
AST自动化JavaScript防护方案
没有特别说明的情况下,都以处理以下代码为例:
Date.prototype.format = function (formatStr){
var str = formatStr
var Week = ['日', '一','二','三','四','五','六']
str = str.replace(/yyyy|YYYY/, this.getFullYear())
str = str.replace(/MM/, (this.getMonth()+1)>9 ? (this.getMonth()+1).toString() : '0' + (this.getMonth() + 1));
str = str.replace(/dd|DD/, this.getDate() >9 ? this.getDate().toString() : '0' + this.getDate());
return str;
}
console.log(new Date().format('yyyy-MM-dd'));一、混淆前的代码处理
1.改变对象属性的访问方式
对象属性访间方式有两种,即类似 console.log 或者 console["log"]。在JS 混淆中通常会使用类似这种 console["log"]的对象属性访问方式。

那么,两种访问方式在 AST 节点中又有什么区别呢?
下面介绍两种访问方式在AST节点中的区别,示例如下:
traverse(ast, {
MemberExpression(path) {
console.log(path.node)
}
});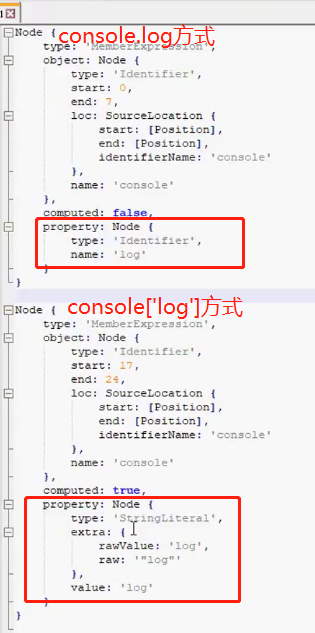
可以看出主要有两处不一样:
console.log 这种访问方式的 property 为 Identifier,computed为false。
console["log"]这种访问式property为StringLiteral,computed为 true。
可以再看一个比较:
因此,只要遍历MemberExpression (成员表达式),把对应的属性修改掉即可完成两种访间方式的转换。
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
traverse(ast, {
MemberExpression(path){
if(t.isIdentifier(path.node.property)){
let name = path.node.property.name;
path.node.property = t.stringLiteral(name);
}
//*这行代码必加
path.node.computed = true;
},
});
let code = generator(ast).code;
fs.writeFile('./demoNew.js', code, (err)=>{});注意,混淆之前的代码中,可能两种访问方式都有,不一定都是 console.log这种方式因此修改property 属性的时候要判断一下,只处理类型为 Identifier 的情况即可。
path.node.computed = true;不加后的结果:
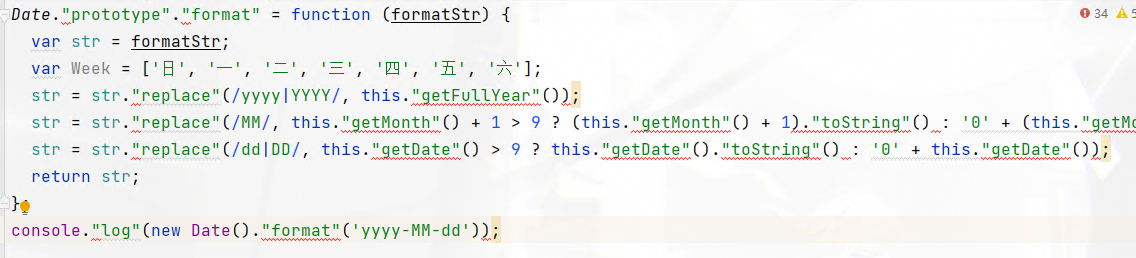
此刻船新版本:
Date.prototype.format = function (formatStr){
var str = formatStr
var Week = ['日', '一','二','三','四','五','六']
str = str.replace(/yyyy|YYYY/, this.getFullYear())
str = str.replace(/MM/, (this.getMonth()+1)>9 ? (this.getMonth()+1).toString() : '0' + (this.getMonth() + 1));
str = str.replace(/dd|DD/, this.getDate() >9 ? this.getDate().toString() : '0' + this.getDate());
return str;
}
console.log(new Date().format('yyyy-MM-dd'));
/*
变化如下:
*/
Date["prototype"]["format"] = function (formatStr) {
var str = formatStr;
var Week = ['日', '一', '二', '三', '四', '五', '六'];
str = str["replace"](/yyyy|YYYY/, this["getFullYear"]());
str = str["replace"](/MM/, this["getMonth"]() + 1 > 9 ? (this["getMonth"]() + 1)["toString"]() : '0' + (this["getMonth"]() + 1));
str = str["replace"](/dd|DD/, this["getDate"]() > 9 ? this["getDate"]()["toString"]() : '0' + this["getDate"]());
return str;
};
console["log"](new Date()["format"]('yyyy-MM-dd'));加密代码如下:
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
// 1.改变对象属性的访问方式 console.log => console['log']
traverse(ast, {
MemberExpression: function (path) {
if(t.isIdentifier(path.node.property)){
let name = path.node.property.name;
path.node.property = t.stringLiteral(name);
}
path.node.computed = true
}
})
// 更新AST ——似乎也不需要更新,已经被遍历过了
// ast = generatorObj(ast);
let code = generator(ast).code;
console.log(code)
fs.writeFile('./demoNew.js', code, (err)=>{});2.JS标准内置对象的处理
在经过改变访问方式后的代码中,可以看到有两个 Date,这是JS 中的标准内置对象,读者们也可以理解成是系统函数。也就是想要使用就必须是这个名字,必须这么写,那是否就不能对Date进行加密了呢?在之前的章节中介绍过,内置对象一般都是 window 下的属性因此可以转成window["Date"]这种形式来访问Date,这样Date 就是一个字符串,就可以进行加密了。另外,还有一些系统自带的全局函数,它们也就是 window 下的方法,可以一并处理。
JS 发展到现在,标准内置对象已经有很多了。笔者在这里只演示其中一部分,读者们可自行百度“JS 标准内置对象”获取更全的。
JS 中的常见的全局函数有 eval、parseInt、encodeURIComponent。
JS 中常见的标准内置对象有 0bject、Function、Boolean、Number、Math、Date、String、RegExp、Array 等。
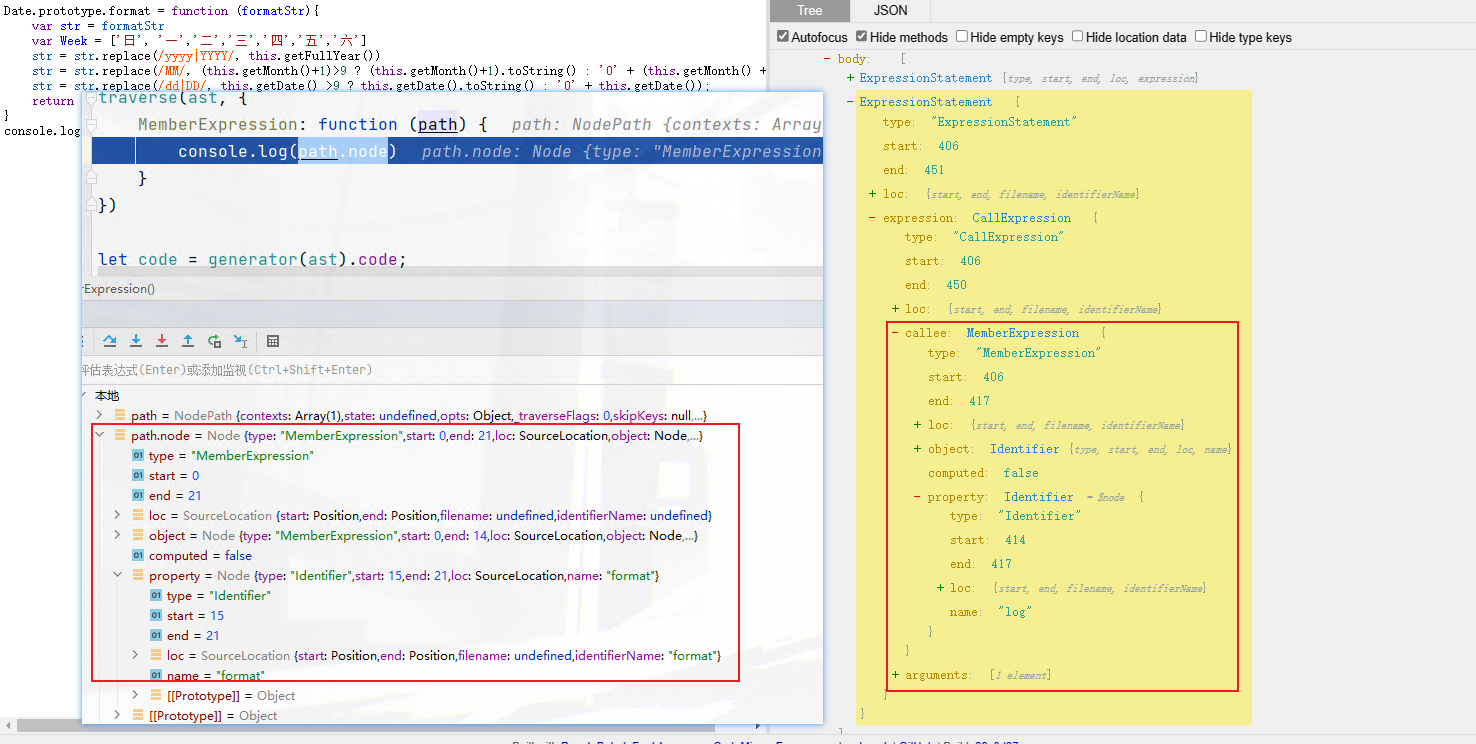
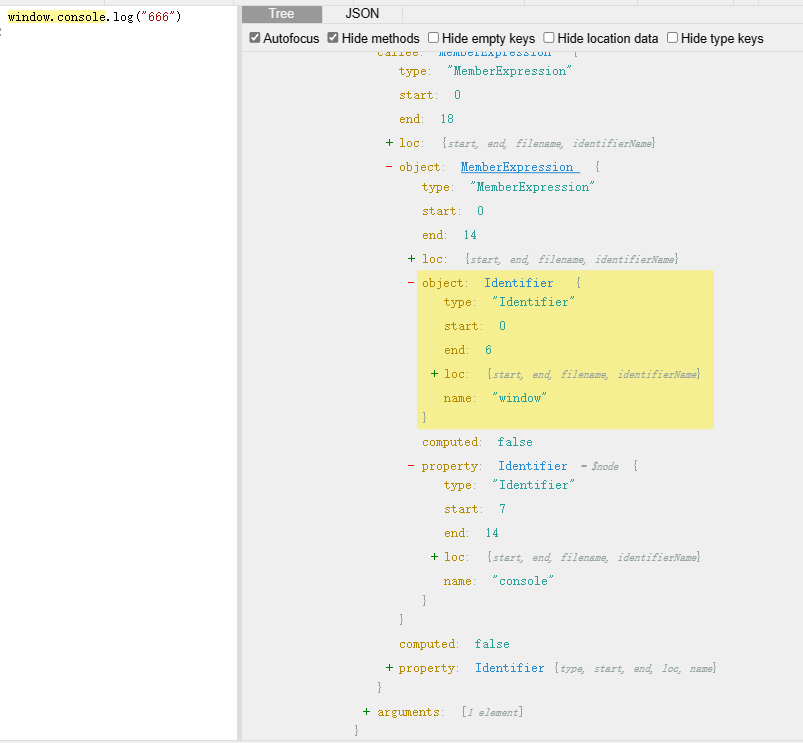
这些全局函数和内置对象在AST 中都是标识符,并且都是 window 对象下的。因此处理代码的思路就来了,遍历 Identifier 节点,把该节点替换成object 属性为 window 的MemberExpression 即可。
意思是,咱把这个成员表达式MemberExpression 再加一层,console.log变成了window.console.log,callee的左边,就是这个.的左侧的是object,右侧是property。如果把window.console看成一个整体,他们就作为一个MemberExpression在object里面。
也就是需要生成MemberExpression,它在 ts 文件中的定义为:
export function memberExpression(object: Expression, property: any, computed?:boolean, optional?: true | false | null): MemberExpression;传入 object、property、computed,返回 MemberExpression。内置对象的处理代码如下:
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
traverse(ast, {
Identifier(path){
let name = path.node.name;
if('console|eval|parseInt|encodeURIComponent|Object|Function|Boolean|Number|Math|Date|String|RegExp|Array'.indexOf(name) != -1){
path.replaceWith(t.memberExpression(t.identifier('window'), t.stringLiteral(name), true));
}
}
});
let code = generator(ast).code;
fs.writeFile('./demoNew.js', code, (err)=>{});上述代码中先获取到 Identifier 的 name 属性,然后到预先准备好的字符串中去搜索。如果是内置对象或全局函数,就把它替换成 object 属性为 window 的MemberExpression
效果如下:
window["Date"]["prototype"]["format"] = function (formatStr) {
var str = formatStr;
var Week = ['日', '一', '二', '三', '四', '五', '六'];
str = str["replace"](/yyyy|YYYY/, this["getFullYear"]());
str = str["replace"](/MM/, this["getMonth"]() + 1 > 9 ? (this["getMonth"]() + 1)["toString"]() : '0' + (this["getMonth"]() + 1));
