
RAG 系统Badcase 管理
"开发RAG系统是一道题,运营RAG系统才是真正的考卷。"
今天把 RAG 系统的 Badcase 运营闭环,从收集到分类到修复,系统讲一遍。
为什么上线后的运营比开发更重要
很多人以为RAG系统做好了上线就完事了,但在金融保险这种高风险场景里,上线才是挑战的开始。
我们的项目背景是这样的:一家中型保险公司,把5000份保险合同和理赔文档入库,做了一套RAG问答系统,客户可以直接问"我的车险意外险赔付上限是多少"这类问题。
上线前,我们在自己构造的200条测试集上跑,准确率76%,感觉还不错。
但上线第一周,就出了问题。
一个用户问的是:"我去年出了个小事故,现在理赔会不会影响我续保的价格?"这个问题在我们的测试集里根本没有,检索系统不知道该去找哪份文档,LLM最后给了一个含糊其辞的回答,说"可能会影响,建议咨询客服"。用户打了客服电话,客服查完之后发现明明合同里有清楚的条款,RAG系统就是没检索到。
真实用户的问题分布和我们构造的测试集差异非常大。测试集里的问题都是标准书面语,用户问的是口语化表达,甚至带着方言习惯的句式。
更严重的是合规风险。有一次系统给出了一个错误的赔付金额,比实际合同条款里的数字少了一截。这条badcase被客服捞出来之后,法务部门介入评估了好几天,因为如果用户截图这个答案去理赔,后续可能产生纠纷。
第三个问题是知识库的自然衰老。保险产品会更新,条款会修订,但如果没有机制持续检测,系统给出的还是旧版本的信息,用户拿到的是过期答案。
没有运营闭环的RAG系统,质量只会随时间退化。
明白了为什么,再来看 Badcase 具体是哪几种类型。
Badcase的四种分类
处理badcase的第一步不是立刻去修,而是先弄清楚是哪种问题。不同类型的badcase,修复方向完全不同,混在一起处理只会越改越乱。
我们把所有badcase分成四类。
第一类:检索失败型(约占40%)
这是最常见的失败类型。用户的问题,知识库里明明有答案,但系统就是没检索到。
典型案例:用户问"我老爸骑电动车摔了,能报销不",知识库里有完整的意外伤害险条款,但检索返回的Top5文档里没有一条相关的。
原因有两个:一是Embedding模型对口语化表达的召回很差,"意外险"和"摔了"的语义距离被Embedding拉得很远;二是Chunk切割策略有问题,同一份条款里的关键信息被切成了好几个Chunk,每个Chunk单独看都不够完整,检索的时候没有一个Chunk得分足够高。
修复方向:优化Chunk切割策略(比如按语义边界切,而不是按固定字数切),同时加BM25关键词检索和向量检索做混合召回,两路结果取并集再重排。
第二类:幻觉生成型(约占25%)
这类badcase的检索结果是对的,Top5文档里有正确答案,但LLM生成的回答还是错了。
典型案例:检索到了一份寿险条款,明确写着"身故保险金为基本保额的200%",但LLM给出的答案是"身故保险金为基本保额的150%"。检索对了,生成错了。
原因是LLM的参数知识在作祟。LLM在预训练的时候见过大量保险行业资料,自己"记得"一些数字,当Prompt约束不够强的时候,LLM会把自己记住的内容混进来,而不是老实地从检索文档里提取。
修复方向:在Prompt里加强忠实度约束,明确告诉LLM"只能使用以下文档中的信息,不得引用文档以外的任何知识,如果文档中没有明确说明,必须回答不知道"。同时可以加上引用校验,让LLM在回答里附上原文出处,方便后续核对。
第三类:路由错误型(约占20%)
我们的系统不只有RAG,还有Text2SQL(查保单数据库)和直接回答(一些不需要检索的通用问题)。路由错误型的badcase是:问题本来应该走RAG检索文档,但被分配到了其他处理路径。
典型案例:用户问"我的保单条款里对医疗费报销有什么规定",应该走RAG去检索合同文本,结果被路由到Text2SQL去查数据库,查出来的是一堆数字,完全答非所问。
原因是路由分类模型的训练数据不够丰富,对边界case的判断不准。
修复方向:把路由错误的case整理成新的训练样本,补充到路由分类器的训练数据里,重新微调或重新设计路由Prompt。
第四类:知识缺失型(约占15%)
这类最好处理,知识库里真的没有这个信息。
典型案例:用户问"我的保单支持线上理赔吗,怎么操作",这部分内容确实没有入库,系统只有合同条款文档,操作指南没有。
修复方向:整理需要补充的内容,推动知识运营团队把相关文档加进来。
 RAG系统Badcase四分类及占比
RAG系统Badcase四分类及占比
四类 Badcase 搞清楚了,接下来的问题是:怎么系统性地把它们收集上来?
