器:
import spacy
sp = spacy.load('en_core_web_sm')
token = sp(u'better')
for word in token:
print(word.text, word.lemma_)NLTK 打印输出为“good”,而 spaCy 打印输出为“well”——两者都是正确的。由于词形还原需要对词及其上下文进行一定程度的语言分析,因此它比词干提取要花更长的时间,而且通常只有在绝对必要时才使用。接下来的内容还会涉及词干提取和词形还原的使用。词形还原器的选择根据情况而定,可以选择 NLTK 或 spaCy。这具体取决于其他预处理步骤使用的是什么框架,但最终的目的是确保在完整的流水线中使用同一种框架。
记住,并非所有这些步骤都是必需的,也不是所有这些步骤都是按照这里讨论的顺序执行的。例如,如果要删除数字和标点符号,那么谁先删除可能无关紧要。但是,文本转小写通常先于词干提取,而词形还原先于删除词元或文本转小写,这是因为词形还原需要知道词的词性,而这又要求句子中的所有词都必须原封不动。一个好的做法是,在对如何处理数据有了清楚的了解之后,按顺序编写一个预处理任务列表。
图 2-8 简要总结了到目前为止这一节中介绍的各种预处理步骤。
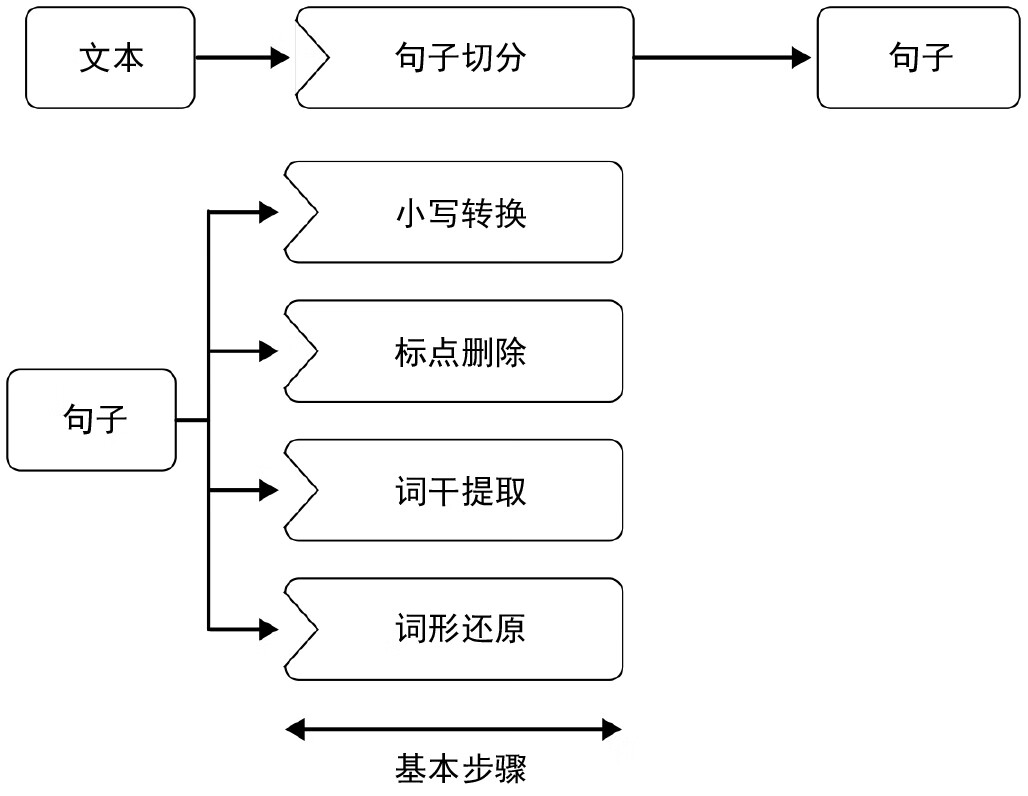
图 2-8:文本块的常见预处理步骤
请注意,这些是常见的预处理步骤,但它们绝不是详尽无遗的。根据数据的性质,其他预处理步骤可能也很重要。下面来看其中的一些步骤。
4.3其他预处理步骤
以上是自然语言处理流水线的常见预处理步骤。虽然没有明确说明文本的性质,但都假设处理的是普通英语文本。但如果情况并非如此,那预处理步骤又有什么不同?下面用几个例子介绍处理这类场景的几个预处理步骤。
-
文本规范化
考虑这样一个场景:使用社交媒体帖文来检测新闻事件。社交媒体文本与报纸上看到的语言有很大的不同。一个词可以用不同的方式拼写,包括缩写形式,一个电话号码可以用不同的格式书写(例如,带连字符和不带连字符),名字有时用小写,等等。当我们致力于开发自然语言处理工具来处理这类数据时,将所有这些变体捕获到一个表示中并获得文本的规范表示是很有用的。这就是所谓的文本规范化。文本规范化的一些常见步骤是将所有文本转换为小写或大写,将数字转换为文本,展开缩写,等等。spaCy 的源代码提供了文本规范化的一种简单方法,它是一个字典,将预置单词集合的不同拼写映射到单一拼写上。第 8 章会给出文本规范化的更多示例。
-
语言检测
很多网络内容是非英语语言的。以收集网上的所有产品评论为例。当浏览各个电商网站并开始爬取相关的产品页面时,一些非英语评论出现了。既然流水线大部分是用特定于语言的工具构建的,那么本来期待英语文本的自然语言处理流水线会发生什么呢?在这种情况下,自然语言处理流水线的第一步就是执行语言检测。可以使用 Polyglot 之类的库进行语言检测。完成这一步后,接下来的步骤可以沿用特定于语言的流水线。
-
语码混用和音译
上面讨论了文本内容是非英语语言的场景。然而,还有另一种情况,即一段内容使用多种语言。世界上许多人在日常生活中讲不止一种语言。因此,在社交媒体帖文中使用多种语言并不少见,甚至一篇帖文中也可能包含多种语言。图 2-9 展示了一个新加坡式英语(新加坡俚语 + 英语)短语,作为语码混用的一个例子。

图 2-9:新加坡式英语短语中的语码混用