str = str["replace"](/dd|DD/, this["getDate"]() > 9 ? this["getDate"]()["toString"]() : '0' + this["getDate"]());
return str;
};
window["console"]["log"](new window["Date"]()["format"]('yyyy-MM-dd'));二、常量与标识符的混淆
1.实现数值常量加密
异或运算的规律(互为异或关系):
A ^ B = C
C ^ A = B
C ^ B = A代码中的数值常量可以通过遍历 NumericLiteral 节点,获取其中的 value 属性来得到。
然后随机生成一个数值记为 key。接着把 value 与 key 进行异或得到加密后的数值记为cipherNum,即 cipherNum = value key。
此时,value = cipherNum^key。因此可以生成一个binaryExpression 节点来等价的替换 NumericLiteral 节点。
binaryExpression的operator 为,left为 cipherNum,right为 key。代码如下:
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
traverse(ast, {
NumericLiteral(path){
let value = path.node.value;
let key = parseInt(Math.random() * (999999 - 100000) + 100000, 10);
let cipherNum = value ^ key;
path.replaceWith(t.binaryExpression('^', t.numericLiteral(cipherNum), t.numericLiteral(key)));
//替换后的节点里也有numericLiteral节点,会造成死循环,因此需要加入path.skip()
path.skip();
}
});
let code = generator(ast).code;
fs.writeFile('./demoNew.js', code, (err)=>{});
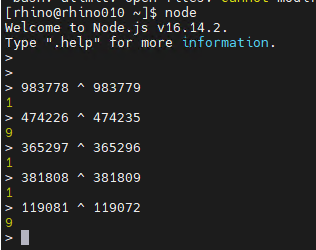
/*
Date.prototype.format = function (formatStr) {
var str = formatStr;
var Week = ['日', '一', '二', '三', '四', '五', '六'];
str = str.replace(/yyyy|YYYY/, this.getFullYear());
str = str.replace(/MM/, this.getMonth() + (983778 ^ 983779) > (474226 ^ 474235) ? (this.getMonth() + (365297 ^ 365296)).toString() : '0' + (this.getMonth() + (381808 ^ 381809)));
str = str.replace(/dd|DD/, this.getDate() > (119081 ^ 119072) ? this.getDate().toString() : '0' + this.getDate());
return str;
};
console.log(new Date().format('yyyy-MM-dd'));
*/
2.实现字符串常量加密
原始代码经过前几个小节的处理,可以看出很多标识符都变成了字符串。但是这些字符串依然是明文,还是一眼就能看明白。因此这一小节就要对这些字符串进行加密,加密的思路很简单。比如,代码中明文是"prototype",加密后的值为"cHJvdG90exBI",解密函数名为atob。那么只要构建一下atob("cHJvdG90eXB1"),然后用它普换原先的"prototype"甲可。
当然解密函数也需要一起放入原始代码中。笔者在这里就用 Base64编码一下字符串,然后使用浏览器自带的atob 来解密。
那么在AST中操作的话,就要先遍历所有的 StringLiteral,取出其中的value 属性进行加密,然后把Stringliteral节点替换为callExpression (函数调用表达式)。如何生成callExpression 昵?来看一下callExpression在ts 文件中的定义:
export function callExpression(callee: Expression | V8IntrinsicIdentifiex, _arguments: Array<Expression | SpreadElement | JSXNamespacedName | ArgumentPlaceholder>): CalIExpression;callee表示函数名,传入一个Identifier 即可。_arguments表示参数,参数可以有多个,因此它是一个数组。函数最终返回 CallExpression。实现字符串常量加密的代码如下:
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
function base64Encode(e) {
var r, a, c, h, o, t, base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
for (c = e.length, a = 0, r = ''; a < c;) {
if (h = 255 & e.charCodeAt(a++), a == c) {
r += base64EncodeChars.charAt(h >> 2),
r += base64EncodeChars.charAt((3 & h) << 4),
r += '==';
break
}
if (o = e.charCodeAt(a++), a == c) {
r += base64EncodeChars.charAt(h >> 2),
r += base64EncodeChars.charAt((3 & h) << 4 | (240 & o) >> 4),
r += base64EncodeChars.charAt((15 & o) << 2),
r += '=';
break
}
t = e.charCodeAt(a++),
r += base64EncodeChars.charAt(h >> 2),
r += base64EncodeChars.charAt((3 & h) << 4 | (240 & o) >> 4),
r += base64EncodeChars.charAt((15 & o) << 2 | (192 & t) >> 6),
r += base64EncodeChars.charAt(63 & t)
}
return r
}
traverse(ast, {
StringLiteral(path){
//生成callExpression参数就是字符串加密后的密文
let encStr = t.callExpression(
t.identifier('atob'),
[t.stringLiteral(base64Encode(path.node.value))]);
path.replaceWith(encStr);
//替换后的节点里也有StringLiteral节点,会造成死循环,因此需要加入path.skip()
path.skip();
}
});
let code = generator(ast).code;
fs.writeFile('./demoNew.js', code, (err)=>{});
/*
Date.prototype.format = function (formatStr) {
var str = formatStr;
var Week = [atob("5Q=="), atob("AA=="), atob("jA=="), atob("CQ=="), atob("2w=="), atob("lA=="), atob("bQ==")];
str = str.replace(/yyyy|YYYY/, this.getFullYear());
str = str.replace(/MM/, this.getMonth() + 1 > 9 ? (this.getMonth() + 1).toString() : atob("MA==") + (this.getMonth() + 1));
str = str.replace(/dd|DD/, this.getDate() > 9 ? this.getDate().toString() : atob("MA==") + this.getDate());
return str;
};
console.log(new Date().format(atob("eXl5eS1NTS1kZA==")));
*/3.实现数组混淆
来观察一下经过字符串加密以后的代码,可以看到字符串虽然加密了,但是字符串依然在原先的位置。数组混淆要做的事情,就是把这些字符串都提取到数组中,原先字符串的地方改为以数组下标的方式去访问数组成员。其实还可以提取到多个数组中,不同的数组处于不同的作用域中。笔者在这里就只实现一下提取到一个数组的情况。
举个例子,比如 Datelatob("cHJvdg90eXB1"),把"cHJvdG90eXB1"变成数组 arr 的下标为 0 的成员后,原先字符串的位置就变为,Date[atob(arr[0])],当然还需要额外生成一个数组,放入到被混淆的代码中。
那么AST 怎么来处理呢?首先肯定是遍历 StringLiteral 节点。既然这个也是遍历StringLiteral节点,其实就可以和字符串加密一起处理了。先来构造出这么一个结构
atob(arr[0]),代码如下:
//CallExpression:函数调用表达式
let encstr = t.cal1Expression(
t.identifier('atob'),
[t.memberExpression(t.identifier('arr'),t.numericLiteral(index),
true)]);上述代码构建了一个 callExpression,函数名为atob,参数是 memberExpression。这个memberExpression 的 object 属性为 arr (就是待会要生成的数组名),property 属性为数组索引 index,这个值当前未知。
接着要把代码中的字符串放入数组中,然后得到对应的数组索引。这里有两种方案:
- 第一种是不管字符串有没有重复,遍历到一个就往数组里放,然后把新的索引赋值给上述代码中的 index。
- 第二种是字符串放入数组之前,先查询一下数组中有没有相同的,如果有相同的话,得到原先那个索引赋值给 index。笔者在这里采用第二种,代码如下:
function base64Encode(str) {
...