三路Badcase收集渠道
知道了分类框架,下一步是解决收集问题。靠人工盯着所有对话是不现实的,要建立自动化的收集机制。
我们用了三条渠道并行收集。
第一路:用户反馈按钮
在前端每条回答下面加了两个按钮,一个大拇指朝上(好评),一个大拇指朝下(差评)。用户点了差评之后,这条对话记录自动进入badcase候选队列,同时可以选填一个简短的原因,比如"答案不对"、"没有回答我的问题"、"回答太模糊"。
这条渠道收集的badcase质量参差不齐。有些用户的差评是因为系统回答正确但他不满意(比如赔付条件不符合他的期望),这类属于误踩,需要过滤。但真正的答案错误类badcase通过这条渠道能稳定捕获。
第二路:客服工单
客服人员处理用户投诉的时候,会接触到大量用户因为RAG系统的回答有问题而打来的电话。我们和客服系统做了对接,客服在工单里标记"AI回答问题"的时候,自动触发抓取关联的对话记录。
这条渠道的价值在于:能捞到用户没有点差评、但确实有问题的case。很多用户在移动端不喜欢点按钮,但会打电话投诉。客服工单捞上来的badcase,往往也是影响最大、风险最高的那些。
第三路:自动质量检测
这是最关键的一路,因为前两路都依赖用户的主动行为,覆盖率有限。我们对系统的每一条对话做自动化质量评分,评分低于阈值的自动标记为疑似badcase。
评分逻辑分三个维度:
第一个维度是检索相关性。计算用户问题和Top5检索文档之间的语义相似度,如果最高分都低于0.6,说明检索结果可能不相关。
第二个维度是答案忠实度。用一个轻量级的LLM评判模型,判断生成的答案是否能在检索文档里找到依据。评分低于0.7的进入疑似队列。
第三个维度是关键信息完整性。对于金融问答,如果用户问的是包含具体数字的问题(比如赔付比例、免赔额),但回答里没有具体数字,自动标为疑似badcase。
三路渠道汇总到同一个badcase数据库,每条记录带上来源标签,方便后续分析哪条渠道的质量最高、成本最低。
有了原材料,下一步是怎么自动化地做分类和处理。
自动分类脚本
有了收集到的badcase之后,全靠人工分类效率太低。300条badcase,两个工程师手动分类要花两三天,还容易分类不一致。
我们写了一个自动分类脚本,用LLM来做初步分类,人工只复核高风险case(比如涉及赔付金额的)。
def classify_badcase(query: str, retrieved_docs: list, answer: str) -> dict:
"""用LLM自动分类Badcase类型"""
classification_prompt = f"""
分析以下RAG系统的失败案例,判断失败原因类型:
用户问题:{query}
检索到的文档(Top3):{[d['text'][:200] for d in retrieved_docs[:3]]}
系统回答:{answer}
请判断失败类型(只能选一个):
