
区别
在神经网络中,代价函数(Cost Function)和损失函数(Loss Function)并不完全是同一个概念,但它们紧密相关,并且在某些上下文中可能会被混用。
损失函数通常是指单个训练样本的误差度量,用于量化模型预测与实际标签之间的差距。它表示神经网络对单个数据点的拟合程度。对于每个样本,我们都会计算一个损失值。在机器学习的任务中,常用的损失函数有均方误差(Mean Squared Error, MSE)用于回归任务,交叉熵损失(Cross-Entropy Loss)用于分类任务等。
代价函数则是损失函数在整个训练集上的平均值(或总和),它量化了模型在整个训练数据集上的总体性能。也就是说,代价函数是对整个数据集所有样本损失的一个汇总。通过最小化代价函数,我们可以优化神经网络的权重和偏置,从而使得模型在整个数据集上的预测性能得到提升。
简而言之,损失函数是针对单个样本的误差度量,而代价函数是针对整个训练集的总体误差度量。在实际应用中,这两者经常被一起使用来指导神经网络的训练过程,并且某些文献或资料中可能会将这两者视为同义词。不过,在严谨的上下文中,区分这两者是有帮助的。
损失函数
1、什么是损失函数
- 损失函数(loss function)或代价函数(cost function)是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。
- 神经网络以某个指标为线索寻找最优权重参数。神经网络的学习中所用的指标称为损失函数(loss function)。这个损失函数可以使用任意函数,但一般用均方误差和交叉熵误差等。
- 损失函数是表示神经网络性能的“恶劣程度”的指标,即当前的神经网络对监督数据在多大程度上不拟合,在多大程度上不一致。
这是文心一言说的,我看了其他的文章和书籍,使用比较混乱,还是看上下文。2、均方误差(MSE)
二次代价函数

- yk是表示神经网络的输出,tk表示监督数据,k表示数据的维数。
- 神经网络的输出y是激活函数的输出,其中softmax函数的输出为概率的输出。t是监督数据,将正确解标签设为1,其他均设为0。将正确解标签表示为1,其他标签表示为0的表示方法称为one-hot表示。
- 均方误差会计算神经网络的输出和正确解监督数据的各个元素之差的平方,再求总和。
3、交叉熵误差(cross_entropy_error)
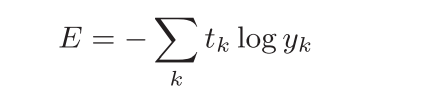
- log表示以e为底数的自然对数(log e)。yk是神经网络的输出,tk是正确解标签。并且,tk中只有正确解标签的索引为1,其他均为0(one-hot表示)。
- 交叉熵误差的值是由正确解标签所对应的输出结果决定的。
4、mini-batch学习
- 计算损失函数时必须将所有的训练数据作为对象。也就是说,如果训练数据有100个的话,我们就要把这100个损失函数的总和作为学习的指标。
- 比如,从60000个训练数据中随机选择100笔,再用这100笔数据进行学习。这种学习方式称为mini-batch学习。
5、mini-batch版交叉熵误差的实现
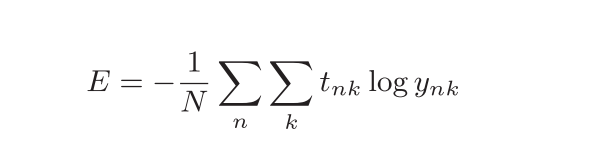
- 求单个数据的交叉熵误差时,需要改变数据的形状。并且,当输入为mini-batch时,要用batch的个数进行正规化,计算单个数据的平均交叉熵误差。
6、设置损失函数的原因
- 在神经网络的学习中,寻找最优参数(权重和偏置)时,要寻找使损失函数的值尽可能小的参数。为了找到使损失函数的值尽可能小的地方,需要计算参数的导数(确切地讲是梯度),然后以这个导数为指引,逐步更新参数的值。
- 在进行神经网络的学习时,不能将识别精度作为指标。因为如果以识别精度为指标,则参数的导数在绝大多数地方都会变为0。
- 识别精度对微小的参数变化基本上没有什么反应,即便有反应,它的值也是不连续地、突然地变化(与阶跃函数类似)。