
使用训练工具
在本章中将使用一个情感分类任务的例子来再训练一个模型,以此来讲解HuggingFace训练工具的使用方法。
#第6章/加载编码工具tokenizer
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('../models/rbt3')
tokenizerBertTokenizerFast(name_or_path='../models/rbt3', vocab_size=21128, model_max_length=1000000000000000019884624838656, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}, clean_up_tokenization_spaces=True), added_tokens_decoder={
0: AddedToken("[PAD]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100: AddedToken("[UNK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
101: AddedToken("[CLS]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
102: AddedToken("[SEP]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
103: AddedToken("[MASK]", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}#第6章/试编码句子
tokenizer.batch_encode_plus(
['明月装饰了你的窗子', '你装饰了别人的梦'],
truncation=True,
)Asking to truncate to max_length but no maximum length is provided and the model has no predefined maximum length. Default to no truncation.
{'input_ids': [[101, 3209, 3299, 6163, 7652, 749, 872, 4638, 4970, 2094, 102], [101, 872, 6163, 7652, 749, 1166, 782, 4638, 3457, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}#第6章/从磁盘加载数据集
from datasets import load_from_disk
dataset = load_from_disk('./data/ChnSentiCorp')
#缩小数据规模,便于测试
dataset['train'] = dataset['train'].shuffle().select(range(2000))
dataset['test'] = dataset['test'].shuffle().select(range(100))
datasetDatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 0
})
test: Dataset({
features: ['text', 'label'],
num_rows: 100
})
})- 在这段代码中,对数据集进行了采样,目的有以下两方面:
- 便于测试;
- 模拟在训练集的体量较小的情况,以验证即使是小的数据集,也能通过迁移学习得到一个较好的训练结果
- 可见训练集的数量仅有2000条,测试集的数量有1000条。
- 现在的数据集还是文本数据,使用编码工具把这些抽象的文字编码成计算机善于处理的数字,代码如下:
#第6章/编码
def f(data):
return tokenizer.batch_encode_plus(data['text'], truncation=True)
dataset = dataset.map(f,
batched=True,
batch_size=1000,
num_proc=4,
remove_columns=['text'])
datasetMap (num_proc=4): 0%| | 0/2000 [00:00, ? examples/s]
Map (num_proc=4): 0%| | 0/100 [00:00, ? examples/s]
DatasetDict({
train: Dataset({
features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 2000
})
validation: Dataset({
features: ['label'],
num_rows: 0
})
test: Dataset({
features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 100
})
})在这段代码中,使用了批量处理的技巧,能够加快计算的速度。
- 参数batched=True: 表明使用批量来处理数据,而不是一条一条的处理;
- 参数batch_size=1000: 表明每个批次有1000条数据;
- 参数num_proc=4: 表明使用4个线程进行操作;
- 参数remove_columns=['text']:表明映射结束后删除数据及中的text字段
#第6章/移除太长的句子
def f(data):
return [len(i) <= 512 for i in data['input_ids']]
dataset = dataset.filter(f, batched=True, batch_size=1000, num_proc=4)
datasetFilter (num_proc=4): 0%| | 0/2000 [00:00, ? examples/s]
Filter (num_proc=4): 0%| | 0/100 [00:00, ? examples/s]
DatasetDict({
train: Dataset({
features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 1973
})
validation: Dataset({
features: ['label'],
num_rows: 0
})
test: Dataset({
features: ['label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 97
})
})定义模型和训练工具
#第6章/加载预训练模型
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained('../models/rbt3',
num_labels=2)
#统计模型参数量
sum([i.nelement() for i in model.parameters()]) / 10000Some weights of BertForSequenceClassification were not initialized from the model checkpoint at ../models/rbt3 and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