}
traverse(ast, {
// StringLiteral 遍历字符串常量节点["aa"]["bb"]
StringLiteral(path){
let cipherText = base64Encode(path.node.value);
//在JS 中,indexof 不只是可以用来搜索字符串,实际上它还可以用来搜索数组中某个成员是否存在,如果存在返回索引,如果不存在返 -1
let bigArrIndex = bigArr.indexOf(cipherText);
let index = bigArrIndex;
if(bigArrIndex == -1){
let length = bigArr.push(cipherText);
index = length -1;
}
let encStr = t.callExpression(
t.identifier('atob'),
[t.memberExpression(t.identifier('arr'),
t.numericLiteral(index), true)]);
path.replaceWith(encStr);
}
});在JS 中,indexof 不只是可以用来搜索字符串,实际上它还可以用来搜索数组中某个成员是否存在,如果存在返回索引,如果不存在返 -1
在上述代码中,path.node.value 就是明文字符串,先进行加密得到 cipherText,再去数组中搜索是否存在与 cipherText 一样的成员。如果已经存在于数组中,那就把原先的索引赋值给 index,然后构建函数调用表达式,替换当前的 StringLiteral 节点。
用于替换的节点中没有 StringLiteral 节点,不会死循环,所以不需要加入停止遍历的代码。
如果不存在于数组中,也就是index0f 返回的结果为 -1,就把 cipherText 加入到数组中。
数组的push 方法,可以同时加入多个成员,除了加入成员到数组末尾以外,还会返回加入成员以后的数组长度,因此length - 1就是数组最末成员的索引。
当前bigArr中的成员只是JS中的字符串,并不是AST中需要的StringLiteral节点。因此还需要做进一步处理,把bigArr中的成员都转成stringLiteral节点。
代码如下:
bigArr = bigArr.map(function(v){
return t.stringLiteral(v);
})现在把bigArr加入到ast中,也就是要先用types组件生成一个数组声明,并且数组成员与bigArr一致,然后加入到被混淆代码的最上面。实现代码如下:
bigArr = t.variableDeclarator(t.indentifier('arr'), t.arrayExpression(bigArr));
bigArr = t.variableDeclarator('var', [bigArr]);program节点相遇整个JS文件,它的body属性是一个数组,用unshift把bigArr加入到最前面。完整的数组混淆处理代码如下:
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
function base64Encode(e) {
var r, a, c, h, o, t, base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
for (c = e.length, a = 0, r = ''; a < c;) {
if (h = 255 & e.charCodeAt(a++), a == c) {
r += base64EncodeChars.charAt(h >> 2),
r += base64EncodeChars.charAt((3 & h) << 4),
r += '==';
break
}
if (o = e.charCodeAt(a++), a == c) {
r += base64EncodeChars.charAt(h >> 2),
r += base64EncodeChars.charAt((3 & h) << 4 | (240 & o) >> 4),
r += base64EncodeChars.charAt((15 & o) << 2),
r += '=';
break
}
t = e.charCodeAt(a++),
r += base64EncodeChars.charAt(h >> 2),
r += base64EncodeChars.charAt((3 & h) << 4 | (240 & o) >> 4),
r += base64EncodeChars.charAt((15 & o) << 2 | (192 & t) >> 6),
r += base64EncodeChars.charAt(63 & t)
}
return r
}
let bigArr = [];
traverse(ast, {
StringLiteral(path){
let cipherText = base64Encode(path.node.value);
let bigArrIndex = bigArr.indexOf(cipherText);
let index = bigArrIndex;
if(bigArrIndex == -1){
let length = bigArr.push(cipherText);
index = length -1;
}
let encStr = t.callExpression(
t.identifier('atob'),
[t.memberExpression(t.identifier('arr'),
t.numericLiteral(index), true)]);
path.replaceWith(encStr);
}
});
bigArr = bigArr.map(function(v){
return t.stringLiteral(v);
});
bigArr = t.variableDeclarator(t.identifier('arr'), t.arrayExpression(bigArr));
bigArr = t.variableDeclaration('var', [bigArr]);
ast.program.body.unshift(bigArr);
let code = generator(ast).code;
fs.writeFile('./demoNew.js', code, (err)=>{});
/*
var arr = ["5Q==", "AA==", "jA==", "CQ==", "2w==", "lA==", "bQ==", "MA==", "eXl5eS1NTS1kZA=="];
Date.prototype.format = function (formatStr) {
var str = formatStr;
var Week = [atob(arr[0]), atob(arr[1]), atob(arr[2]), atob(arr[3]), atob(arr[4]), atob(arr[5]), atob(arr[6])];
str = str.replace(/yyyy|YYYY/, this.getFullYear());
str = str.replace(/MM/, this.getMonth() + 1 > 9 ? (this.getMonth() + 1).toString() : atob(arr[7]) + (this.getMonth() + 1));
str = str.replace(/dd|DD/, this.getDate() > 9 ? this.getDate().toString() : atob(arr[7]) + this.getDate());
return str;
};
console.log(new Date().format(atob(arr[8])));
*/4.实现数组乱序
经过数组混淆以后的代码,引用处的数组索引与原先字符串还是一一对应的。这一小节就要打乱这个数组的顺序。代码很简单,传一个数组进去,并且指定循环次数,每次循环都把数组后面的成员放前面。代码如下:
(function (myArr, num){
var xiaojianbang = function (nums){
while(--nums){
myArr.unshift(myArr.pop());
}
};
xiaojianbang(++num);
}(bigArr, 0x10));既然数组的顺序和原先不一样了,那么被混淆的代码在执行之前,肯定还是要还原的。因此还需要一段还原数组顺序的代码。代码也很简单,反着来即可,循环同样的次数,把数组前面的成员放后面。代码如下:
(function (myArr, num) {
var xiaojianbang = function (nums) {
while (--nums) {
myArr.push(myArr.shift ());
}
};
xiaojianbang(++num);
})(arr, 0x10);还原顺序的代码肯定是要和被混淆的代码放一起的。如何放一起呢? 把还原数组顺序的代码保存到新文件 demoFront.js,读取该文件并解析成 astFront。由于还原数组顺序的代码最外层只有一个函数节点,所以取出其中的astFront.program.body[0]放入到被混淆代码中的body中。代码如下:
//构建数组声明语句
bigArr = t.variableDeclarator(t.identifier('arr'), t.arrayExpression(bigArr));
bigArr = t.variableDeclaration('var', [bigArr]);
//读取还原数组顺序的函数,并解析成astFront
const jscodeFront = fs.readFileSync("./demoFront.js", {
encoding: "utf-8"
});
let astFront = parser.parse(jscodeFront);
//先把还原数组顺序的代码,加入到被混淆代码的ast中
ast.program.body.unshift(astFront.program.body[0]);
//把数组放到被混淆代码的ast最前面
ast.program.body.unshift(bigArr);从上述代码中可以看出,数组混淆中生成的数组,需要放到还原数组顺序的代码前面。
全部代码如下:
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
function base64Encode(e) {
var r, a, c, h, o, t, base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
for (c = e.length, a = 0, r = ''; a < c;) {
if (h = 255 & e.charCodeAt(a++), a == c) {
r += base64EncodeChars.charAt(h >> 2),
r += base64EncodeChars.charAt((3 & h) << 4),
r += '==';
break
}
if (o = e.charCodeAt(a++), a == c) {
r += base64EncodeChars.charAt(h >> 2),
r += base64EncodeChars.charAt((3 & h) << 4 | (240 & o) >> 4),
r += base64EncodeChars.charAt((15 & o) << 2),
r += '=';
break
}
t = e.charCodeAt(a++),
r += base64EncodeChars.charAt(h >> 2),
r += base64EncodeChars.charAt((3 & h) << 4 | (240 & o) >> 4),
r += base64EncodeChars.charAt((15 & o) << 2 | (192 & t) >> 6),
r += base64EncodeChars.charAt(63 & t)
}
return r
}
let bigArr = [];
traverse(ast, {
StringLiteral(path){
let cipherText = base64Encode(path.node.value);
let bigArrIndex = bigArr.indexOf(cipherText);
let index = bigArrIndex;
if(bigArrIndex == -1){
let length = bigArr.push(cipherText);
index = length -1;
}
let encStr = t.callExpression(
t.identifier('atob'),
[t.memberExpression(t.identifier('arr'),
t.numericLiteral(index), true)]);
path.replaceWith(encStr);
}
});
bigArr = bigArr.map(function(v){
return t.stringLiteral(v);
});
//构建数组声明语句
bigArr = t.variableDeclarator(t.identifier('arr'), t.arrayExpression(bigArr));
bigArr = t.variableDeclaration('var', [bigArr]);
//读取还原数组顺序的函数,并解析成astFront
const jscodeFront = fs.readFileSync("./demoFront.js", {
encoding: "utf-8"
});