这个流行短语中包含泰米尔文、英文、马来文和中文。语码混用指的是这种在语言之间切换的现象。当人们在书面写作中使用多种语言时,他们经常用罗马文字和英语拼写来输入这些语言中的词汇。因此,其他语言的词汇被写在英语文本中。这就是所谓的音译。这两种现象在多语言社区中都很常见,需要在文本预处理过程中加以处理。第 8 章将讨论更多这方面的内容,并给出社交媒体文本中出现这些现象的例子。
对常见预处理步骤的讨论到此结束。虽然这个列表并不是详尽无遗的,但是希望它能让你明白不同性质的数据集可能需要不同形式的预处理。自然语言处理流水线还有一些预处理步骤需要高级的语言处理,下面来看一下。
4.4高级处理
假如现在需要开发一个系统来识别公司 100 万份文档中的人员和组织名称,那么前面讨论的常见预处理步骤就无能为力了。识别名称需要词性标注。如果词性是专有名词,那么这将有助于识别人员和组织名称。如何在项目的预处理阶段进行词性标注?本书不会详细讨论词性标注器的开发(详见 Daniel Jurafsky 和 James H. Martin 的著作 Speech and Language Processing (3rd ed. draft) 中的第 8 章)。预先训练好的、易于使用的词性标注器已在 NLTK、spaCy、Parsey McParseface Tagger 等自然语言处理库中实现,通常不必开发自己的词性标注解决方案。下面的代码片段说明了如何使用预置在 spaCy 库中的多个预处理函数:
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp(u'Charles Spencer Chaplin was born on 16 April 1889 toHannah Chaplin (born Hannah Harriet Pedlingham Hill) and Charles Chaplin Sr')
for token in doc:
print(token.text, token.lemma_, token.pos_, token.shape_, token.is_alpha, token.is_stop)在这个简单的代码片段中,可以看到分词、词形还原、词性标注和其他几个步骤。注意,如果需要,还可以在这个代码片段中添加其他的处理步骤,这里留给读者作为练习。需要注意的是,对于相同的预处理步骤,不同自然语言处理库的输出可能存在差异。部分原因是,不同的库使用不同的实现和算法。最终在项目中使用哪一个(或多个)库,是一个主观决定,取决于所需的语言处理量。
现在考虑一个稍微不同的问题:除了在公司的 100 万份文档中识别人员和组织名称之外,还需要识别给定的个人和组织是否具有某种关系 [ 例如,萨蒂亚•纳德拉和微软之间的关系是“首席执行官”(CEO)]。这就是所谓的关系提取问题,第 5 章将详细讨论。但是现在先想一下这种情况需要什么样的预处理。首先需要词性标注,前面已经介绍如何把词性标注添加到流水线。其次需要一种识别人员和组织名称的方法,这是一个单独的信息提取任务,称为命名实体识别(named entity recognition, NER),具体将在第 5 章中讨论。除此之外,还需要一种方法来识别句子中两个实体之间的“关系”模式。这就需要对句子有某种形式的句法表示,比如句法解析,这在第 1 章中已经谈到。此外,还需要一种方法来识别和链接一个实体的多个提及(例如,萨蒂亚•纳德拉、纳德拉先生、他等)。这一点通过共指消解预处理步骤来实现。第 1 章的 1.5 节中展示了这方面的一个例子。图 2-10 显示了 Stanford CoreNLP 的输出,包括示例句子的句法解析器输出和共指消解输出,以及前面讨论过的其他预处理步骤。