A. 检索失败:文档里有答案但没检索到
B. 幻觉生成:检索结果正确但LLM生成了错误答案
C. 路由错误:这个问题不该走RAG
D. 知识缺失:知识库里确实没有这个信息
输出JSON:{{"type": "A/B/C/D", "reason": "具体原因", "fix_direction": "修复建议"}}
"""
result = llm.invoke(classification_prompt)
return json.loads(result.content)脚本的核心逻辑是:把用户问题、检索到的Top3文档片段、系统生成的答案三者一起喂给LLM,让LLM做推理判断。
判断逻辑上,LLM会依次检查:检索文档里有没有答案(没有就是D,知识缺失);如果有,答案和检索文档是否一致(不一致就是B,幻觉生成);如果一致,但答案还是错了,就回头看问题分类是否出错(C,路由错误);其余的大概率是A,检索失败。
实测下来,自动分类的准确率在80%左右。对于置信度低的case(LLM给出的reason里带有不确定措辞),我们会单独标记出来做人工复核,大概占总量的15%。
分类完成之后,这些badcase就可以进入完整的运营闭环了。
Badcase处理的运营闭环
收集和分类只是起点,真正的价值在于形成闭环。六步走完一个迭代周期。
第一步:收集
三路渠道汇总到badcase数据库,每天定时跑一次,把前一天的疑似badcase整理进来。重要字段包括:对话ID、用户问题、检索文档、系统回答、来源渠道、收集时间。
第二步:自动分类
每天新进来的badcase跑一遍自动分类脚本,产出四分类标签和修复建议。高风险case(涉及具体赔付金额、条款内容的)单独拉出来,由高级工程师或产品人工复核。
第三步:按类型分配处理
分类完成后,按类型路由到对应团队。检索失败型由检索工程师处理,幻觉生成型由Prompt工程师处理,路由错误型由负责分类模型的人处理,知识缺失型推给知识运营团队。
每个团队对应维护一个自己的todo队列,每周同步一次进度。
第四步:修复验证
每个修复提交之前,必须在触发这个badcase的原始用例上验证通过。这是强制要求,不允许跳过。
验证方式很简单:用修复后的配置,重新跑一遍那条badcase,确认答案从错误变成了正确。
第五步:回归测试
这一步是整个闭环里最容易被忽视、也最关键的环节。
每次修复,除了在原badcase上验证之外,还必须在全量测试集上跑一遍回归,确认修复没有把原来能答对的case搞坏。
这是那位学员在面试里卡壳的那个问题的答案。
def regression_test(old_config: dict, new_config: dict, test_set: list) -> dict:
"""对比新旧配置在测试集上的效果,确保没有退化"""
old_scores = run_evaluation(old_config, test_set)