let astFront = parser.parse(jscodeFront);
//先把还原数组顺序的代码,加入到被混淆代码的ast中
ast.program.body.unshift(astFront.program.body[0]);
//把数组放到被混淆代码的ast最前面
ast.program.body.unshift(bigArr);
let code = generator(ast).code;
fs.writeFile('./demoNew.js', code, (err)=>{});
/*
var arr = ["5Q==", "AA==", "jA==", "CQ==", "2w==", "lA==", "bQ==", "MA==", "eXl5eS1NTS1kZA=="];
(function (myArr, num) {
var xiaojianbang = function (nums) {
while (--nums) {
myArr.push(myArr.shift());
}
};
xiaojianbang(++num);
})(arr, 0x10);
Date.prototype.format = function (formatStr) {
var str = formatStr;
var Week = [atob(arr[0]), atob(arr[1]), atob(arr[2]), atob(arr[3]), atob(arr[4]), atob(arr[5]), atob(arr[6])];
str = str.replace(/yyyy|YYYY/, this.getFullYear());
str = str.replace(/MM/, this.getMonth() + 1 > 9 ? (this.getMonth() + 1).toString() : atob(arr[7]) + (this.getMonth() + 1));
str = str.replace(/dd|DD/, this.getDate() > 9 ? this.getDate().toString() : atob(arr[7]) + this.getDate());
return str;
};
console.log(new Date().format(atob(arr[8])));
*/5.实现十六进制字符串
实现数组顺序还原的代码是没有经过混淆的,代码中标识符的混淆,可以在最后一起处理。
其中像 push、shift 这些方法可以转为字符串,由于这些代码处于还原数组顺序的代码中,因此没法把它们提取到大数组中。笔者在这里就简单地把它们编码成十六进制字符串。
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
const jscode = fs.readFileSync("./demoFront.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
function hexEnc(code) {
for (var hexStr = [], i = 0, s; i < code.length; i++) {
s = code.charCodeAt(i).toString(16);
hexStr += "\\x" + s;
}
return hexStr
}
traverse(ast,{
MemberExpression(path){
if(t.isIdentifier(path.node.property)){
let name = path.node.property.name;
path.node.property = t.stringLiteral(hexEnc(name));
}
path.node.computed = true;
}
});
let code = generator(ast).code;
console.log(code);
/*
(function (myArr, num) {
var xiaojianbang = function (nums) {
while (--nums) {
myArr["\\x70\\x75\\x73\\x68"](myArr["\\x73\\x68\\x69\\x66\\x74"]());
}
};
xiaojianbang(++num);
})(arr, 0x10);
*/上述代码遍历 MemberExpression 节点,将property的值进行 hex 编码,然后用stringLiteral节点替换 property,并把 computed 改为 true 最后输出的结果有两个转义字符,其实是 Babel 在处理的节点的时候,自动转义了反斜杠。在最后转成代码以后,把它们替换掉即可
let code = generator(ast).code;
code = code.replace(/\\\\x/g, '\\x');
console.log(code);另外,unicode字符申的实现方式与本小节一致,把hex编码的函数换成unicode 编码的函数即可。
6.实现标识符混淆
程序员在开发的时候,标识符一般都是有语义的,根据标识符名就可以猜测出代码在做什么,因此标识符混淆很有必要。
有一个很简单的标识符混淆方案,遍历binding.scope.block,找到相关表达式的值进行替换。
这个方案的缺点是整个文件中不同标识符的名称都是不一样的。但实际上可以让各个函数之间的局部标识符名相同,函数内的局部标识符名还可以与没有引用到的全局标识符名相同。这样做更具迷惑性。这一小节就来实现一下这种方案。
要实现这种方案,需要用到一个方法 scope.getOwnBinding。该方法可以用来获取属于当前节点的自己的绑定。
比如,在 Program 节点下,使用 getOwnBinding 就可以获取到全局标识符名,而函数内局部标识符名不会破获取到。
那么要获取到局部标识符名,可以遍历函数节点,在FunctionExpression与FunctionDeclaration 节点下,使用gotOwmBinding会获取到函数自身定义的局部标识符名,而不会获取到全局标识符名。
遍历三种节点,执行同一个重命名方法,代码如下:
traverse(ast, {
'Program|FunctionExpression|FunctionDeclaration'(path) {
renameOwnBinding(path);
}
});那么renameOwnBinding函数如何实现呢?来看下面这段代码:
function renameOwnBinding(path) {
let OwnBindingObj = {}, globalBindingObj = {}, i = 0;
path.traverse({
Identifier(p) {
let name = p.node.name;
let binding = p.scope.getOwnBinding(name);
binding ? (OwnBindingObj[name] = binding) : (globalBindingObj[name] = 1);
}
});
}上述代码先遍历当前节点中所有的 Identifier,得到Identifier 的 name 属性,通过getOwnBinding判断是否当前节点自己的绑定。
如果 binding 为undefined,则装示是其父级函数的标识符或者全局的标识符,就将该标识符名作为属性名,放入到 globalBindingObj对象中。
如果 binding 存在,则表示是当前节点自己的绑定,就将该标识符作为属性名,binding 作为属性值,放入到 OwnBindingObj 对象中。
这里有四点需要注意一下:
- globalBindingObj 中存放的不是所有的全局标识符,而是当前节点引用到的全局标识符。因为重命名标识符的时候,不能与引用到的全局标识符重名,需要进行判断。至于没有引用到的全局标识符名,就是要重名才更具迷惑性,反正最后使用的还是当前节点定义的局部标识符。
- OwnBindingObj中存储对应标识符的 binding。因为重命名标识符的时候,需要使用 binding.scope.rename 方法。
- 把标识符名作为对象的属性名。因为一个 Identifier 有多处引用就会遍历到多个,但实际上只需要调用一次 scope.rename 即可完成所有引用处的重命名。而对象属性名具有唯一性,就可以只保留最后一个同名标识符。
- 最好把 ast 先转成代码,再次进行解析后再进行标识符混淆。之前章节中介绍过修改AST 节点的时候,使用 Path 对象的方法的话,Babel 会更新 Path 信息。但是实际应用中并不能做到全部使用 Path 对象的方法。比如,用 types 组件生成新节点由于 types 组件生成的是节点,并不是 Path 对象,那么 binding 从何而来?
接下去肯定是要遍历 OwnBindingObj 对象中的属性,来进行重命名了,代码如下:
for(let oldName in OwnBindingObj) {
do {
var newName = '_0x2ba6ea' + i++;
} while(globalBindingObj[newName]);
OwnBindingObj[oldName].scope.rename(oldName, newName);
}上述代码中使用 do...while 循环来随机取一个标识符名,直到与当前节点引用到的全局标识符名不一样的时候,进行重命名。上述代码看似完美,但实际上 getOmnBinding 会取到当前函数中的子函数的参数名。虽然不影响最后结果,因为在当前函数中对子函数的参数进行重命名了,当遍历到子函数的时候,还会再次重命名。笔者在这里使用比较标识符作用域的方法来避免这种情况,完整的混淆标识符的代码如下:
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
function renameOwnBinding(path) {
let OwnBindingObj = {}, globalBindingObj = {}, i = 0;
path.traverse({
Identifier(p) {
let name = p.node.name;
let binding = p.scope.getOwnBinding(name);
binding && generator(binding.scope.block).code == path + '' ?
(OwnBindingObj[name] = binding) : (globalBindingObj[name] = 1);
}
});
for(let oldName in OwnBindingObj) {
do {
var newName = '_0x2ba6ea' + i++;
} while(globalBindingObj[newName]);
OwnBindingObj[oldName].scope.rename(oldName, newName);
}
}
traverse(ast, {
'Program|FunctionExpression|FunctionDeclaration'(path) {
renameOwnBinding(path);
}
});
let code = generator(ast).code;
fs.writeFile('./demoNew.js', code, (err)=>{});单独解释下binding && generator(binding.scope.block).code == path + '' ,这段代码中 binding.scope,block 表示 binding 的作用域,path + ''只表示把当前节点转代码。注意,这里path 指的是Program|FunctionExpression|FunctionDeclaration其中一个。子函数的参数作用域转代码后是子函数本身,肯定与当前节点转代码后不一致。
7. 标识符的随机生成
在刚刚的小节中,重命名标识符时使用固定的_0x2aea 加上一个自增的数字来作为新的标识符名。这一节将使用大写字母 O小写字母o和数字0这三个字符来组成标识符名,把var newName='_0x2ba6ea' + i++;这句代码改成var newName=generatorIdentifier(i++);,以下是 generatorIdentifier 的实现代码:
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
function generatorIdentifier(decNum){
let flag = ['O', 'o', '0'];
let retval = [];
while(decNum > 0){
retval.push(decNum % 3);
decNum = parseInt(decNum / 3);
}
let Identifier = retval.reverse().map(function(v){
return flag[v]
}).join('');
Identifier.length < 6 ? (Identifier = ('OOOOOO' + Identifier).substr(-6)):
Identifier[0] == '0' && (Identifier = 'O' + Identifier);
return Identifier;
}
function renameOwnBinding(path) {
let OwnBindingObj = {}, globalBindingObj = {}, i = 0;
path.traverse({
Identifier(p) {
let name = p.node.name;
let binding = p.scope.getOwnBinding(name);
binding && generator(binding.scope.block).code == path + '' ?