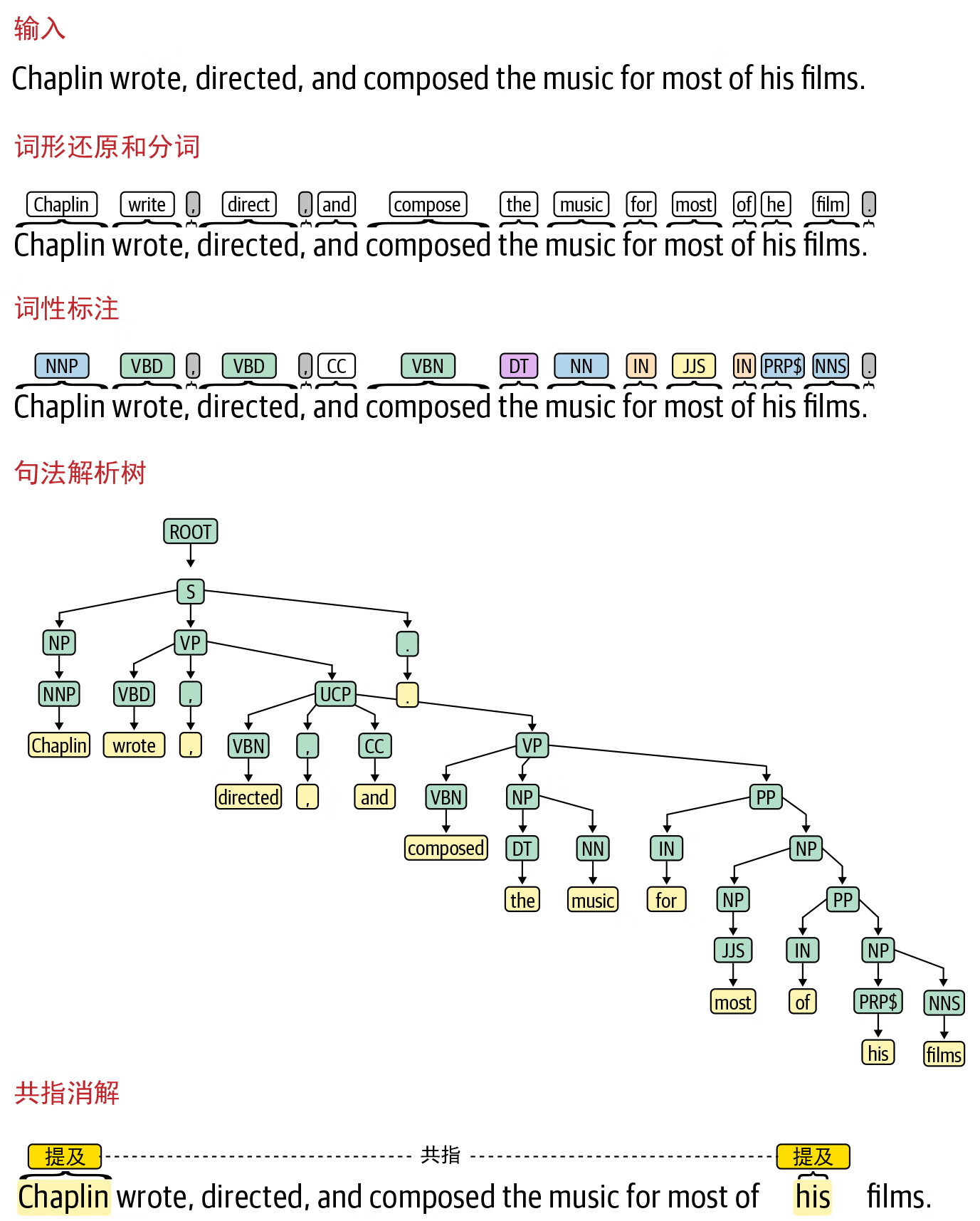
图 2-10:自然语言处理流水线不同阶段的输出
到目前为止,本节展示的是流水线中一些最常见的预处理步骤。在各个自然语言处理库中,都有经过预先训练的模型,可以直接使用。除此之外,可能还需要额外的、定制的预处理,具体取决于应用程序。例如,考虑这样一个案例:挖掘产品的社交媒体情绪。从 Twitter 上收集数据后,很快就会发现有些推文不是用英语写的。在这种情况下,可能需要在其他步骤之前加一个语言检测步骤。
此外,需要哪些步骤,还取决于具体的应用程序。如果创建的系统是识别影评人在影评中表达对电影的正向情感或负向情感,可能就不用太担心句法解析或共指消解,但会考虑去掉停用词、小写转换和去掉数字。然而,如果对从电子邮件中提取日历事件感兴趣,那么最好不要删除停用词或进行词干提取处理,而是增加句法解析等步骤。如果想要提取文本中不同实体和其中提到的事件之间的关系,那么将需要共指消解,正如前面所讨论的。第 5 章会展示需要这些步骤的例子。
最后,必须考虑每种情况下预处理的详细程序,如图 2-11 所示。

图 2-11:文本块的高级预处理步骤
例如,词性标注前不能先去掉停用词、转换小写等,否则会改变句子的语法结构,从而影响词性标注器的输出。预处理步骤如何帮助处理某个给定的自然语言处理问题,这也是特定于应用程序的,只能通过大量的实验来回答。接下来的内容还会再次讨论不同自然语言处理应用程序所需的更具体的预处理步骤。现在进入下一个步骤:特征工程。
5.特征工程
前面介绍了不同的预处理步骤,以及它们的应用范围。但在后面使用机器学习方法来执行建模步骤之前,仍然需要一种方法来将预处理后的文本馈送到机器学习算法中。特征工程是指完成这项任务的一套方法,也叫特征提取,其目标是捕捉文本的特征,将其转换成可以被机器学习算法理解的数值向量。在本书中,这一步骤称为“文本表示”,这是第 3 章的主题。此外,第 11 章还将在通过开发完整的自然语言处理流水线和迭代流水线来提高性能的背景下详细介绍特征提取。这里简要介绍:(1) 经典自然语言处理和传统机器学习流水线;(2) 深度学习流水线中特征工程的两种不同方法。图 2-12(改编自 Parsa Ghaffari 的文章“Leveraging Deep Learning for Multilingual Sentiment Analysis”)显示了这两种方法的区别。
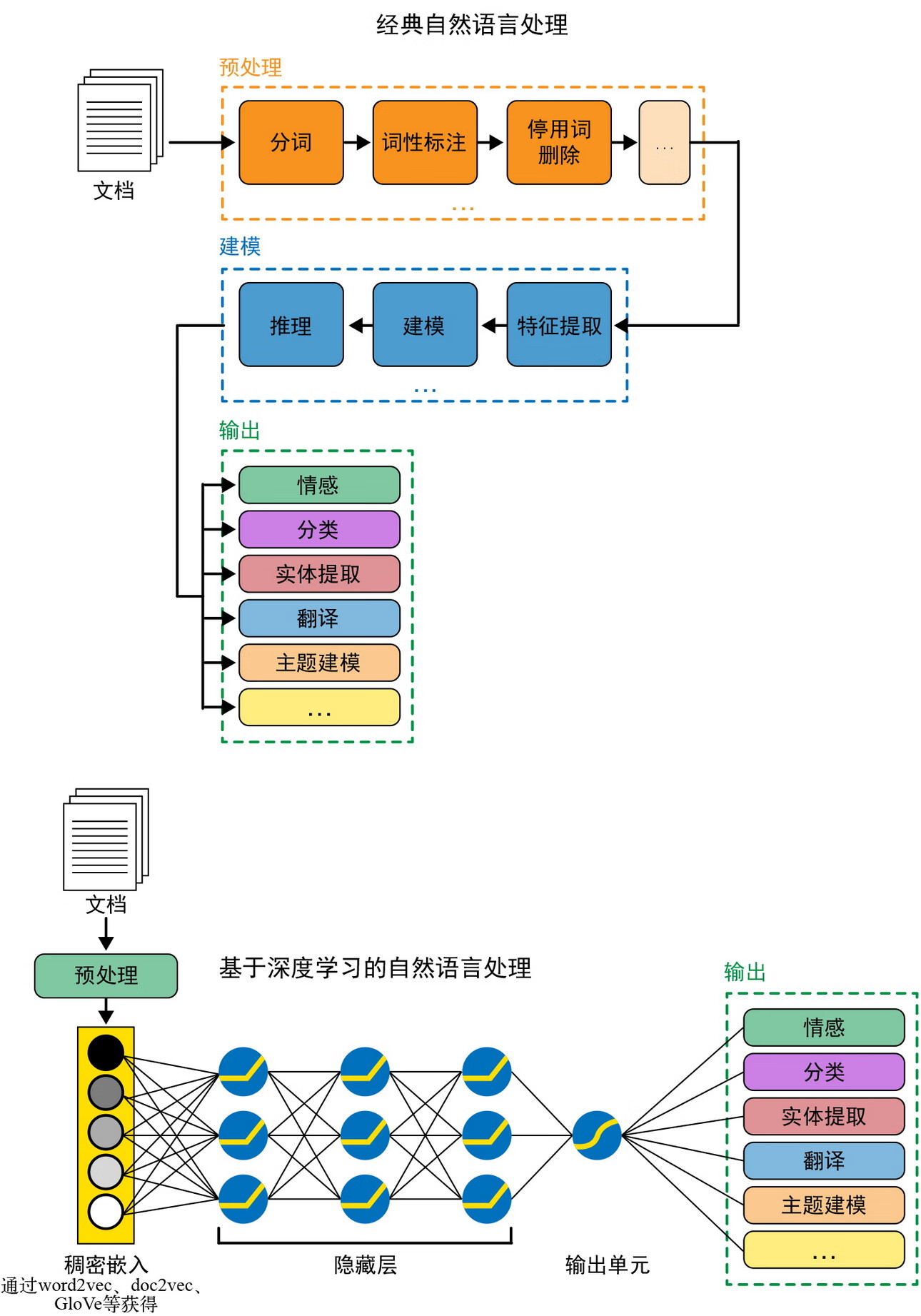
图 2-12:经典自然语言处理与基于深度学习的自然语言处理的特征工程
5.1经典自然语言处理/机器学习流水线
特征工程在任何机器学习流水线中都是一个不可或缺的步骤。特征工程步骤将原始数据转换为机器可以使用的格式。在经典的机器学习流水线中,这些转换函数通常是人工编写的,以适应手头的任务。考虑电商产品评论的情感分类任务。如何将评论转换成有意义的“数值”,以帮助预测评论的情感(正向或负向)?一种方法是计算每个评论中正向和负向词的数量。另外,还有其他统计方法可以用来理解某个特征是否对任务有用,第 11 章会讨论这个问题。构建经典机器学习模型的主要启示是,这些特征在很大程度上需要手头任务和领域知识的启发(例如,在影评示例中使用情感词汇)。人工提取特征的一个优点是模型可以保持可解释性——可以精确量化每个特征对模型预测的影响程度。