3847.8338如前所述,此处加载的模型应该和编码工具配对使用,所以此处加载的模型为hfl/rb3模型,该模型由哈尔滨工业大学讯飞联合实验室(HFL)分享到HuggingFace模型库,这是一个基于中文文本数据训练的BERT模型。后续将使用准备好的数据集对该模型进行再训练,再代码的最后一行统计了该模型的参数量,以大致衡量一个模型的体量大小。该模型的参数量约为3800万个,这是一个较小的模型。
#第6章/模型试算
import torch
#模拟一批数据
data = {
'input_ids': torch.ones(4, 10, dtype=torch.long),
'token_type_ids': torch.ones(4, 10, dtype=torch.long),
'attention_mask': torch.ones(4, 10, dtype=torch.long),
'labels': torch.ones(4, dtype=torch.long)
}
#模型试算
out = model(**data)
out['loss'], out['logits'].shape(tensor(0.8869, grad_fn=), torch.Size([4, 2])) 模型的输出主要包括两个部分,一部分是loss,另一部分是logits。对于不同的模型,输出的内容也会不一样,但一般会包括los,所以在使用HuggingFace模型时,不需要自行计算loss,而时模型自行封装,这方便了模型的再训练。
# #第6章/加载评价指标
# import os
# os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
# from datasets import load_metric
# metric = load_metric('accuracy')由于模型计算的输出和评价指标要求的输入还有差别,所以需要定义一个转换函数,把模型计算的输出转换成评价指标可以计算的数据类型,这个函数就是在训练过程真正得到的评价函数,代码如下:
#第6章/定义评价函数
import numpy as np
from transformers.trainer_utils import EvalPrediction
def compute_metrics(eval_pred):
logits, labels = eval_pred
logits = logits.argmax(axis=1)
return {'accuracy': (logits == labels).sum() / len(labels)}
#return metric.compute(predictions=logits, references=labels)
#模拟输出
eval_pred = EvalPrediction(
predictions=np.array([[0, 1], [2, 3], [4, 5], [6, 7]]),
label_ids=np.array([1, 1, 0, 1]),
)
compute_metrics(eval_pred){'accuracy': 0.75}定义训练超参数
在开始训练之前,需要定义好超参数,HuggingFace使用TrainingArgument对象来封装参数,代码如下:
#第6章/定义训练参数
from transformers import TrainingArguments
import tensorflow as tf
#定义训练参数
args = TrainingArguments(
#定义临时数据保存路径
output_dir='./output_dir',
#定义测试执行的策略,可取值no、epoch、steps
evaluation_strategy='steps',
#定义每隔多少个step执行一次测试
eval_steps=30,
#定义模型保存策略,可取值no、epoch、steps
save_strategy='steps',
#定义每隔多少个step保存一次
save_steps=30,
#定义共训练几个轮次
num_train_epochs=1,
#定义学习率
learning_rate=1e-4,
#加入参数权重衰减,防止过拟合
weight_decay=1e-2,
#定义测试和训练时的批次大小
per_device_eval_batch_size=16,
per_device_train_batch_size=16,
#定义是否要使用gpu训练
no_cuda=False,
)2024-07-13 00:25:45.296917: I tensorflow/core/util/port.cc:113] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable TF_ENABLE_ONEDNN_OPTS=0.
2024-07-13 00:25:45.548390: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-07-13 00:25:45.548432: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-07-13 00:25:45.590491: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2024-07-13 00:25:45.678285: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2024-07-13 00:25:46.644895: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
/root/anaconda3/lib/python3.11/site-packages/transformers/training_args.py:1494: FutureWarning: evaluation_strategy is deprecated and will be removed in version 4.46 of 🤗 Transformers. Use eval_strategy instead
warnings.warn(TrainingArguments对象中可以封装的超参数很多,但除了output_dir之外的其他超参数均有默认值,在上面的示例代码中只给出了常用的参数,对于初学者建议从这些简单的参数开始调试,完整的参数列表可以参照HuggingFace官方文档。
定义训练器
完成了上面的准备工作,现在可以定义训练器,代码如下:
#第6章/定义训练器
from transformers import Trainer
from transformers.data.data_collator import DataCollatorWithPadding
#定义训练器
trainer = Trainer(
model=model,
args=args,
train_dataset=dataset['train'],
eval_dataset=dataset['test'],
compute_metrics=compute_metrics,
data_collator=DataCollatorWithPadding(tokenizer),
)定义训练器需要传递的模型,超参数对象,训练和验证数据集,评价函数,以及数据整理函数。
整理函数介绍
数据整理函数使用了HuggingFace提供的DataCollatorWithPadding对象,它能把一个批次中长短不一的句子,补充成统一的长度,长度取决于这个批次中最长的句子有多长,所有数据的长度一致后即可转换成矩阵,模型期待的数据类型也是矩阵,所以经过数据整理函数的处理之后,数据即被整理成模型可以直接计算的矩阵格式。可以通过下面的例子验证,代码如下:
#第6章/测试数据整理函数
data_collator = DataCollatorWithPadding(tokenizer)