(OwnBindingObj[name] = binding) : (globalBindingObj[name] = 1);
}
});
for(let oldName in OwnBindingObj) {
do {
var newName = generatorIdentifier(i++);
} while(globalBindingObj[newName]);
OwnBindingObj[oldName].scope.rename(oldName, newName);
}
}
traverse(ast, {
'Program|FunctionExpression|FunctionDeclaration'(path) {
renameOwnBinding(path);
}
});
let code = generator(ast).code;
fs.writeFile('./demoNew.js', code, (err)=>{});
/*
Date.prototype.format = function (OOOOOO) {
var OOOOOo = OOOOOO;
var OOOOO0 = ['日', '一', '二', '三', '四', '五', '六'];
OOOOOo = OOOOOo.replace(/yyyy|YYYY/, this.getFullYear());
OOOOOo = OOOOOo.replace(/MM/, this.getMonth() + 1 > 9 ? (this.getMonth() + 1).toString() : '0' + (this.getMonth() + 1));
OOOOOo = OOOOOo.replace(/dd|DD/, this.getDate() > 9 ? this.getDate().toString() : '0' + this.getDate());
return OOOOOo;
};
console.log(new Date().format('yyyy-MM-dd'));
*/它本质上就是将十进制转为三进制,然后把 0、1、2 分别用大写字母O 、小写字母o、和数字0来换。
retval 数组中存的是余数,经过数组的 reverse 方法倒序后,就得到十进制为三进制的结果,只是这时里面的数字是 012。接着通过数组的 map 遍历数组成员012,分别替换成大写字母 O,小写字母o和数字 0。最后用数组的 join 把数组拼接成字符串。
为了使生成的标识符整齐,对于长度小于 6的标识符,可以用大写字母O 或者小写字母o补全位数;对于长度大于或等于 6并且第一个字符是数字0的标识符,则往前面补一个大字母O或者小写字母o(标识符不能以数字开头)。
三、代码块的混淆
1.二项式转函数花指令
花指令用来尽可能地隐藏原代码的真实意图,并且有多种实现方案。本节要介绍如何把二项式转为函数。
例如,把 c+d 转换为如下形式:
function xxx(a,b){
return a + b;
}
xxx(c,d);不止二项式,代码中的函数调用表达式也可以处理成类似的花指令,例如 c(d)可以转换成如下形式:
function xxx(a,b) {
return a(b);
}
xxx(c,d);在这里只实现二项式的情况。从 AST 的角度去考虑如何实现这个方案,分为以下四步:
- 遍历 BinaryExpression 节点,取出operator、left 和 right。
- 生成一个函数,函数名不能与当前节点中的标识符冲突,参数可以固定为a和b,返回语句中的运算符与 operator 一致。
- 找到最近的 BlockStatement 节点,将生成的函数加入到 body 数组中的最前面。
- 把原先的 BinaryExpression 节点替换为 CallExpression,callee 是函数名,_arguments 是一项式的 let 和right。
上述实现方案中,标识符名可以随机设置,因为最后进行标识符混淆时,会处理成相似的名字。花指令的目的是增加代码量,隐藏代码的真实意图。因此每遍历到一个 operator,都可以生成不同名字的函数,不需要去判断是哪种operator,因为并不是一种operator生成一个函数。实现的代码如下:
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
traverse(ast, {
BinaryExpression(path){
let operator = path.node.operator;
let left = path.node.left;
let right = path.node.right;
let a = t.identifier('a');
let b = t.identifier('b');
let funcNameIdentifier = path.scope.generateUidIdentifier('xxx');
let func = t.functionDeclaration(
funcNameIdentifier,
[a, b],
t.blockStatement([t.returnStatement(
t.binaryExpression(operator, a, b)
)]));
let BlockStatement = path.findParent(
function(p){return p.isBlockStatement()});
BlockStatement.node.body.unshift(func);
path.replaceWith(t.callExpression(funcNameIdentifier, [left, right]));
}
});
let code = generator(ast).code;
fs.writeFile('./demoNew.js', code, (err)=>{});
/*
Date.prototype.format = function (formatStr) {
function _xxx7(a, b) {
return a + b;
}
function _xxx6(a, b) {
return a > b;
}
function _xxx5(a, b) {
return a + b;
}
function _xxx4(a, b) {
return a + b;
}
function _xxx3(a, b) {
return a + b;
}
function _xxx2(a, b) {
return a + b;
}
function _xxx(a, b) {
return a > b;
}
var str = formatStr;
var Week = ['日', '一', '二', '三', '四', '五', '六'];
str = str.replace(/yyyy|YYYY/, this.getFullYear());
str = str.replace(/MM/, _xxx(_xxx2(this.getMonth(), 1), 9) ? _xxx3(this.getMonth(), 1).toString() : _xxx4('0', _xxx5(this.getMonth(), 1)));
str = str.replace(/dd|DD/, _xxx6(this.getDate(), 9) ? this.getDate().toString() : _xxx7('0', this.getDate()));
return str;
};
console.log(new Date().format('yyyy-MM-dd'));
*/2.代码的逐行加密
这种方案的原理跟字符串加密是一样的,不过需要先把代码转化为字符串,再把字符申加密后的密文传入解密函数、解密出明文,然后通过 eval 执行代码。实现代码如下:
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
function base64Encode(e) {
var r, a, c, h, o, t, base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
for (c = e.length, a = 0, r = ''; a < c;) {
if (h = 255 & e.charCodeAt(a++), a == c) {
r += base64EncodeChars.charAt(h >> 2),
r += base64EncodeChars.charAt((3 & h) << 4),
r += '==';
break
}
if (o = e.charCodeAt(a++), a == c) {
r += base64EncodeChars.charAt(h >> 2),
r += base64EncodeChars.charAt((3 & h) << 4 | (240 & o) >> 4),
r += base64EncodeChars.charAt((15 & o) << 2),
r += '=';
break
}
t = e.charCodeAt(a++),
r += base64EncodeChars.charAt(h >> 2),
r += base64EncodeChars.charAt((3 & h) << 4 | (240 & o) >> 4),
r += base64EncodeChars.charAt((15 & o) << 2 | (192 & t) >> 6),
r += base64EncodeChars.charAt(63 & t)
}
return r
}
traverse(ast, {
FunctionExpression(path){
let blockStatement = path.node.body;
let Statements = blockStatement.body.map(function(v){
if(t.isReturnStatement(v)) return v;
let code = generator(v).code;
let cipherText = base64Encode(code);
let decryptFunc = t.callExpression(t.identifier('atob'), [t.stringLiteral(cipherText)]);
return t.expressionStatement(t.callExpression(t.identifier('eval'), [decryptFunc]));
});
path.get('body').replaceWith(t.blockStatement(Statements));
}
});
let code = generator(ast).code;
fs.writeFile('./demoNew.js', code, (err)=>{});
/*
Date.prototype.format = function (formatStr) {
eval(atob("dmFyIHN0ciA9IGZvcm1hdFN0cjs="));
eval(atob("dmFyIFdlZWsgPSBbJ+UnLCAnACcsICeMJywgJwknLCAn2ycsICeUJywgJ20nXTs="));
eval(atob("c3RyID0gc3RyLnJlcGxhY2UoL3l5eXl8WVlZWS8sIHRoaXMuZ2V0RnVsbFllYXIoKSk7"));
eval(atob("c3RyID0gc3RyLnJlcGxhY2UoL01NLywgdGhpcy5nZXRNb250aCgpICsgMSA+IDkgPyAodGhpcy5nZXRNb250aCgpICsgMSkudG9TdHJpbmcoKSA6ICcwJyArICh0aGlzLmdldE1vbnRoKCkgKyAxKSk7"));
eval(atob("c3RyID0gc3RyLnJlcGxhY2UoL2RkfERELywgdGhpcy5nZXREYXRlKCkgPiA5ID8gdGhpcy5nZXREYXRlKCkudG9TdHJpbmcoKSA6ICcwJyArIHRoaXMuZ2V0RGF0ZSgpKTs="));
return str;
};
console.log(new Date().format('yyyy-MM-dd'));
*/这段代码处理步骤如下:
-
遍历 FunctionExpression 节点。其中path,node.body 即 BlockStatement 节点。
blockStatement.body 是一个数组,里面是函数的代码行,它的每一个成员分别对应函数的每一行语句,然后使用数组的 map 方法对每一行语句分别处理。
-
如果是返回语句,就不做处理,直接返回原语句。单行加密时不能加密返回语句;整个函数加密时,函数中可以有返回语句。
-
使用 let code = generator(v).code; 将语转变成字符串。
-
使用 let cipherText = base64Encode(code);对字符串进行加密。
-
构建 atob('xxxx')形式的代码,atob 是解密函数名。解密函数如果不是系统自带的,还需要把解密函数一起放入代码中。需要生成 CallExpression,callee 为解密函数名,参数为加密后的字符串常量,赋值给 decryptFunc。
-
构建 eval(atob('xxxx'))形式的代码,需要生成 CallExpression,callee为 eval,参数为上一步生成的 decryptFunc,最后用expressionStatement 包裹。
-
当函数中所有语句处理完后,构建新的 BlockStatement 替换原有的即可。
代码逐行加密的方案不建议大规模应用,会导致标志太明显。可以只隐藏其中几句代码或某些变量的关键赋值位置。自动化处理过程中无法知道一段代码是否为关键代码,除非用户在代码中加人标记,表示要隐藏哪几句代码。这个标记可以是注释,例如,可以在原始代码中某一句代码后面加入注释 Base64Encrypt。解析以下节点,查看发生的变化:
str = str.replace(/yyyy|YYYY/,this.getFullYear());//Base64Encrypt
Node{
type:'ExpressionStatement',
expression: Node{
type:'AssignmentExpression',
...
operator:'=',
left: Node{type: 'Identifier', ...name:'str'}
right: Node{type:'CallExpression',...}
},
trailingComments: [{
type:'CommentLine',
value:'Base64Encrypt',
...
}
]
}从上述结构中可以看出,生成了一个 trailingComments 节点,它是行尾注释。
因此只要在逐行解析代码时,添加判断语句,如果有注释且为 Base64Encrypt,就进行加密,
...