5.2深度学习流水线
经典机器学习模型的主要缺点是特征工程。人工提取特征工程已经成为模型性能和模型开发周期的瓶颈。一个有噪声或不相关的特征可能会给数据增加更多的随机性,从而潜在地损害模型的性能。最近,随着深度学习模型的出现,这种方法发生了变化。
在深度学习流水线中,原始数据经过预处理后,直接输入模型,模型能够直接从数据中“学习”特征。因此,这些特征与手头任务更一致,通常可以提高性能。但是,由于所有这些特征都是通过模型参数学习的,因此模型失去了可解释性。很难解释深度学习模型的预测,这在业务驱动的用例中是一个缺点。例如,当把一封电子邮件识别为正常邮件或垃圾邮件时,需要知道哪个词或短语在造成正常邮件或垃圾邮件中发挥了重要作用。虽然这对于人工提取特征来说很容易做到,但对于深度学习模型来说就不容易了。
正如前面提到的,特征工程是非常特定于任务的,因此本书会以文本数据和一系列任务为背景来讨论特征工程。有了对特征工程的高层次理解之后,现在来看流水线的下一步:建模。
6.建模
假如现在有了自然语言处理项目的相关数据,并且也清楚地知道需要做什么样的清洗和预处理以及需要提取哪些特征。那么下一步就是如何在此基础上构建一个有用的解决方案。在开始阶段,当拥有的数据有限时,可以使用简单的方法和规则。随着时间的推移,随着数据的增加和对问题理解的加深,就可以增加更多的复杂性并提高性能。本节将介绍这一过程。
6.1从简单的启发式开始
在构建模型的最开始,机器学习本身可能不会发挥主要作用,部分原因是缺乏数据。另外,人工构建的启发式方法在某种程度上也可以提供一个很好的开端。有时,启发式——或者隐式,或者显式——可能已经是系统的一部分。例如,在垃圾邮件分类任务中,对专发垃圾邮件的域设置黑名单。这些信息可以用来过滤来自这些域的电子邮件。类似地,把极有可能表示垃圾邮件的词加入黑名单,也可以用于垃圾邮件分类。
这种启发式方法可以在一系列任务中找到,尤其是在应用机器学习的开始阶段。在电子商务场景中,可以使用基于购买数量的启发式,来对搜索结果进行排序,并显示属于同一类别的产品作为推荐。与此同时,可以收集数据,构建一个更大的协同过滤系统,从而根据具有相似购买习惯的客户所购买的产品等一系列其他特征来推荐产品。
另一种在系统中引入启发式的常见方法是使用正则表达式。考虑从文本文档中提取日期、 电话、人名等不同形式的信息。虽然电子邮件地址、日期和电话号码等信息可以使用普通 (但也复杂)的正则表达式提取,但 Stanford NLP 的 TokensRegex 和 spaCy 的“基于规则 的匹配器”这两个工具,可以定义高级的正则表达式,以捕获人名等其他信息。图 2-13 显 示了 spaCy 的基于规则的匹配器的一个实例。
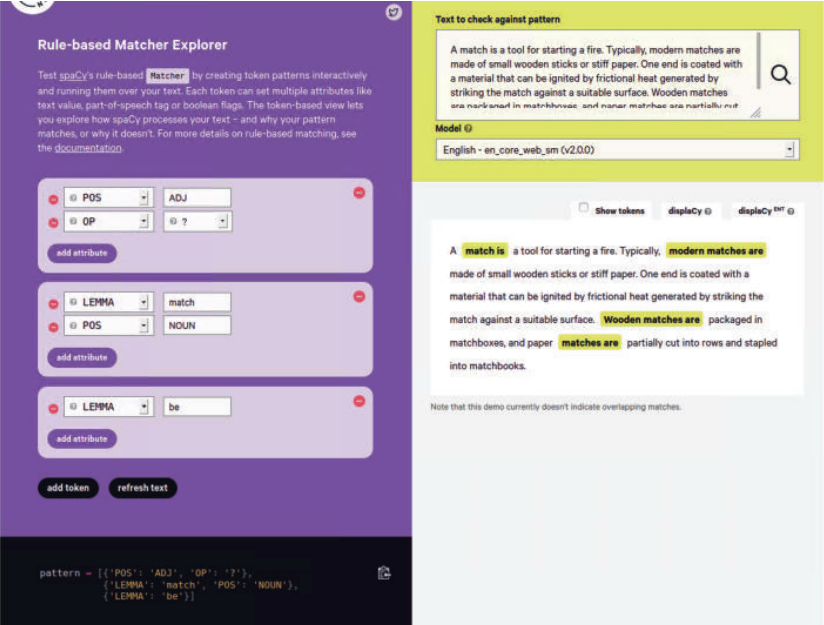
图 2-13:spaCy 基于规则的匹配器
该模式将查找包含词元为“match”(且为名词形式)的文本,而且该词前面可以有一个形容词,但是后面必须跟着词元为“be”的词。这种模式是正则表达式的高级形式,需要本 章前面介绍的一些自然语言处理预处理步骤。在缺乏大量训练数据的情况下,如果有一些领域知识,就可以使用规则 / 启发式来编码这些知识以开始构建系统。即使在构建基于机 器学习的模型时,也可以使用这种启发式来处理特殊情况,例如模型效果不好的情况。因 此,简单的启发式可以提供一个很好的起点,而且启发式在机器学习模型中也是有用的。 假设现在已经构建了基于启发式的系统,那么接下来应该怎么办?