#获取一批数据
data = dataset['train'][:5]
#输出这些句子的长度
for i in data['input_ids']:
print(len(i))
#调用数据整理函数
data = data_collator(data)
#查看整理后的数据
for k, v in data.items():
print(k, v.shape)82
186
326
47
71
input_ids torch.Size([5, 326])
token_type_ids torch.Size([5, 326])
attention_mask torch.Size([5, 326])
labels torch.Size([5])在这段代码中,首先初始化了一个DataCollatorWithPadding对象作为数据整理函数,然后从训练集中获取了5条数据作为一批数据,从输出可以看出这些句子有长有短,之后使用数据整理函数处理这批数据,得到的结果再输出形状,可以看到这些数据已经被整理成同意的长度,长度取决于这批句子中最长的句子,并且被转换为矩阵形式。
tokenizer.decode(data['input_ids'][0])'[CLS] 此 款 机 子 不 为 windows xp 设 计 。 装 机 ( xp ) 比 较 麻 烦 , 折 腾 了 一 天 总 算 搞 定 。 不 过 还 是 留 有 不 足 , 就 是 声 音 有 时 有 [UNK] 扑 扑 [UNK] 声 响 。 主 要 还 是 不 兼 容 的 原 因 , 现 在 就 这 么 用 着 吧 , 以 后 再 升 级 。 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]'可以看到,数据整理函数是通过对句子的尾部补充PAD来对句子补长的。
训练和测试
1.训练模型
在开始训练之前,不妨直接对模型进行一次测试,先定下训练前的基准,在训练结束后再对比这里得到的基准,以验证训练的有效性,代码如下:
#第6章/评价模型
trainer.evaluate()
{'eval_loss': 0.702571451663971,
'eval_accuracy': 0.5360824742268041,
'eval_runtime': 0.6406,
'eval_samples_per_second': 151.43,
'eval_steps_per_second': 10.928}可见模型在训练之前,有41%的准确率。由于使用的二分类训练集,所以41%的正确率近乎于瞎猜。这符合预期,因为模型还没有训练,接下来对模型进行训练,期待它能超过此处得到的成绩。
对模型进行训练,代码如下:
#第6章/训练
trainer.train()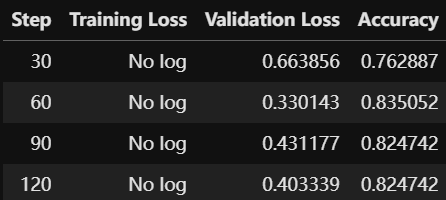
TrainOutput(global_step=124, training_loss=0.4607375975578062, metrics={'train_runtime': 18.6753, 'train_samples_per_second': 105.648, 'train_steps_per_second': 6.64, 'total_flos': 69630349836324.0, 'train_loss': 0.4607375975578062, 'epoch': 1.0})#第6章/从某个存档继续训练
trainer.train(resume_from_checkpoint='./output_dir/checkpoint-90')
TrainOutput(global_step=124, training_loss=0.09972453886462797, metrics={'train_runtime': 5.0666, 'train_samples_per_second': 389.415, 'train_steps_per_second': 24.474, 'total_flos': 69630349836324.0, 'train_loss': 0.09972453886462797, 'epoch': 1.0})#第6章/评价模型
trainer.evaluate()
{'eval_loss': 0.4022093713283539,
'eval_accuracy': 0.8247422680412371,
'eval_runtime': 0.2265,
'eval_samples_per_second': 428.175,
'eval_steps_per_second': 30.899,
'epoch': 1.0}#第6章/手动保存模型参数
trainer.save_model(output_dir='./output_dir/save_model')#第6章/手动加载模型参数
import torch
from safetensors.torch import load_file
# model.load_state_dict(torch.load('./output_dir/save_model/model.safetensors'))
# 加载safetensors文件
state_dict = load_file('./output_dir/save_model/model.safetensors')
# 创建模型实例(这里假设你已经定义了模型类)
# model = YourModelClass()
# 将状态字典加载到模型中
model.load_state_dict(state_dict)
# 确保模型在正确的设备上
model = model.to('cuda') if torch.cuda.is_available() else model2.测试模型
在下面的代码中,首先把模型切换到运行模型,然后从测试集中获取一个批次的数据用于预测,之后把这批数据输入模型进行计算,得出的结果即为模型预测的结果,最后输出前四句的结果,并与真实的label进行比较。
#第6章/测试
model.eval()
for i, data in enumerate(trainer.get_eval_dataloader()):
break
for k, v in data.items():
data[k] = v.to('cuda')
out = model(**data)
out = out['logits'].argmax(dim=1)
for i in range(16):
print(tokenizer.decode(data['input_ids'][i], skip_special_tokens=True))
print('label=', data['labels'][i].item())
print('predict=', out[i].item())住 的 是 江 景 房 , 房 间 超 大 , 环 境 一 流 , 价 钱 不 算 高 ( 258 元 包 2 早 ) , 美 中 不 足 是 服 务 有 点 跟 不 上 , 总 体 不 错 。
label= 1
predict= 1
抢 购 到 的 本 本 , 性 价 比 超 高 , 因 为 自 己 已 有 本 本 , 买 个 人 情 , 让 给 了 同 事 。
label= 1
predict= 1
集 成 显 卡, 玩 使 命 召 唤 5 等 要 求 很 高 的 游 戏 比 较 卡, 没 有 高 清 输 出, 用 料 没 有 以 前 老 款 结 实 了
label= 0
predict= 0
河 南 人 就 是 河 南 人 ! 不 被 懵 一 次 , 那 算 白 来 一 回 ; 在 全 国 乃 至 全 世 界 那 种 叫 做 经 济 房 的 房 间 , 在 河 南 济 源 雅 士 达 叫 做 贵 宾 楼 , 真 够 逗 的 ! ! !