if(t.isReturnStatement(v)) return v;
if(!(v.trailingComments && v.trailingComments[0].value == 'Base64Encrypt')) return v;
delete v.trailingComments;
let code = generator(v).code;
...delete是JS 自带的,用来删除对象属性,加密之前把注释删掉。使用JS 自带的 delete而不是 path.remove,是因为v和 v. trailingComments 都是 Node 对象,不是 Path 对象。
如下所示:
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
traverse(ast, {
FunctionExpression(path){
let blockStatement = path.node.body;
let Statements = blockStatement.body.map(function(v){
if(t.isReturnStatement(v)) return v;
if(!(v.trailingComments && v.trailingComments[0].value == 'Base64Encrypt')) return v;
delete v.trailingComments;
let code = generator(v).code;
let cipherText = base64Encode(code);
let decryptFunc = t.callExpression(t.identifier('atob'), [t.stringLiteral(cipherText)]);
return t.expressionStatement(t.callExpression(t.identifier('eval'), [decryptFunc]));
});
path.get('body').replaceWith(t.blockStatement(Statements));
}
});
let code = generator(ast).code;
fs.writeFile('./demoNew.js', code, (err)=>{});3.代码的逐行ASCII码混淆
这种方案的原理与代码的逐行加密没有太大差别,只不过去掉了字符串加密函数,改用charCodeAt将字符串转到ASCII码,把解密函数换成 String.fromCharCode,最后使用eval函数来执行字符串代码。具体实现代码如下:
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
traverse(ast, {
FunctionExpression(path){
let blockStatement = path.node.body;
let Statements = blockStatement.body.map(function(v){
if(t.isReturnStatement(v)) return v;
if(!(v.trailingComments && v.trailingComments[0].value == 'ASCIIEncrypt')) return v;
delete v.trailingComments;
let code = generator(v).code;
let codeAscii = [].map.call(code, function(v){
return t.numericLiteral(v.charCodeAt(0));
});
let decryptFuncName = t.memberExpression(t.identifier('String'), t.identifier('fromCharCode'));
let decryptFunc = t.callExpression(decryptFuncName, codeAscii);
return t.expressionStatement(t.callExpression(t.identifier('eval'), [decryptFunc]));
});
path.get('body').replaceWith(t.blockStatement(Statements));
}
});
let code = generator(ast).code;
fs.writeFile('./demoNew.js', code, (err)=>{});
/*
Date.prototype.format = function (formatStr) {
var str = formatStr;
var Week = ['日', '一', '二', '三', '四', '五', '六'];
str = str.replace(/yyyy|YYYY/, this.getFullYear());
str = str.replace(/MM/, this.getMonth() + 1 > 9 ? (this.getMonth() + 1).toString() : '0' + (this.getMonth() + 1));
str = str.replace(/dd|DD/, this.getDate() > 9 ? this.getDate().toString() : '0' + this.getDate());
return str;
};
console.log(new Date().format('yyyy-MM-dd'));
*/字符串在JS 中也是数组,不过是只读的。但是它不能直接调用数组的 map,所以上述代码中用[].map.call来间接调用,作用是一样的。把字符串中的每个成员转成 ASCII码之后,用 NumericLiteral 节点来包裹,然后生成一个 MemberExpression 节点,String.fromCharCode作为解密函数名。
不管是代码逐行加密还是代码逐行 ASCII混淆,都要在标识符混淆之后。由此可见,
在做标识符混淆时,应该处理原始代码中的eval和 Function。
四、完整的代码处理后的效果
本章前三节介绍了多种混淆方案的实现方式。其中有些方案联合使用时,需要修改部分代码,本节介绍完整的代码以及完整处理后的效果。
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
//把混淆方案的相关实现方法封装成类
function ConfoundUtils(ast, encryptFunc){
this.ast = ast;
this.bigArr = [];
//接收传进来的函数,用于字符串加密
this.encryptFunc = encryptFunc;
}
//改变对象属性访问方式 console.log 改为 console["log"]
ConfoundUtils.prototype.changeAccessMode = function (){
traverse(this.ast, {
MemberExpression(path){
if(t.isIdentifier(path.node.property)){
let name = path.node.property.name;
path.node.property = t.stringLiteral(name);
}
path.node.computed = true;
},
});
}
//标准内置对象的处理
ConfoundUtils.prototype.changeBuiltinObjects = function (){
traverse(this.ast, {
Identifier(path){
let name = path.node.name;
if('eval|parseInt|encodeURIComponent|Object|Function|Boolean|Number|Math|Date|String|RegExp|Array'.indexOf(name) != -1){
path.replaceWith(t.memberExpression(t.identifier('window'), t.stringLiteral(name), true));
}
}
});
}
//数值常量加密
ConfoundUtils.prototype.numericEncrypt = function (){
traverse(this.ast, {
NumericLiteral(path){
let value = path.node.value;
let key = parseInt(Math.random() * (999999 - 100000) + 100000, 10);
let cipherNum = value ^ key;
path.replaceWith(t.binaryExpression('^', t.numericLiteral(cipherNum), t.numericLiteral(key)));
path.skip();
}
});
}
//字符串加密与数组混淆
ConfoundUtils.prototype.arrayConfound = function (){
let bigArr = [];
let encryptFunc = this.encryptFunc;
traverse(this.ast, {
StringLiteral(path){
let bigArrIndex = bigArr.indexOf(encryptFunc(path.node.value));
let index = bigArrIndex;
if(bigArrIndex == -1){
let length = bigArr.push(encryptFunc(path.node.value));
index = length -1;
}
let encStr = t.callExpression(
t.identifier('atob'),
[t.memberExpression(t.identifier('arr'), t.numericLiteral(index), true)]);
path.replaceWith(encStr);
}
});
bigArr = bigArr.map(function(v){
return t.stringLiteral(v);
});
this.bigArr = bigArr;
}
//数组乱序
ConfoundUtils.prototype.arrayShuffle = function (){
(function(myArr, num){
var xiaojianbang = function(nums){
while(--nums){
myArr.unshift(myArr.pop());
}
};
xiaojianbang(++num);
}(this.bigArr, 0x10));
}
//二项式转函数花指令
ConfoundUtils.prototype.binaryToFunc = function (){
traverse(this.ast, {
BinaryExpression(path){
let operator = path.node.operator;
let left = path.node.left;
let right = path.node.right;
let a = t.identifier('a');
let b = t.identifier('b');
let funcNameIdentifier = path.scope.generateUidIdentifier('xxx');
let func = t.functionDeclaration(
funcNameIdentifier,
[a, b],
t.blockStatement([t.returnStatement(
t.binaryExpression(operator, a, b)
)]));
let BlockStatement = path.findParent(
function(p){return p.isBlockStatement()});
BlockStatement.node.body.unshift(func);
path.replaceWith(t.callExpression(
funcNameIdentifier, [left, right]));
}
});
}
//十六进制字符串
ConfoundUtils.prototype.stringToHex = function (){
function hexEnc(code) {
for (var hexStr = [], i = 0, s; i < code.length; i++) {
s = code.charCodeAt(i).toString(16);
hexStr += "\\x" + s;
}
return hexStr
}
traverse(this.ast, {
MemberExpression(path){
if(t.isIdentifier(path.node.property)){
let name = path.node.property.name;
path.node.property = t.stringLiteral(hexEnc(name));
}
path.node.computed = true;
}
});
}
//标识符混淆
ConfoundUtils.prototype.renameIdentifier = function (){
//标识符混淆之前先转成代码再解析,才能确保新生成的一些节点也被解析到
let code = generator(this.ast).code;
let newAst = parser.parse(code);
//生成标识符
function generatorIdentifier(decNum){
let arr = ['O', 'o', '0'];
let retval = [];
while(decNum > 0){
retval.push(decNum % 3);
decNum = parseInt(decNum / 3);
}
let Identifier = retval.reverse().map(function(v){
return arr[v]
}).join('');
Identifier.length < 6 ? (Identifier = ('OOOOOO' + Identifier).substr(-6)):
Identifier[0] == '0' && (Identifier = 'O' + Identifier);
return Identifier;
}
function renameOwnBinding(path){
let OwnBindingObj = {}, globalBindingObj = {}, i = 0;
path.traverse({
Identifier(p){
let name = p.node.name;
let binding = p.scope.getOwnBinding(name);
binding && generator(binding.scope.block).code == path + '' ?
(OwnBindingObj[name] = binding) : (globalBindingObj[name] = 1);
}
});
for(let oldName in OwnBindingObj){
do{
var newName = generatorIdentifier(i++);
}while(globalBindingObj[newName]);
OwnBindingObj[oldName].scope.rename(oldName, newName);
}
}
traverse(newAst, {
'Program|FunctionExpression|FunctionDeclaration'(path) {
renameOwnBinding(path);
}
});
this.ast = newAst;
}
//指定代码行加密
ConfoundUtils.prototype.appointedCodeLineEncrypt = function (){
traverse(this.ast, {
FunctionExpression(path){
let blockStatement = path.node.body;
let Statements = blockStatement.body.map(function(v){
if(t.isReturnStatement(v)) return v;
if(!(v.trailingComments && v.trailingComments[0].value == 'Base64Encrypt')) return v;
delete v.trailingComments;
let code = generator(v).code;
let cipherText = base64Encode(code);
let decryptFunc = t.callExpression(t.identifier('atob'), [t.stringLiteral(cipherText)]);
return t.expressionStatement(
t.callExpression(t.identifier('eval'), [decryptFunc]));
});
path.get('body').replaceWith(t.blockStatement(Statements));
}
});
}
//指定代码行ASCII码混淆
ConfoundUtils.prototype.appointedCodeLineAscii = function (){
traverse(this.ast, {
FunctionExpression(path){
let blockStatement = path.node.body;
let Statements = blockStatement.body.map(function(v){
if(t.isReturnStatement(v)) return v;
if(!(v.trailingComments && v.trailingComments[0].value == 'ASCIIEncrypt')) return v;
delete v.trailingComments;