6.2构建自己的模型
虽然一组简单的启发式是一个好的开始,但是随着系统的成熟,添加越来越新的启发式可能会导致一个复杂的、基于规则的系统。这样的系统很难管理,诊断错误的原因可能更难。我们需要一个在成熟时更容易维护的系统。此外,随着收集的数据越来越多,机器学习模型开始战胜纯粹的启发式方法。这时,通常的做法是将启发式直接或间接地与机器学习模型相结合。
有两种方法可以做到这一点。
-
为机器学习模型创建启发式特征
当存在许多启发式时,其中单个启发式的行为是确定的,但它们的组合行为在预测效果 方面是模糊的,因此最好使用这些启发式作为特征来训练机器学习模型。例如,在垃圾 邮件分类示例中,可以向机器学习模型添加一些特征,例如电子邮件中黑名单中的词出 现的次数,或电子邮件弹回率。
-
对机器学习模型的输入进行预处理
如果启发式方法对于某个类别有很高的预测率,那么最好在将数据输入机器学习模型之前使用它。例如,如果电子邮件中的某些词可以 99% 地判定这是垃圾邮件,那么最好 将该电子邮件直接分类为垃圾邮件,而不是将其发送到机器学习模型。
此外,自然语言处理服务提供商——如谷歌云自然语言、亚马逊 Comprehend、微软 Azure 认知服务、 IBM 沃森自然语言理解——提供了现成的 API 来解决各种自然语言处理任务。 如果项目中的自然语言处理问题可以由 API 解决,那么不妨使用 API 来估计任务的可行性 以及现有数据集的质量。一旦确信任务是可行的,并且现成的模型给出了合理的结果,就 可以开始构建自定义的机器学习模型并对其进行完善。
6.3构建最终模型
前面介绍了使用启发式或现有 API,抑或是通过构建自定义机器学习模型来开始构建自然 语言处理系统。从基线方法开始,只有不断改进模型,经过多次迭代后,才有可能构建具 有良好性能并可用于生产的“最终模型”。下面介绍解决这个问题的一些方法。
-
集成与编排
根据经验,常见的做法不是使用单一的模型,而是使用一组机器学习模型,从而应对预 测问题的不同方面。这里有两种方法。其一是将一个模型的输出作为另一个模型的输 入,从而顺序地从一个模型进入另一个模型,并获得最终的输出。这叫模型编排 1。其二 是将多个模型的预测结果汇集起来,并做出最终的预测。这叫模型集成。图 2-14 展示 了这两种过程。
在图 2-14 中,训练数据用于构建模型 1、2 和 3。这些模型的输出合并后进入元模型 (模型的模型),以预测最终结果。例如,在垃圾邮件分类案例中,假设运行了三种不同 的模型:基于启发式的评分模型、朴素贝叶斯模型和 LSTM 模型,这三个模型的输出随后会输入基于逻辑回归的元模型中,然后由元模型给出电子邮件是否为垃圾邮件的概 率。随着产品特征的增多,模型的复杂性也会增加。因此,最终可能会组合使用启发 式、机器学习、编排和集成模型等多种方式,以整合到更大的产品中。
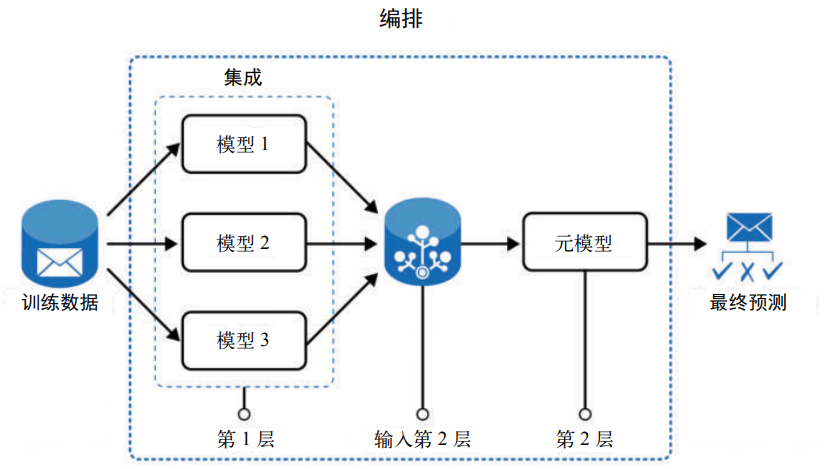
图 2-14:模型集成与编排
-
更好的特征工程
无论是基于 API 的模型,还是自定义的模型,特征工程都是重要的一步,而且特征工 程还会在整个过程中不断演进。更好的特征工程可能会带来更好的性能。如果有很多的 特征,那么可以使用特征选择来找到较好的模型。第 11 章会详细介绍如何迭代特征工 程以实现最佳设置的策略。
-
迁移学习
除了模型编排和集成之外,自然语言处理界还有一种新的趋势正在流行,这就是迁移学 习,第 1 章介绍过。通常,为了更好地理解语言和问题,模型需要数据集之外的外部知 识。迁移学习试图在初始阶段将先前存在的知识从训练好的大型模型迁移到新的模型 中。然后,新模型会慢慢适应手头的任务。这就好比老师把智慧和知识传授给学生。迁 移学习提供了更好的初始化,这有助于下游任务,特别是当下游任务的数据集较小时。 在这些情况下,迁移学习比直接随机初始化效果更好。例如,在垃圾邮件分类中,可以 使用 BERT 来微调电子邮件数据集。第 4~6 章会详细讨论 BERT。
-
再次使用启发式
机器学习模型并非完美无缺。它们仍然会出错。因此,在建模流水线的最后,不妨再来 看一看这些错误情况,发现其中的常见模式,并使用启发式方法来纠正错误。另外还可 以使用无法从数据中捕捉的特定领域知识,来改进模型预测。如果说模型是表演惊人技 巧的空中飞人,那么启发式规则就是安全网,保证表演者不会从空中掉下来。
从完全依赖启发式的无数据阶段,到可以尝试一系列建模技术的多数据阶段,中间会遇到 这样的情况:拥有少量的数据,但又通常不足以构建好的机器学习模型。在这样的场景 中,一种可以遵循的方法是主动学习,即利用用户反馈或其他类似来源不断收集新的数 据,以构建更好的模型。第 4 章将详细讨论这一点。正如刚才所看到的,建模策略在很大 程度上依赖于手头的数据。表 2-1 显示了基于数据数量和质量的决策路径。
表2-1:数据特点和相应的决策路径
| 数据特点 | 决策路径 | 示例 |
|---|---|---|
| 数据量大 | 可以使用需要较多数据的技术,如深度学习。 也可以使用更丰富的特征集。如果数据足够 大但没有标注,也可以使用无监督技术 | 如果拥有很多评论和与之相关的元数 据,可以从头开始构建情感分析工具 |
| 数据量小 | 需要从对数据需求较少的基于规则的解决方 案或传统的机器学习解决方案开始。还可以 使用云 API 并在弱监督下生成更多数据 如果类似的任务有大量的数据,也可以使用 迁移学习 | 这通常发生在全新项目的开始阶段 |
| 数据质量差,数据 异质性严重 | 可能需要更多的数据清洗和预处理 | 可能存在语码混用(不同语言在同一 个句子中混用)、非常规语言、音译或 噪声(如社交媒体文本)等问题 |
| 数据质量良好 | 可以更容易地直接应用现成的算法或云 API | 法律文本或报纸 |
| 数据由具有完整长 度的文档组成 | 根据问题的不同,选择正确的策略将文档切 分成较低的层次,如段落、句子或短语 | 文档分类、评论分析等 |