new_scores = run_evaluation(new_config, test_set)
# 关键指标不能下降
checks = {
"recall@5": new_scores["recall@5"] >= old_scores["recall@5"] - 0.02,
"faithfulness": new_scores["faithfulness"] >= old_scores["faithfulness"] - 0.02,
"answer_accuracy": new_scores["answer_accuracy"] >= old_scores["answer_accuracy"] - 0.02,
}
passed = all(checks.values())
return {
"passed": passed,
"details": checks,
"regression_cases": find_regressions(old_scores, new_scores)
}这里有几个设计细节值得注意。
允许2%的容差(- 0.02)是因为测试集本身有一定的抽样误差,特别是测试集规模还不大的时候,指标的小幅波动不一定是真实的退化。2%是我们根据测试集大小估算的置信区间,实际项目可以根据测试集规模调整。
find_regressions 函数不只输出总体分数,还要定位到具体哪些case发生了退化——原来能答对,现在答错了的。这些case需要单独拿出来和修复团队对齐,搞清楚是修复方向有问题,还是case本身存在模糊性。
三个核心指标分别对应三类风险:recall@5 下降说明检索能力退化,faithfulness 下降说明幻觉风险上升,answer_accuracy 下降是最直接的整体质量退化。
第六步:灰度发布
回归测试通过之后,不直接全量发布。先发布给10%的用户,灰度观察一周。观察指标包括:差评率有没有上升、客服工单里有没有新的问题模式出现、自动质量评分的分布有没有变化。
一周无异常,再扩展到全量。
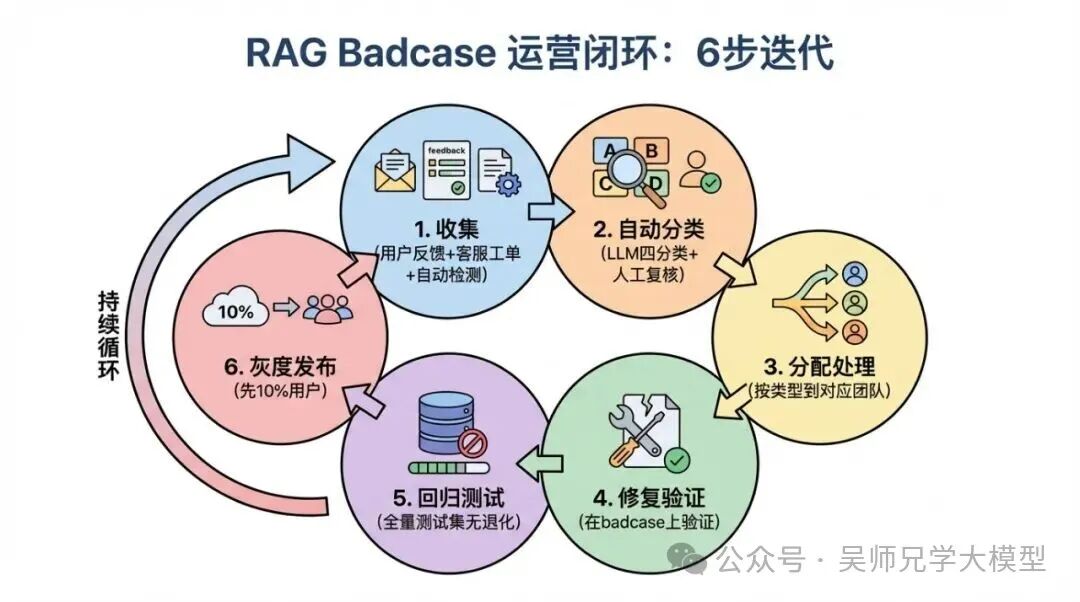 RAG Badcase 运营闭环6步迭代
RAG Badcase 运营闭环6步迭代
上线6个月的实战数据
闭环建立之后,效果是可以量化的。
上线第1个月,三路收集渠道还没有完全建立,只有用户反馈按钮在工作。那个月每周收到的badcase大约50条,但我们的处理方式还是人工看、人工分类、直接修复,没有回归测试,改一个坏一个的情况出现了好几次。
第2个月,建立了自动分类脚本和客服工单对接,同时引入了回归测试流程。badcase处理速度提升了,但每周新增的量还在高位,大约40条左右。这个月的主要工作是把积压的badcase处理完。
第3个月,自动质量检测的第三路渠道上线,三路收集全部就位。更重要的是,经过前两个月的密集修复,系统的主要漏洞已经补得差不多了,每周新增badcase降到了15条左右。
