
-
获取到base64字符串并删除头部信息,在这里就是data:font/opentype;base64, 逗号也要删除,这样就获取到了字体信息。 比如:T1RUTwAJAIAAAwAQQ0ZGIBcEq......过长不展示 。
-
访问http://www.motobit.com/util/base64-decoder-encoder.asp 这个网站,将纯字体信息字符串粘贴进编辑区域,然后下方解码选项选择解码base64字符串 和导出为二进制文件,即:
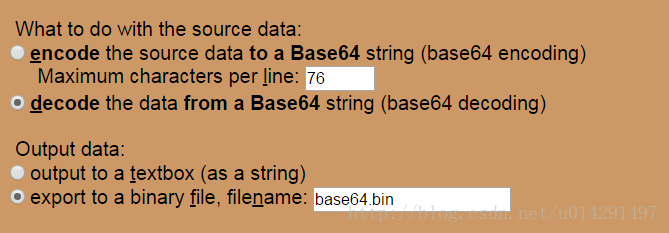
网站可解码base64并存储为二进制数据的 .bin 文件,将下载的二进制数据的 .bin 文件后缀更改为 .ttf
-
参考博客:
https://www.likecs.com/show-308355464.html
http://e.betheme.net/article/show-157263.html?action=onClick
# -*- coding: UTF-8 -*-
"""=========================================================
@Project -> File: aiqicSpider -> zhihu
@IDE: PyCharm
@author: lxc
@date: 2023/5/25 下午 4:04
@Desc:
1-功能描述:
2-实现步骤
1-
"""
import os
import datetime
from w3lib import html
import re
from lxml import etree
import requests
from utils.util import *
from fontTools.ttLib import TTFont
import xml.etree.ElementTree as ET
import logging
import base64
logger = logging.getLogger('log')
def get_new_string(string):
"""
解字体加密的流程
:param string:字体加密的内容
:return: 正确的内容
"""
filePath = 'source/zhihuxiaoshuo_decode.xml'
tree = ET.parse(filePath)
# 获取所有混淆字符(51个)
# GlyphOrder = [t.get('name') for t in tree.findall('./GlyphOrder/GlyphID')]
# 获取映射关系字典
version = tree.find('./cmap/tableVersion').get('version')
map_trees = tree.findall(f'./cmap/cmap_format_4[@platformID="{version}"]/map')
font_dict = {(r'\u' + map_tree.get('code')[2:]): (r'\u' + map_tree.get('name')[3:]) for map_tree in map_trees}
# 开始转换成正确的Unicode编码(仅转换含在51个混淆字符内的文字)
new_string = ''
for s in string:
unicode_s = zh_to_unicode(s)
new_unicode_s = font_dict.get(unicode_s, '') if font_dict.get(unicode_s, '') else unicode_s
new_string += new_unicode_s
new_string = unicode_to_zh(new_string)
return new_string
def base64_to_xml(base64str, filePath = 'source/zhihuxiaoshuo_decode.ttf'):
# 存储的ttf文件路径及名称
filePath = filePath
# 字体文件的base64
# 存储文件(以二进制方式)
# filePath :存储的文件路径及名称
# data :需要存储的数据
with open(filePath, 'wb') as f:
f.write(base64.b64decode(base64str))
font = TTFont(filePath)
font.saveXML(filePath.replace('.ttf', '.xml'))
def get_content_font(url=''):
headers = {
"Host": "www.zhihu.com",
"cache-control": "max-age=0",
"sec-ch-ua": "\"Not.A/Brand\";v=\"8\", \"Chromium\";v=\"114\", \"Microsoft Edge\";v=\"114\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.0.0",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"sec-fetch-site": "none",
"sec-fetch-mode": "navigate",
"sec-fetch-user": "?1",
"sec-fetch-dest": "document",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"x-forwarded-for": "4.2.2.2"
}
cookies = {
"_zap": "a83827de-3b91-4fcb-8cac-b05c0ce2c722",
"d_c0": "AWBYhnhPphaPTjRW3tDn7abGKTptvpsXWg4=|1681898026",
"YD00517437729195%3AWM_TID": "tlc%2B8RbWlU1AEVVAUBKEfswCf0D76f6G",
"YD00517437729195%3AWM_NI": "1a48fqyfOV1Qek9xh7T6V2KYMug3eGp7rlxL%2B5wSQWZ7NWDVzL7Jbx%2BE3Ot54j5HRGPLDmfMEFCfsl84CRZR7dlymKR7lcyBszRqRaMzx04uYRMAwmsSykSvix7DGFOrVlk%3D",
"YD00517437729195%3AWM_NIKE": "9ca17ae2e6ffcda170e2e6ee8ac2688ef1feccdc799cb48ea3d85b828a9facc53c8888a7b9c739a9bc99d8d62af0fea7c3b92af3bffcd9e57bbbba81b7b45ba7b5f799eb3d98ea9ad3ca538faba9d4e84db4e9be8dfb48e9ebb9b4d45d9ae982b8c75eba94f9abe174e99bfdb0f73ff8b6fba9d14d94948c8ee547879a8d87f268fcec8db3d95af5bca49af04192e9a484fc4ab1a69e92d16b8fa6b8d1b77f9b8e83a2f667b18db78cd27eaba8f9a5c64e8dae9a8dea37e2a3",
"__snaker__id": "iUG6Tku5N70vX1Vy",