以上简要介绍了自然语言处理流水线中用到的不同建模形式,以及如何根据所拥有的数据 选择建模路径。在行业场景中构建自然语言处理项目时,监督学习,特别是分类,是最常 见的建模过程。第 4 章将讨论分类模型,第 5~7 章将讨论自然语言处理中用于不同应用场 景的模型。现在来看流水线中的下一步:评估。
7.评估
自然语言处理流水线的一个关键步骤是衡量模型的质量。模型的质量可以有多种含义,但 最常见的解释是用新数据来衡量模型的性能。这一阶段的成功取决于两个因素:(1) 使用 正确的评估指标;(2) 遵循正确的评估流程。
先关注第一个因素。根据自然语言处理任务 或问题的不同,评估指标可能会有所不同。评估指标还可能根据不同阶段而有所不同:模 型构建、部署和生产阶段。在前两个阶段,通常使用机器学习指标来评估。在最后一个阶 段,还会使用业务指标来衡量业务影响。
此外,评估还分成两种类型:内在评估和外在评估。内在评估侧重于中间目标,而外在评 估侧重于最终目标。考虑垃圾邮件分类系统的例子。机器学习指标是精确率和召回率,而 业务指标则是“用户在垃圾邮件上花费的时间”。内在评估侧重于使用精确率和召回率来 衡量系统的性能。外部评估侧重于衡量用户因垃圾邮件未被检测出来或普通邮件被误检测 为垃圾邮件而浪费的时间。
7.1内在评估
本节将探讨衡量自然语言处理系统常用的内在评估指标。大多数内在评估指标需要设置测试集,其中有真实值或标签(即人类标注的正确答案)。
标签可以是二分类的(例如,文 本分类为 0/1)、一两个词(例如,命名实体识别的名称),或者大段文本本身(例如,机 器翻译后的文本)。将自然语言处理模型对数据点的输出与该数据点的对应标签进行比较,并且根据输出与标签之间的匹配(或不匹配)来进行指标计算。对于大多数自然语言处理 任务,比较可以自动化,因此内在评估也可以自动化。对于某些情况,如机器翻译或摘 要,因为不能像人类一样做出主观判断,所以自动化评估并不总是可能的。 表 2-2 列出了用于不同自然语言处理任务的内在评估的各种指标。有关指标的详细讨论, 请参阅相应的参考资料。
表2-2:常用的指标和对应的自然语言处理应用程序
| 指标 | 描述 | 应用程序 |
|---|---|---|
| 准确率 | 当输出变量是分类变量或离散变量时使用。 它表示模型做出正确预测的次数与它所做的预测总数的比率 | 主要用于分类任务,如情感分类(多分类)、自然语言推理(二分类)、释义检测(二分类)等 |
| 精确率 | 显示模型的预测有多精确,即给定所有的正例(所关心的类别),模型能正确分类的有多少 | 用于各种分类任务,特别是正类错误 比负类错误代价更大的情况,例如医疗保健中的疾病预测 |
| 召回率 | 召回率是精确率的补充。它捕捉了模型对正类别的召回程度,即考虑到模型做出的所有正类别预测,其中有多少是真正的正类别 | 用于分类任务,特别是检索正类别结 果更为重要的情况,例如电子商务搜 索和其他信息检索任务 |
| F1 分数 | 结合精确率和召回率给出了一个单一的衡量 指标,这也捕捉了精确率和召回率,即完整 性和准确性之间的权衡 F1 定义为 (2× 精确率 × 召回率 )/( 精确率 + 召回率 ) | 在大多数分类任务中与准确率同时使 用。它还可以用于序列标注任务,如 实体提取、基于检索的问题回答等 |
| ROC 曲线下面积 | 捕获当改变预测阈值时,正确的正预测数与 不正确的正预测数之比 | 用于衡量独立于预测阈值的模型质量。 用于寻找分类任务的最佳预测阈值 |
| MRR(平均排序倒数) | 用于在给定其正确性概率的情况下评估检索 到的响应。它是检索结果排序倒数的平均值 | 大量用于各种信息检索任务,包括文 章搜索、电子商务搜索等 |
| MAP(平均精度均值) | 用于排序检索结果,如 MRR。它计算每个 检索结果的平均精度 | 用于信息检索任务 |
| RMSE(均方根误差) | 捕获模型在实际值预测任务中的性能。计算 每个数据点的均方根误差 | 与 MAPE 一起用于回归问题,例如 温度预测和股价预测 |
| MAPE(平均绝对百分 比误差) | 当输出变量为连续变量时使用。它是每个数 据点的绝对百分比误差的平均值 | 用于测试回归模型的性能,通常与均方根误差一起使用 |
| BLEU(双语评估辅助 指标) | 捕获输出语句和参考语句之间的 n-gram 重 叠度。它有很多变体 | 主要用于机器翻译任务。最近适应于 其他文本生成任务,如释义生成和文 本摘要 |
| METEOR | 一种基于精度的指标,用于衡量生成文本的 质量。它修复了 BLEU 的一些缺点,例如 计算精度时出现的精确词匹配。METEOR 允许同义词和词干与参考词匹配 | 主要用于机器翻译 |
| ROUGE | 还是衡量生成文本相对于参考文本的质量。 和 BLEU 不同,它衡量的是召回率 | 因为衡量的是召回率,所以主要用于 摘要任务。在摘要任务中,评估一个 模型能召回多少词很重要 |
| 困惑度 | 捕捉自然语言处理模型混乱程度的概率指 标。它源于下一个词预测任务中的交叉熵 | 用于评估语言模型。也可用于语言生 成任务,如对话生成 |
除了表 2-2 中列出的指标之外,还有更多的指标和可视化方法,用于解决自然语言处理问 题。虽然这里简要介绍了这些主题,但我们鼓励你根据参考资料,深入了解这些指标。
对于分类任务,一种常用的可视化评估方法是混淆矩阵。它允许我们检查数据集中不同类 别的实际输出和预测输出。混淆矩阵源于这样一个事实,即它有助于理解分类模型在识别 不同类别方面的“混淆”程度。混淆矩阵可以用于计算精确率、召回率、F1 分数和准确率 等指标。第 4 章将展示如何使用混淆矩阵。
像信息搜索和检索这样的排序任务主要使用基于排序的指标,如 MRR 和 MAP,但也可以使用常用的分类指标。在检索任务中,主要关心的是召回率,因此会计算不同排序下的召 回率。例如,对于信息检索,一个常用的指标是“排名前 K 位的召回率”,它会在检索到 的前 K 个结果中寻找真实值是否存在。如果存在,则表示是成功。