let code = generator(v).code;
let codeAscii = [].map.call(code, function(v){
return t.numericLiteral(v.charCodeAt(0));
})
let decryptFuncName = t.memberExpression(
t.identifier('String'), t.identifier('fromCharCode'));
let decryptFunc = t.callExpression(decryptFuncName, codeAscii);
return t.expressionStatement(
t.callExpression(t.identifier('eval'),[decryptFunc]));
});
path.get('body').replaceWith(t.blockStatement(Statements));
}
});
}
//构建数组声明语句,加入到ast最前面
ConfoundUtils.prototype.unshiftArrayDeclaration = function(){
this.bigArr = t.variableDeclarator(t.identifier('arr'), t.arrayExpression(this.bigArr));
this.bigArr = t.variableDeclaration('var', [this.bigArr]);
this.ast.program.body.unshift(this.bigArr);
}
//拼接两个ast的body部分
ConfoundUtils.prototype.astConcatUnshift = function(ast){
this.ast.program.body.unshift(ast);
}
ConfoundUtils.prototype.getAst = function(){
return this.ast;
}
//Base64编码
function base64Encode(e) {
var r, a, c, h, o, t, base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/';
for (c = e.length, a = 0, r = ''; a < c;) {
if (h = 255 & e.charCodeAt(a++), a == c) {
r += base64EncodeChars.charAt(h >> 2),
r += base64EncodeChars.charAt((3 & h) << 4),
r += '==';
break
}
if (o = e.charCodeAt(a++), a == c) {
r += base64EncodeChars.charAt(h >> 2),
r += base64EncodeChars.charAt((3 & h) << 4 | (240 & o) >> 4),
r += base64EncodeChars.charAt((15 & o) << 2),
r += '=';
break
}
t = e.charCodeAt(a++),
r += base64EncodeChars.charAt(h >> 2),
r += base64EncodeChars.charAt((3 & h) << 4 | (240 & o) >> 4),
r += base64EncodeChars.charAt((15 & o) << 2 | (192 & t) >> 6),
r += base64EncodeChars.charAt(63 & t)
}
return r
}
function main(){
//读取要混淆的代码
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
//读取还原数组乱序的代码
const jscodeFront = fs.readFileSync("./demoFront.js", {
encoding: "utf-8"
});
//把要混淆的代码解析成ast
let ast = parser.parse(jscode);
//把还原数组乱序的代码解析成astFront
let astFront = parser.parse(jscodeFront);
//初始化类,传递自定义的加密函数进去
let confoundAst = new ConfoundUtils(ast, base64Encode);
let confoundAstFront = new ConfoundUtils(astFront);
//改变对象属性访问方式
confoundAst.changeAccessMode();
//标准内置对象的处理
confoundAst.changeBuiltinObjects();
//二项式转函数花指令
confoundAst.binaryToFunc()
//字符串加密与数组混淆
confoundAst.arrayConfound();
//数组乱序
confoundAst.arrayShuffle();
//还原数组顺序代码,改变对象属性访问方式,对其中的字符串进行十六进制编码
confoundAstFront.stringToHex();
astFront = confoundAstFront.getAst();
//先把还原数组顺序的代码,加入到被混淆代码的ast中
confoundAst.astConcatUnshift(astFront.program.body[0]);
//再生成数组声明语句,并加入到被混淆代码的最开始处
confoundAst.unshiftArrayDeclaration();
//标识符重命名
confoundAst.renameIdentifier();
//指定代码行的混淆,需要放到标识符混淆之后
confoundAst.appointedCodeLineEncrypt();
confoundAst.appointedCodeLineAscii();
//数值常量混淆
confoundAst.numericEncrypt();
ast = confoundAst.getAst();
//ast转为代码
code = generator(ast).code;
//混淆的代码中,如果有十六进制字符串加密,ast转成代码以后会有多余的转义字符,需要替换掉
code = code.replace(/\\\\x/g, '\\x');
console.log(code);
}
main();对上述代码进行以下三点说明。
(1) demo.js 中存放的代码用来测试混淆方案,代码为原始代码。
(2) demoFront.js 中存放的代码用于还原数组顺序,2.4 节中。
(3) 如果不使用浏览器自带的 atob 作为解密函数,就需要实现对应的 Base64 解码函数,然后与还原数组顺序的代码一起加入。
用上述代码处理原始代码,输出结果为:
var OOOOOO = ["Zm9ybWF0", "5Q==", "AA==", "jA==", "CQ==", "2w==", "lA==", "bQ==", "cmVwbGFjZQ==", "Z2V0RnVsbFllYXI=", "Z2V0TW9udGg=", "dG9TdHJpbmc=", "MA==", "Z2V0RGF0ZQ==", "bG9n", "eXl5eS1NTS1kZA==", "RGF0ZQ==", "cHJvdG90eXBl"];
(function (OOOOOO, OOOOOo) {
var OOOOO0 = function (OOOOOo) {
while (--OOOOOo) {
OOOOOO["\x70\x75\x73\x68"](OOOOOO["\x73\x68\x69\x66\x74"]());
}
};
OOOOO0(++OOOOOo);
})(OOOOOO, 142584 ^ 142568);
window[atob(OOOOOO[640621 ^ 640621])][atob(OOOOOO[333872 ^ 333873])][atob(OOOOOO[534827 ^ 534825])] = function (OOOOOo) {
function OOOoOo(OOOOOO, OOOOOo) {
return OOOOOO + OOOOOo;
}
function OOOoOO(OOOOOO, OOOOOo) {
return OOOOOO > OOOOOo;
}
function OOOO00(OOOOOO, OOOOOo) {
return OOOOOO + OOOOOo;
}
function OOOO0o(OOOOOO, OOOOOo) {
return OOOOOO + OOOOOo;
}
function OOOO0O(OOOOOO, OOOOOo) {
return OOOOOO + OOOOOo;
}
function OOOOo0(OOOOOO, OOOOOo) {
return OOOOOO + OOOOOo;
}
function OOOOoo(OOOOOO, OOOOOo) {
return OOOOOO > OOOOOo;
}
var OOOOO0 = OOOOOo;
var OOOOoO = [atob(OOOOOO[889992 ^ 889995]), atob(OOOOOO[199115 ^ 199119]), atob(OOOOOO[393974 ^ 393971]), atob(OOOOOO[915745 ^ 915751]), atob(OOOOOO[302842 ^ 302845]), atob(OOOOOO[560371 ^ 560379]), atob(OOOOOO[624550 ^ 624559])];
OOOOO0 = OOOOO0[atob(OOOOOO[449616 ^ 449626])](/yyyy|YYYY/, this[atob(OOOOOO[445092 ^ 445103])]());
OOOOO0 = OOOOO0[atob(OOOOOO[314857 ^ 314851])](/MM/, OOOOoo(OOOOo0(this[atob(OOOOOO[568473 ^ 568469])](), 666066 ^ 666067), 271298 ^ 271307) ? OOOO0O
(this[atob(OOOOOO[251391 ^ 251379])](), 425338 ^ 425339)[atob(OOOOOO[357360 ^ 357373])]() : OOOO0o(atob(OOOOOO[391630 ^ 391616]), OOOO00(this[atob(OOOOOO[391880 ^ 391876])](), 812408 ^ 812409)));
OOOOO0 = OOOOO0[atob(OOOOOO[666436 ^ 666446])](/dd|DD/, OOOoOO(this[atob(OOOOOO[189039 ^ 189024])](), 863695 ^ 863686) ? this[atob(OOOOOO[777680 ^ 777695])]()[atob(OOOOOO[542837 ^ 542840])]() : OOOoOo(atob(OOOOOO[250977 ^ 250991]), this[atob(OOOOOO[785111 ^ 785112])]()));
return OOOOO0;
};
console[atob(OOOOOO[348315 ^ 348299])](new window[atob(OOOOOO[247633 ^ 247633])]()[atob(OOOOOO[400280 ^ 400282])](atob(OOOOOO[406239 ^ 406222])));他妈的效果确实炸裂,亲妈不认。
五、代码执行逻辑的混淆
1.实现流程平坦化
把以下代码放到AST Explorer 网站中解析,对照网站来实现相应的流程平坦化,如下所示:
Date.prototype.format = function (formatStr){
let array="0|1|4|5|3|2".split("|"),
index =0;
while(!![]){
switch ( + _array[_index++]){
case 0:
var str = formatStr;
continue;
case 1:
var Week = ['日','一', '二','三','四','五','六'];
continue;
case 2:
return str;
continue;
case 3:
str = str.replace(/dd|DD/,this.getDate() > 9 ? this.getDate().toString():'0' + this.getDate());
continue;
case 4:
str = str.replace(/yyyy|YYYY/, this.getFullYear());
continue;
case 5:
str = str.replace(/MM/, this.getMonth() + 1 > 9 ? (this.getMonth() + 1).toString() : '0' + (this.getMonth() + 1));
continue;
}
break;
}
};
console.log(new Date().format( 'yyyy -MM- dd'));因为采用的是一行语句对应一条 case 的方案,所以需要先获取每一行语句,处理方法与之前介绍的代码逐行混淆一致。遍历 FunctionExpression 节点,获取 path.node.body即BlockStatement。该节点的 body 属性是一个数组,通过 map 遍历数组,即可操作其中的每一行语句。代码如下:
traverse(ast,{
FunctionExpression(path) {
let blockStatement = path.node.body;
let Statements = blockStatement.body.map(function (v, i) {
return {index: i, value: v}
});
}});在流程平坦化的混淆中,要打乱原先的语句顺序,但是在执行时又要按原先的顺序执行,因此在打乱语句顺序之前,要对原先的语句顺序做映射。
从上述代码中可以看出,采用{index:i,value:v}这种方式来做映射。
index 是语句在 blockStatement.body 中的索引也就是原先的顺序。value 是语句本身。有了对应的关系后,就可以方便地建立分发器,来控制代码在执行时跳转到正确的 case 语句块。
接着要打乱语句顺序,算法很简单,遍历数组每一个成员,每一次循环随机取出一个索引为j的成员,与索引为i的成员进行交换。代码如下:
//打乱语句顺序
let i = Statements.ength;
while(i){
let j = Math.floor(Math.random() * i--);
[Statements[j],Statements[i]] = [Statements[i], Statements[j]];
}接着构建 case 语句块,在 AST 中它的类型为 SwitchCase。
下面介绍 SwitchCase 的结构:
{
type:'SwitchCase',
test:{ type: 'NumericLiteral', value: 5},
consequent:[
Node { ...},
{type: 'ContinueStatement',label: null}
]
}test 是 case 后的值,consequent 是一个数组,存放 case 语块中具体的语句,所以 case语句块的生成很容易。遍历打乱顺序后的语句数组 Statements。SwitchCase 中的 test 用从0开始递增的 NumericLiteral, consequent 存放两条语句,一条是原始代码中的语句,另一条是 continue 语句。最后把包装好的 SwitchCase 放入 cases 数组中。实现代码如下:
let cases = [];
Statements.map(function(v,i){
let switchCase = t.switchCase(t.numericLiteral(i), [v.value, t.continueStatement()]);
cases.push(switchCase);
]);为了控制 switch 每一次都跳转到正确的 case 语句块上,需要构建分发器。分发器中的"0|1|4|5|3|2"来源于之前做的映射。调整上面用来生成 case 语句块的代码,改为如下形式:
let dispenserArr = [];
let cases =[];
Statements.map(function(v, i){
dispenserArr[v.index] = i;
let switchCase = t.switchCase(t.numericLiteral(i), [v.value, t.continueStatement()]);
cases.push(switchCase);
});
let dispenserStr = dispenserArr.join('|');这段代码又定义了一个数组 dispenserArr,并且该数组在最后使用 join,以“|”作为连接符连接数组所有成员。可以看出,dispenserStr 就是分发器中的"0|1|4|5|3|2",而014532 是代码执行的真实顺序,因此 dispenserArr 中的成员应当是 case 后面的值。假设case 后面的值是 5,即i为5,再取出当前语句的真实索引 v.index,假设它是 3,也就是原始代码中该语句是第4行语句(数组从0开始)。那么就把 dispenserArr 中索引为3的成员改为5。对应上述代码中的 dispenserArr[v.index]=i,即可生成分发器中的字符串。
核心部分已经介绍完毕,接下来用 types 组件生成节点。完整的代码如下:
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
traverse(ast, {
FunctionExpression(path){
let blockStatement = path.node.body;
//逐行提取语句,按原先的语句顺序建立索引,包装成对象
let Statements = blockStatement.body.map(function(v, i){