"gdxidpyhxdE": "ndOZ%2BuniZlLfR3P74HSwhp9%2FtNw7eCBbuae3759jtbki87e9StUKEJR75RRNsGUGzp2bJVKHg132UKnp%2FzuKC%5Cb7v%5C718AqQDwm0PSa0tDayzE7K4kcjlnMlTpaE3woJkn4pS1%2BYAamHHQlYkjz%2F9fMkiBHkcCuj1%2FzS9pWgsqEB594m%3A1684985764828",
"captcha_session_v2": "2|1:0|10:1684984938|18:captcha_session_v2|88:WXhPY0hIQ2RVTEI4Qi91TTV0dGQ4a25GTU13L1R4ZHI5ZVc4Zkd5MFZieHhvTVVqdTY1QjA3cHlORDdGUW05MA==|15966ce0b32650122e3711c7951a753abff1705e19797653ae407991ad84cd1f",
"captcha_ticket_v2": "2|1:0|10:1684984948|17:captcha_ticket_v2|704:eyJ2YWxpZGF0ZSI6IkNOMzFfdnJlUXdUQUR0VUd6TkhpbnAtSGEtLkJlUDIxeFlTQjRxa2tzNV9HdWJlcEVneGhnanZEeVJIaF9GUmFEWm5QVlJxRFlrWEFVa0NKcUtyT3NIaGYxQk55U3NibS4uQXZzYlhXOHJYeTE2b0EuQzZwYlg2UC5IQ21yUXdMd3dPZnpDZE9jeTRHOTU5TFJUQWdVNkdHNmJpUWFrODZBQ2tFS1EyOVFlVmlyR2NfSDhZLmRINEdiUmljRHZzY2MuOHE5RlQxcnZoVjhoUER5WG0uVFc2QlQxLk5ERTlqRDBQSWRYbG8tUWJUTVZZRTFCOElaU0Z6VWluSFZNNW9mWWJHQjBzZ2VjWWxNVlJOUGROQzVNSzBmVWlwWEdaQVBpLnFHUnpQV0NRalB1MXZsWjlyWjd0b0NKOUd3eHBDNFp3cGxUNlNjVnJBV3ZZRGZJdl9vLjQ0TlVSODRwOENURDhvaTFrbnN0UXVaQW9ReV9SLlctVFQ2dm00V1ZqcWg3aWNsTXlmWVNaVTlWclQ3MHdBQ2tNaVdoQ0h0cWNfMUVTQUxkZXpxZS1tODV6S25zbVB3cWxjck1tYmJfQjFwTEZ2TXNDNXVmeDgta3ppY05XRWFIZUQyUWFKZTB1NXhRSGxYWVdPQ25nV29LcTAyVXdKX1ZNU2RHSk5mLjlwMyJ9|2177d12942c4eff4c1b0baa54e8134edbdf1813ae1b86c35e82cc9dc1b90ba72",
"q_c1": "8dd23ed357234c70bd90121c81245e15|1684985081000|1684985081000",
"tst": "r",
"z_c0": "2|1:0|10:1684985158|4:z_c0|92:Mi4xLWpYUVJnQUFBQUFCWUZpR2VFLW1GaVlBQUFCZ0FsVk4tU0pjWlFERUtuZHFSTUV1UlBaSWlmTVpJbDBSbWRqUjl3|ddb60321ede5e0f5d84736a7f387bd2c147421df927de42add63619add23dc2c",
"_xsrf": "IzgYPBKsxbRtg2EWChUJjfXmPoSDHCZG",
"Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49": "1684907499,1684984858,1684994068,1685005668",
"KLBRSID": "c450def82e5863a200934bb67541d696|1685033161|1685033150"
}
params = {
"is_share_data": "true",
"vp_share_title": "0"
}
response = requests.get(url, headers=headers, cookies=cookies, params=params)
tree = etree.HTML(response.text)
title = ''.join(tree.xpath('//*[@id="app"]/div/h1/text()'))
content_tree = tree.xpath("//div[@id='manuscript']")
doc = etree.tostring(content_tree[0])
html_content = html.remove_tags(doc)
content = html.replace_entities(html_content, keep=('£'))
base64_string = ''.join(re.findall('src: url\(data:font/ttf;charset=utf-8;base64,(.*?)\), url', response.text))
return title, content, base64_string
def zhxs_main(url=''):
# 获取正文和字体
try:
title, content, base64_string = get_content_font(url)
except Exception as e:
logger.exception(e)
logger.error("采集:获取正文和字体失败!!!\n 【%s】" % url)
return
# 存储字体文件
try:
base64_to_xml(base64_string)
except Exception as e:
logger.exception(e)
logger.error("存储字体文件失败!!!\n 【%s】" % url)
return
# 获取正确内容
try:
new_content = get_new_string(content)
except Exception as e:
logger.exception(e)
logger.error("获取正确内容失败!!!\n 【%s】" % url)
return
# 存储txt文件
try:
file_path = 'output/' + str(datetime.datetime.now())[:10]
if not os.path.exists(file_path):
os.mkdir(file_path)
file_name = file_path + '/' + title + '.txt'
with open(file_name, 'w', encoding='utf-8') as f:
f.write(new_content)
except Exception as e:
logger.exception(e)
logger.error("存储txt文件失败!!!\n 【%s】" % url)
return
return file_name
if __name__ == '__main__':
url = 'https://www.zhihu.com/market/paid_column/1575901064246743040/section/1578384160636489728'
zhxs_main(url)