label= 0
predict= 0
房 间 装 修 差 设 施 也 不 好, 早 餐 很 一 般. 位 置 偏 僻.
label= 0
predict= 0
以 前 在 《 女 人 我 最 大 》 节 目 中 最 爱 看 kevin 老 师 参 予 的 节 目 , 每 次 看 他 对 彩 妆 的 讲 解 , 自 己 总 有 收 获 。 而 且 听 他 对 彩 妆 的 介 绍 , 总 是 浅 显 易 懂 , 而 他 给 人 的 感 觉 是 那 么 热 心 地 要 把 自 己 所 知 道 的 护 肤 和 彩 妆 的 知 识 毫 不 吝 啬 地 教 给 大 家 。 昨 天 一 拿 到 书 我 就 迫 不 及 待 地 开 始 了 新 一 轮 的 学 习 , 呵 呵 又 收 获 了 一 些 护 肤 的 小 知 识 。 而 且 我 非 常 喜 欢 整 本 书 的 编 排 , 当 然 要 是 kevin 老 师 再 出 一 个 dvd 特 辑 跟 书 一 起 卖 就 更 好 了 。
label= 1
predict= 1
我 的 订 单 是 7 月 17 日 就 发 出 来 了 , 但 是 现 在 是 8 月 2 日 , 我 还 没 有 收 到 货 。 怎 么 发 评 论 呢 ? 订 单 上 有 电 话 呀 , 即 使 找 不 到 地 址 , 打 个 电 话 问 一 下 呀 , 到 底 是 出 在 什 么 地 方 , 希 望 贵 网 好 好 查 一 下 , 避 免 以 后 再 出 现 这 样 的 问 题 。
label= 0
predict= 0
我 于 6 月 1 日 再 次 入 住, 住 的 是 1312 房, 首 先 价 格 由 238 元 涨 到 278 元, 是 整 个 乌 鲁 木 齐 酒 店 旺 季 都 涨 了, 据 说 每 年 7 月 和 8 月 乌 鲁 木 齐 酒 店 都 还 要 涨, 这 也 可 以 理 解, 毕 竟 就 那 么 几 个 月 可 以 赚 钱, 冬 天 都 是 零 下 20 几 度, 人 很 少. 但 是 我 发 现 房 间 的 迷 你 吧 撤 了, 只 有 留 了 两 瓶 矿 泉 水. 卫
label= 0
predict= 0
无 预 装 系 统 , 且 主 板 bios 没 有 打 入 slic 证 书 , 因 此 不 能 激 活 oem 版 vista , 造 成 vista 无 法 使 用 。 换 了 几 个 版 本 vista 和 激 活 工 具 都 没 有 拿 下 vista , 我 会 再 试 , 也 请 成 功 安 装 vista 的 朋 友 指 教
label= 0
predict= 0
为 了 白 彦 的 死 , 伤 心 了 好 久 。 很 久 没 有 为 了 一 本 书 。 为 了 一 本 书 里 那 些 如 此 贴 近 生 活 的 文 字 而 感 动 伤 心 了 。 喜 欢 宁 默 的 潇 洒 , 刚 开 始 的 时 候 还 在 为 他 们 两 个 在 面 对 爱 情 时 的 清 醒 而 不 解 。 最 后 直 到 白 彦 意 外 死 后 出 现 的 地 图 , 宁 默 的 反 应 。 才 知 道 原 来 他 们 都 爱 彼 此 爱 的 那 么 深 。 。 。 。 想 起 了 宁 默 那 句 话 , 她 跟 梁 葳 葳 说 她 宁 愿 输 给 她 , 输 给 任 何 人 也 不 想 输 给 生 离 死 别 。 。 。 。
label= 1
predict= 1
98 年 这 家 酒 店 开 业 时 住 过 , 感 觉 很 好 , 今 年 去 青 岛 还 是 选 择 了 住 在 这 里 . 10 年 过 去 了 , 虽 然 硬 件 略 显 陈 旧 但 服 务 水 平 依 旧 让 我 感 觉 很 满 意 .