当涉及文本生成任务时,根据任务的不同,可以使用多种指标。尽管 BLEU 和 METEOR 对于机器翻译来说是很好的指标,但是将其应用到其他生成任务时,它们可能不是很合 适。例如,在生成对话的情况下,真实值只是正确答案之一,还有很多不同的回答可能没 有列出来。在这种情况下,BLEU 和 METEOR 等基于精确率的指标将完全无法忠实地衡 量任务的性能。基于这些原因,人们广泛使用困惑度来衡量模型的文本生成能力。
然而,任何文本生成的评估方案都不是完美的。这是因为具有相同意思的句子可能有多 个,不可能将所有的变体都列为真实值。因此,生成的文本和真实值可以是不同的句子, 但仍然具有相同的意思。这使得自动化评估变得很难。以法英机器翻译模型为例,考虑 下面这个法语句子,“J’ai mangé trois filberts”。在英语中,这句话的意思是“I ate three filberts”(我吃了三个榛子)。 所以,把这句话作为标签。假设模型生成以下英文翻译,“I ate three hazelnuts”。由于输出与标签不匹配,自动化评估会认为输出不正确。但这种评估是不正确的,因为说英语的人 经常会把 filberts 称为 hazelnuts。即使添加这句话作为一个可能的标签,模型仍然可能生成 “I have eaten three hazelnuts”作为输出。再一次,自动评估会说模型搞错了,因为输出结果与两个标签中的任何一个都不匹配。这里就需要引入人工评估。但是人工评估的时间成 本和金钱成本都很高。
7.2外在评估
如前所述,外在评估侧重于在最终目标上评估模型的性能。
在行业项目中,任何人工智能 模型的构建都是以解决一个商业问题为目的的。例如,构建回归模型的目的是对用户的电 子邮件进行排序,并将最重要的电子邮件放在收件箱的顶部,从而帮助用户节省时间。考虑这样一个场景:回归模型在机器学习指标方面做得很好,但并没有真正为电子邮件用户节省大量时间;或者问题回答模型在内在指标方面做得很好,但无法解决生产环境中的大量问题。这样的模型会被认为是成功的吗?不,因为它们没能实现商业目标。虽然这对学术研究人员来说不是一个问题,但对于从业者来说,这是非常重要的问题。
进行外在评估的方法是在项目开始阶段设置业务指标以及正确衡量这些指标的流程。后面的内容会给出正确业务指标的示例。
你可能会问:如果外在评估很重要,那么为什么还要内在评估呢?
必须在外在评估之前进行内在评估的原因是,外在评估通常包括人工智能团队之外的项目干系人,有时甚至包括最终用户。内在评估大部分可以由人工智能团队自己完成。这使得外在评估比内在评估更加昂贵。因此,内在评估被看作外在评估的指标。只有在内在评估中取得一致的好结果 时,才应该进行外在评估。
另外一件需要记住的事情是,内在评估中的坏结果往往意味着外在评估中的坏结果。但是,反过来未必会成立。也就是说,模型可能会出现好的内在评估和差的外在评估,但不会出现好的外在评估和差的内在评估。外在评估中表现不佳的原因可能有很多,例如设置错误的指标、不具备合适的数据或拥有错误的期望。第 1 章谈到了其中的一些,第 11 章 会有更详细的讨论。
以上介绍了内在评估通用的一些指标,以及外在评估对于衡量自然语言处理模型性能的重要性。还有一些特定于任务的指标,并非所有的自然语言处理应用场景都会用到。接下来 的内容还会在讨论具体应用程序时详细讨论这些评估方法。现在进入流水线的剩余组件: 模型部署、监控和更新。
8.建模之后的阶段
模型经过反复测试之后,就进入建模之后的阶段:模型部署、监控和更新。本节将简要介绍这些内容。
8.1部署
在大多数实际应用场景中,自然语言处理模块只是大系统的一部分(例如,垃圾邮件分类系统属于更大的电子邮件应用程序)。因此,处理、建模和评估流水线只是故事的一部分。 一旦对最终解决方案感到满意,就需要将其作为大系统的一部分部署到生产环境中。部署意味着将自然语言处理模块插入大系统中。部署还意味着要确保输入和输出数据流水线是有序的,并确保自然语言处理模块在高负载下是可扩展的。
自然语言处理模块通常部署为 Web 服务。假如现在设计了一个 Web 服务,它接受文本作为输入,并返回电子邮件的类别(垃圾邮件或非垃圾邮件)作为输出。现在,每当有人收到一封新的电子邮件时,它就会转到微服务,微服务会对电子邮件文本进行分类。这反过来又可以用来决定如何处理电子邮件(直接显示或者发送到垃圾邮件文件夹)。在批处理等特殊情况下,自然语言处理模块需要部署在较大的任务队列中,例如谷歌云或亚马逊云 服务中的任务队列。第 11 章将详细介绍部署。
8.2监控
和任何软件工程项目一样,在最终部署之前必须进行大量的软件测试,并且在部署之后不 断地监控模型性能。由于需要确保模型每天产生的输出是有意义的,因此自然语言处理项 目和模型的监控必须不同于常规的工程项目。如果定期自动训练模型,还必须确保模型产生合理的结果。这在某种程度上可以通过性能仪表盘来实现,性能仪表盘可以显示模型参数和关键性能指标。第 11 章将详细讨论这一点。
8.3模型更新
一旦部署了模型并开始收集新的数据,就可以基于新的数据来迭代模型,以保持预测为最新。本书各章都会涉及每种任务的模型更新,特别是第 4 章到第 7 章和第 11 章。表 2-3 初步介绍了部署之后如何针对不同的场景进行模型更新。
表2-3:项目特点和相应的决策路径
| 项目特点 | 决策路径 | 示例 |
|---|---|---|
| 部署后会生成更多的训练数据 | 一旦部署,提取的信号就可以用来自动改进模型。也可以尝试在线学习,对模型进行日常自动训练 | 基于用户标记数据的滥用检测系统 |
| 部署后不生成训练数据 | 人工标注可以用来改进评估和模型理想情况下,每个新模型都必须手动构建和评估 | 更大自然语言处理流水线的子 集,无直接反馈 |
| 需要较低的模型延迟,或者模型必须在线且响应接近实时 | 需要使用可以快速推断的模型。另外也可以选择创建内存策略,比如缓存,或者使用更强的计算能力 | 需要立即响应的系统,如聊天机器人或紧急跟踪系统 |
| 不需要较低的模型延迟,或者模型可以脱机运行 | 可以使用更高级和更慢的模型。这也有助于在可行的情况下优化成本 | 可以在批处理过程中运行的系统,如零售产品目录分析 |