到第6个月,系统整体答案准确率从上线时的76%提升到了89%。累计处理badcase 300条,测试集从最初的200条扩充到了350条,其中150条直接来自真实badcase——这些来自真实用户的case,比我们自己构造的测试集质量更高,更贴近真实分布。
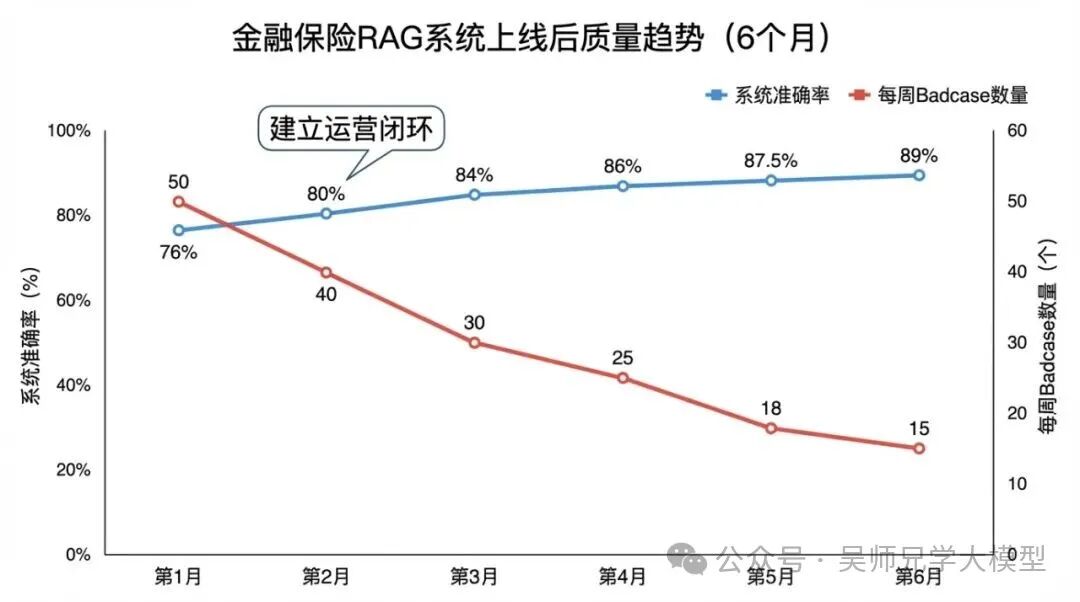 金融保险RAG系统质量趋势
金融保险RAG系统质量趋势
面试怎么答 Badcase 运营?
在面试里,如果被问到"RAG上线后你们怎么做Badcase运营",答案要覆盖四个层次,缺一个都显得不完整。
第一层:说清楚收集
不要只说"收集用户反馈",要说三路并行:用户按钮反馈、客服工单对接、自动质量评分检测。三路渠道的覆盖面不同,用户反馈是主动信号,客服工单是高价值信号,自动检测是覆盖最广的被动信号。
第二层:说清楚分类
说出四分类框架,检索失败型、幻觉生成型、路由错误型、知识缺失型,并且说出每种类型的修复方向不同,分类的目的是让修复有针对性。如果还能提到用LLM做自动分类、人工复核高风险case,会大幅加分。
第三层:说清楚验证
修复之后的验证分两步:先在原badcase上验证通过,再跑全量回归测试。回归测试要说出具体指标:recall@5、faithfulness、answer_accuracy,以及2%的容差设计和退化case的定位机制。
第四层:说清楚闭环
从收集到灰度发布的六步流程,强调这是一个持续迭代的机制,不是一次性的修复动作。可以带上数据:我们用这套机制,6个月把准确率从76%提升到了89%,每周badcase数量从50条降到了15条。
一个可以带到面试里用的答题框架:
"我们建立了三路badcase收集渠道(用户反馈、客服工单、自动检测),用四分类框架(检索失败、幻觉生成、路由错误、知识缺失)对badcase分类,按类型分配给对应团队处理。每次修复之后,先在原badcase上验证通过,再跑全量回归测试,确认三个核心指标没有退化超过2%,最后通过10%灰度发布上线。6个月的实践证明,这套机制把系统准确率从76%提升到了89%。"
这个答案覆盖了四个层次,有具体机制,有数据支撑,有工程细节,面试官听完基本上没有追问空间了。
总结
RAG系统的核心竞争力不在于上线那一刻的效果,而在于上线之后持续迭代的能力。
从我们项目的经验来看,上线后的运营要做好三件事:建立稳定的Badcase收集机制(三路渠道缺一不可);建立科学的分类框架(四分类对应四种修复路径);建立严格的回归测试(防止改好一个、破坏一片)。
最容易被忽视的是第三件事。很多团队在面对用户投诉的压力下,修复动作很快,但没有系统地做回归验证,结果陷入"改了这个、坏了那个"的循环,整体质量始终提不上去。
而真正形成运营闭环之后,badcase本身会变成最宝贵的资产——它们来自真实用户,覆盖了测试集里没有的case,补充进测试集之后,系统的评估质量也会持续提升。