label= 1
predict= 1
还 稍 微 重 了 点 , 可 能 是 硬 盘 大 的 原 故 , 还 要 再 轻 半 斤 就 好 了 。 其 他 要 进 一 步 验 证 。 贴 的 几 种 膜 气 泡 较 多 , 用 不 了 多 久 就 要 更 换 了 , 屏 幕 膜 稍 好 点 , 但 比 没 有 要 强 多 了 。 建 议 配 赠 几 张 膜 让 用 用 户 自 己 贴 。
label= 0
predict= 0
看 到 这 本 书 给 我 的 第 一 感 觉 是 : 相 见 恨 晚 ! 以 前 总 以 为 自 己 什 么 都 看 得 开 、 什 么 都 很 懂 、 什 么 都 不 在 乎 。 可 在 看 这 本 书 的 过 程 中 , 我 感 到 自 己 真 得 是 什 么 都 不 懂 , 特 别 是 在 做 人 方 面 很 欠 缺 。 钱 教 授 以 前 在 百 家 讲 坛 讲 解 玄 藏 时 , 我 就 感 到 他 很 亲 切 , 特 别 是 一 些 道 理 讲 得 很 通 俗 易 懂 。 这 次 讲 解 三 字 经 更 是 一 个 难 得 的 学 习 机 会 , 虽 然 这 本 书 我 还 没 有 看 完 , 但 我 已 经 被 深 深 地 吸 引 住 了 , 希 望 大 家 也 能 从 中 有 所 感 悟 。
label= 1
predict= 1
做 工 扎 实 , 按 键 设 计 很 人 性 化 , 散 热 很 好 , 带 有 正 版 系 统 让 人 用 着 有 点 名 正 言 顺 的 感 觉 。 完 美 屏 , 很 像 镜 面 屏 。 这 款 是 带 有 麦 克 风 的 , 好 像 参 数 里 没 写 , 有 点 惊 喜 。 解 压 系 统 很 快 , 加 装 内 存 也 方 便 , 拆 了 两 个 螺 丝 抠 下 后 盖 就 可 以 插 了 , 说 明 书 里 有 图 解 。 赞 一 下 京 东 送 到 赠 品 : thinkpad 原 装 包 包 我 超 喜 欢 , 第 一 次 拥 有 这 么 设 计 人 性 化 的 包 包 ; 三 星 内 存 条 1g , 很 容 易 安 装 , 弥 补 了 本 本 内 存 小 的 缺 陷 ; thinkpad 小 黑 鼠 标 , 好 用 可 爱 ;
label= 1
predict= 1
贾 志 刚 是 有 才 的 , 所 以 写 了 春 秋 , 但 人 嘛 就 向 春 秋 那 样 乱 , 不 对 , 说 错 了 ! 应 该 说 , 人 心 嘛 , 就 像 春 秋 那 样 乱 。 所 以 《 春 秋 》 一 出 , 赞 弹 皆 有 , 其 实 贾 志 刚 说 得 对 , 不 看 春 秋 , 连 祖 宗 姓 什 么 都 不 知 道 呢 ! 虽 然 书 中 句 子 略 有 不 雅 , 就 是 俗 了 点 , 但 俗 容 易 看 明 白 。 如 果 写 书 的 都 整 点 文 言 文 或 者 为 不 俗 , 故 意 转 弯 没 角 , 春 秋 不 用 写 了 , 也 不 用 看 了 , 祖 宗 也 不 用 理 了 ! 所 以 春 秋 要 看 , 不 管 他 写 得 俗 不 俗 。
label= 1
predict= 0
硬 件 很 好, 服 务 质 量 也 很 好, 特 别 是 酒 店 周 围 环 境 非 常 优 雅. 早 餐 也 不 错, 下 次 去 还 会 入 住
label= 1
predict= 1从测试结果上来看,有一些错误,但大部分预测是正确的。