9.使用其他语言
到目前为止,上述讨论的前提假设是英语文本。根据手头的任务,可能还需要为其他语言 构建模型和解决方案。不同的语言有着不同的处理方式。有些语言的流水线可能与英语非 常相似,而有些语言和场景可能需要重新思考如何处理问题。根据我们在非英语语言处理项目中的工作经验,下面概括了不同语言的处理方案,如表 2-4 所示。
| 语言特点 | 示例和语言 | 处理方案 |
|---|---|---|
| 高资源语言 | 既有充足数据又有预建模型的语言 例如英语、法语和西班牙语 | 可以使用预训练的深度学习模型。更易于使用 |
| 低资源语言 | 数据有限且最近才开始采用数字技术的 语言。可能没有预建模型例如斯瓦希里语、缅甸语和乌兹别克语 | 根据任务的不同,可能需要标注更多的数据以及探索各个组件 |
| 形态丰富 | 语言和语法信息,如主语、宾语、谓语、 时态和语气不是独立的词,而是连接在 一起的例如拉丁语、土耳其语、芬兰语和马拉雅拉姆语 | 如果语言资源不丰富,则需要探索现有的用于该 语言的形态分析器。在最坏的情况下,可能需要人工编写规则来处理某些情况 |
| 词汇变化大 | 拼写不规范,词的变体较多 例如阿拉伯语和印地语没有标准拼写 | 如果语言资源不丰富,那么可能需要在训练任何模型之前首先对词 / 拼写进行规范化 对于具有大型数据集的语言来说,这可能不需要,因为模型仍然可以学习词汇变化 |
| 中文、日文、 韩文(CJK) | 这些语言都是从古代汉字中派生出来的。 它们不是基于字母表的,有几千个字符用于基本识字,全部字符则超过 4 万个。 因此,必须以不同的方式处理这些问题 它们包括中文、日文和韩文,因此得名 “CJK” | 在这些语言中使用特定的分词方案。由于有大量的此类语言数据可用,因此可以从头开始为各种任务构建自然语言处理模型它们也有预训练模型从用 CJK 以外的其他语言训 练的模型中进行迁移学习,在这种情况下可能没有用处 |
接下来是案例研究,它将综合上述所有这些步骤。
10.案例研究
上面介绍了自然语言处理流水线的各个阶段以及每个阶段的原因、作用和加入流水线通用 框架的方式。但是,这些阶段是分开介绍的,脱离了整体背景。在真实的自然语言处理系统流水线中,所有这些阶段是如何协同工作的?下面来看一个案例研究:使用 Uber 的人工智能客服工具 COTA 来改善客户服务。
Uber 在全球 400 多个城市运营,根据每天使用 Uber 的人数,可以估计其客户支持团队每天会收到数十万张关于不同问题的服务单。对于给定的服务单,有两种解决方案可供选择。COTA 的目标是对这些解决方案进行排序,并选择可能的最佳解决方案。Uber 使用机器学习和自然语言处理技术开发了 COTA,以提供更好的客户支持和快速高效的服务单问题解决方案。图 2-15 显示了 Uber COTA 的流水线以及其中的各种自然语言处理组件。
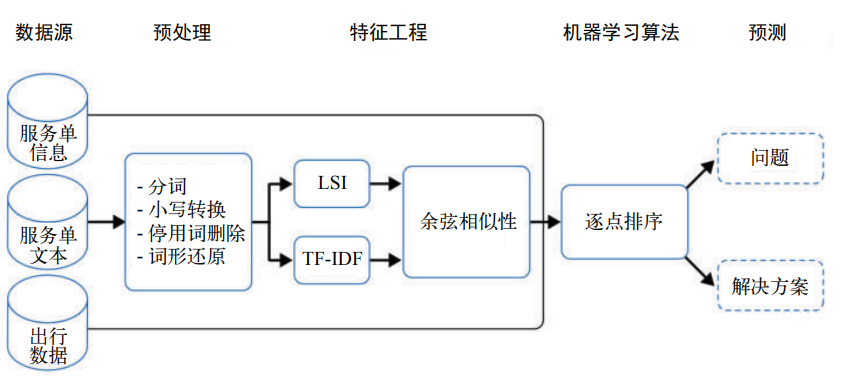
图 2-15:Uber 服务单系统服务单排序的自然语言处理流水线
在该系统中,识别服务单问题并选择解决方案需要三个信息来源,如图 2-15 所示。
服务单文本,顾名思义,就是文本内容,这是自然语言处理发挥作用的地方。通过移除 HTML 标 记(图 2-15 中未显示)来清洗文本后,预处理步骤包括分词、小写转换、停用词删除和词形还原。本章前面已经介绍了如何完成这些步骤。经过预处理后,服务单文本被表示为词的集合(称为词袋,第 3 章将详细讨论)。
流水线的下一步是特征工程。前面获得的词袋进入两个自然语言处理模块:TF-IDF(词 频 – 逆文档频率)和 LSI(潜在语义索引),这两个模块使用词袋表示来理解文本的含义。 这个过程属于主题建模,第 7 章会讨论。那么 Uber 如何在这种背景下使用这些自然语言 处理任务? Uber 在数据库中找到每个解决方案的历史服务单,为每个解决方案形成一个词袋向量表示,并基于这些表示创建一个主题模型。然后,将传入的服务单映射到解决方案的主题空间,为服务单创建一个向量表示。余弦相似性是衡量任意两个向量之间相似度的一种常用方法。它用于创建一个向量,其中每个元素指示服务单文本与某个解决方案的相似度。因此,在特征工程步骤的最后,会得到一个表示,该表示指示服务单文本与所有 可能解决方案的相似性。
下一阶段是建模。在建模过程中,上面得到的表示会与服务单信息和出行数据相结合,构 建一个排名系统,显示服务单的三个最佳解决方案。在排名系统中,排序模型为二分类系 统,它将每个服务单和解决方案的组合分类为匹配或不匹配。然后根据评分函数对多个匹 配项进行排名。
流水线的下一步是评估。在这种情况下,评估是如何工作的?虽然模型性能本身的评估可 以根据内在评估指标(如 MRR)来完成,但是这种方法的总体有效性是通过外在评估判 断的。据估计,COTA 的快速服务单解决方案每年能为 Uber 节省数千万美元。 正如前面所了解到的,一个模型并非只构建一次。COTA 也在不断试验和改进。在探索 了一系列深度学习架构之后,最终选择的最佳解决方案与之前的二分类排序系统相比, 准确率提高了 10%。不过,这一过程并没有就此结束。从 COTA 团队的文章“COTA: Improving Uber Customer Care with NLP & Machine Learning”中可以看到,这个过程是模型部署、监控和更新的连续过程。
11.小结
本章介绍了给定项目描述开发自然语言处理流水线所涉及的各个步骤,并给出了实际应用 程序的详细案例研究。此外,还介绍了传统的自然语言处理流水线和基于深度学习的自然 语言处理流水线的区别,并介绍了非英语语言的处理方法。除了具体的案例研究,本章还 以更一般的方式介绍了这些步骤。每个步骤的具体细节取决于手头的任务和实现的目的。 从第 4 章开始,本书将关注特定于任务的流水线,并详细描述不同任务之间流水线的相同 点和不同点。第 3 章将详细讨论前面提到的文本表示问题。