return {index: i, value: v};
});
//洗牌,打乱语句顺序
let i = Statements.length;
while(i){
let j = Math.floor(Math.random() * i--);
[Statements[j], Statements[i]] = [Statements[i], Statements[j]];
}
//构建分发器,创建switchCase数组
let dispenserArr = [];
let cases = [];
Statements.map(function(v, i){
dispenserArr[v.index] = i;
let switchCase = t.switchCase(t.numericLiteral(i), [v.value, t.continueStatement()]);
cases.push(switchCase);
});
let dispenserStr = dispenserArr.join('|');
//生成_array和_index标识符,利用BabelAPI保证不重名
let array = path.scope.generateUidIdentifier('array');
let index = path.scope.generateUidIdentifier('index');
//生成 '...'.split 这是一个成员表达式
let callee = t.memberExpression(t.stringLiteral(dispenserStr), t.identifier('split'));
//生成 split('|')
let arrayInit = t.callExpression(callee, [t.stringLiteral('|')]);
//_array和_index放入声明语句中,_index初始化为0
let varArray = t.variableDeclarator(array, arrayInit);
let varIndex = t.variableDeclarator(index, t.numericLiteral(0));
let dispenser = t.variableDeclaration('let',[varArray, varIndex]);
//生成switch中的表达式 +_array[_index++]
let updExp = t.updateExpression('++', index);
let memExp = t.memberExpression(array, updExp, true);
let discriminant = t.unaryExpression("+", memExp);
//构建整个switch语句
let switchSta = t.switchStatement(discriminant, cases);
//生成while循环中的条件 !![]
let unaExp = t.unaryExpression("!", t.arrayExpression());
unaExp = t.unaryExpression("!", unaExp);
//生成整个while循环
let whileSta = t.whileStatement(unaExp, t.blockStatement([switchSta, t.breakStatement()]));
//用分发器和while循环来构建blockStatement,替换原有节点
path.get('body').replaceWith(t.blockStatement([dispenser, whileSta]));
}
});
let code = generator(ast).code;
fs.writeFile('./demoNew.js', code, (err)=>{});
/*
Date.prototype.format = function (formatStr) {
let _array = "0|3|5|1|4|2".split("|"),
_index = 0;
while (!![]) {
switch (+_array[_index++]) {
case 0:
var str = formatStr;
continue;
case 1:
str = str.replace(/MM/, this.getMonth() + 1 > 9 ? (this.getMonth() + 1).toString() : '0' + (this.getMonth() + 1));
continue;
case 2:
return str;
continue;
case 3:
var Week = ['日', '一', '二', '三', '四', '五', '六'];
continue;
case 4:
str = str.replace(/dd|DD/, this.getDate() > 9 ? this.getDate().toString() : '0' + this.getDate());
continue;
case 5:
str = str.replace(/yyyy|YYYY/, this.getFullYear());
continue;
}
break;
}
};
console.log(new Date().format('yyyy-MM-dd'));
*/对上述代码做以下 3 点说明:
(1) 为了便于理解,代码没有使用其他混淆方案。但在实际使用中,该混淆方案必须和之前介绍的其他混淆方案配合使用,才能加强混淆效果。例如,case 后面跟的值可以用数值常量加密(在JS 中 case 后面可以跟一个表达式,而不仅是数值或字符),分发器中的字符串可以用字符串加密,然后一起提取到大数组中。对于原始代码部分,可以进行生成花指令逐行加密等各种操作。
(2) switch中的表达式为+_array[_index++],最前面的加号代表强转成数值类型,因为分发器中它是字符串类型。虽然JS 是一门弱类型的语言,解释器会在适当的时机完成类型的自动转换,但是在 case 中,全等(===)的匹配不会自动转换类型。
(3)由于语句顺序被打乱,因此生成的语句顺序每一次都是不同的。在测试时,并不一定与上述顺序相同。
2.实现逗号表达式混淆
逗号表达式混淆的核心,是用逗号连接多个表达式。但是有一些语句在连接时,需要进行特别处理。
1.声明语句之间的连接
示例代码如下
vara=100;
var b = 200;
// vara=100,b=200;
// vara = 100,var b = 200;不能这样操作可以看出,如果要连接两个声明语句,需要取出 VariableDeclaration 中的 declarations数组,该数组里是声明语句中定义的变量,然后将它处理成一条声明语句。这里最方便的处理方式是把所有的标识符声明都提取到参数中。
2.普通语句与return 语句连接
示例代码如下:
function test(a){
a = a+100;
return a;
}
/*
function test(a){
return a = a +100,
a;
//a = a+100, return a;不能这样操作
}
*/可以看出,普通语句与return 语句连接时,需要提取出return语句的argument部分然后重新构建return 节点,把整个逗号表达式作为 argument 部分。接着介绍如何把函数中所有声明的变量提取到参数列表中,实现代码如下:
traverse(ast, {
FunctionExpression(path){
let blockStatement = path.node.body;
let blockStatementLength = blockStatement.body.length;
if(blockStatementLength < 2) return;
//把所有声明的变量提取到参数列表中
path.traverse({
VariableDeclaration(p){
declarations = p.node.declarations;
let statements = [];
declarations.map(function(v){
path.node.params.push(v.id);
v.init && statements.push(t.assignmentExpression('=',v.id,v.init));
});
p.replaceInline(statements);
}
});
}
});遍历FunctionExpression 节点,取出 blockStatement,body 节点,该节点里存放函数中所有的语句。如果语句少于两条,就不做任何处理。接着,遍历当前函数下所有的VariableDeclaration 节点,其中 declarations 数组为声明的具体变量。然后通过map 遍历整个数组,通过 path.node.params.push(v.id)将变量提取到函数的参数列表中。
要考虑两种情况:
- 变量没有初始化,那么它不加入到 statements 数组中,最后替换节点时相当于被移除;
- 变量初始化,那么就将 VariableDeclarator 改为赋值语句。
有时候会在函数体中的语句外面包裹一层 ExpressionStatement 节点,这会影响语句类型的判断。所以先把这类语句外层的 ExpressionStatement 节点去掉,代码如下:
let firstSta = blockStatement.body[0],i = 1;
while(i< blockStatementLength){
let tempSta = blockStatement.body[i++];
t.isExpressionStatement(tempSta) ? secondSta = tempSta.expression : secondSta = tempSta;
}首先取出函数体中的第一条语句,并且定义一个初始值为 1的计数器 i。接着对函数体中的其他语句进行循环,取出来的语句先赋值给 tempSta,然后判断是否为ExpressionStatement 节点。如果是,就取出expression 属性赋值给 secondSta,否则直接赋值给 secondSta。
然后要把这两个语句改为逗号表达式,可以使用toSequenceExpression 来完成。对于不同的语句,需要使用不同的处理方案。本节只处理其中的赋值语句和函数调用语句,返回语句也需要处理,如下所示:
//处理返回语句
if(t.isReturnStatement(secondSta)){
firstSta = t.returnStatement(
t.toSequenceExpression([firstSta,secondSta.argument]));
//处理赋值语句)
}else if(t.isAssignmentExpression(secondSta)){
secondSta.right = t.toSequenceExpression([firstSta, secondSta.right]);
firstSta = secondSta;
}else{
firstSta = t.toSequenceExpression([firstSta, secondSta]);
}首先介绍这段代码中的赋值语句的处理方法。判断语句如果是赋值表达式,就取出其中的right 节点,与 firstSta 组成逗号表达式后,再替换原有的 right 节点,最后把 secondSta赋值给 firstSta,进行后续的语句处理。接着介绍返回语句,取出其中的argument 节点,与firstSta组成逗号表达式后,重新生成一个returnStatement 节点。到这一步就可以跳出循环,因为后续即使再有语句,也不会被执行到。如果既不是返回语句,也不是赋值语句,那么就直接将 firstSta 与 secondSta 组成逗号表达式,这是一种最没有混淆力度的组成方式。
最后再处理函数调用表达式。在原始代码中,str.replace(...)可以处理成(firstSta,str.replace)(...)或者(firstSta,str.replace)(...),本节来实现第一种情况,如下所示:
if(t.isCallExpression(secondSta.right)){
let callee = secondSta.right.callee;
callee.object = t.toSequenceExpression([firstSta, callee.object]);
firstSta = secondSta;
}这段代码中,赋值语句的右边是函数调用表达式。取出函数名 callee,str.replace(...)的函数名为 str.replace。这是一个 MemberExpression 节点。接着取出 object 部分,即将str 与 firstSta 组成逗号表达式,再替换掉原先的 object 节点。
下面展示完整的处理代码:
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const t = require("@babel/types");
const generator = require("@babel/generator").default;
const fs = require('fs');
const jscode = fs.readFileSync("./demo.js", {
encoding: "utf-8"
});
let ast = parser.parse(jscode);
traverse(ast, {
FunctionExpression(path) {
let blockStatement = path.node.body;
let blockStatementLength = blockStatement.body.length;
if (blockStatementLength < 2) return;
//把所有声明的变量提取到参数列表中
path.traverse({
VariableDeclaration(p) {
declarations = p.node.declarations;
let statements = [];
declarations.map(function (v) {
path.node.params.push(v.id);
v.init && statements.push(t.assignmentExpression('=', v.id, v.init));
});
p.replaceInline(statements);
}
});
//处理赋值语句 返回语句 函数调用语句
let firstSta = blockStatement.body[0],
i = 1;
while (i < blockStatementLength) {
let tempSta = blockStatement.body[i++];
t.isExpressionStatement(tempSta) ?
secondSta = tempSta.expression : secondSta = tempSta;
//处理返回语句
if (t.isReturnStatement(secondSta)) {
firstSta = t.returnStatement(
t.toSequenceExpression([firstSta, secondSta.argument]));
//处理赋值语句
} else if (t.isAssignmentExpression(secondSta)) {
if (t.isCallExpression(secondSta.right)) {
let callee = secondSta.right.callee;
callee.object = t.toSequenceExpression([firstSta, callee.object]);
firstSta = secondSta;
} else {
secondSta.right = t.toSequenceExpression([firstSta, secondSta.right]);
firstSta = secondSta;
}
} else {
firstSta = t.toSequenceExpression([firstSta, secondSta]);
}
}
path.get('body').replaceWith(t.blockStatement([firstSta]));
}
});
let code = generator(ast).code;
fs.writeFile('./demoNew.js', code, (err) => {});
/*
Date.prototype.format = function (formatStr, str, Week) {
return str = (str = (str = (Week = (str = formatStr, ['日', '一', '二', '三', '四', '五', '六']), str).replace(/yyyy|YYYY/, this.getFullYear()), str).replace(/MM/, this.getMonth() + 1 > 9 ? (this.getMonth() + 1).toString() : '0' + (this.getMonth() + 1)), str).replace(/dd|DD/, this.getDate() > 9 ? this.getDate().toString() : '0' + this.getDate()), str;
};
console.log(new Date().format('yyyy-MM-dd'));
*/这段代码只适用于原始代码的案例,实际应用中,还需要考虑更多情况。可以看出,逗号表达式混淆的实现是比较复杂的,但是逗号表达式的还原很容易处理。后续章节会给出相应的还原方案。
六、小结
本章介绍了很多混淆的实现方案,这些方案之间需要配合使用才能达到更好的混淆效果。
但是在配合使用的过程中,有些方案需要注意顺序,如代码逐行加密,由于会把代码中的标识符一起加密,所以需要放在标识符混淆之后;有些方案不需要注意顺序,如数值常量混淆。
在代码执行逻辑的混淆中,流程平坦化的实现方案也有很多种,大体原理差不多。
此外,本章不少小节只写了FunctionExpression 的情况,FunctionDeclaration 的处理方法也是一样的。