
1.线程和进程
进程只是占内存
线程才消耗CPU
2.全局解释器锁GIL
GIL是解释器用于同步线程的一种机制
它使得任何时刻仅有一个线程在执行(就算你是多核处理器也一样)
使用GIL的解释器只允许同一时间执行一个线程
常见的使用GIL解释器有CPython、Ruby MRI
如果使用JPython就没有GIL锁
3.多线程测试CPU密集型
import time
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
#CPU 裸奔
def start():
"""单纯计算 消耗CPU资源 没有实际意义"""
data = 0
for _ in range(1000000):
data += 1
return
def single_task():
"""单线程运行"""
# 程序启动时间
time_data = time.time()
# 执行10次
for _ in range(10):
start()
# 打印程序消耗时间
single_consume_time = time.time() - time_data
print("单线程耗时:", single_consume_time)
return single_consume_time
def multithread_task():
"""多线程运行"""
# 程序启动时间
time_data = time.time()
with ThreadPoolExecutor(max_workers=10) as pool:
pool.map(start)
multithread_consume_time = time.time() - time_data
print("多线程耗时:", multithread_consume_time)
return multithread_consume_time
def multiprocess_task():
"""多线程运行"""
# 程序启动时间
time_data = time.time()
with ProcessPoolExecutor(max_workers=10) as pool:
pool.map(start)
multiprocess_consume_time = time.time() - time_data
print("多进程耗时:", multiprocess_consume_time)
return multiprocess_consume_time
if __name__ == "__main__":
single_consume_time = single_task()
multithread_consume_time = multithread_task()
multiprocess_consume_time = multiprocess_task()
print(single_consume_time > multithread_consume_time)
print(single_consume_time > multiprocess_consume_time)
print(multithread_consume_time > multiprocess_consume_time)运行结果:
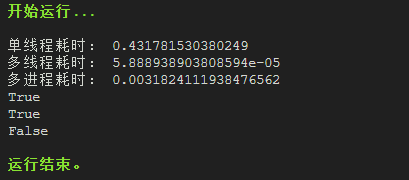
可见耗时排名:单线程耗时>多进程耗时>多线程耗时
视频作者不是线程池的写法,我们参考一下:
import time
import threading
#CPU 裸奔
def start():
"""单纯计算 消耗CPU资源 没有实际意义"""
data = 0
for _ in range(1000000):
data += 1
return
def single_task():
"""单线程运行"""
# 程序启动时间
time_data = time.time()
# 执行10次
for _ in range(10):
start()
# 打印程序消耗时间
single_consume_time = time.time() - time_data
print("单线程耗时:", single_consume_time)
return single_consume_time
def multithread_task():
"""多线程运行"""
# 程序启动时间
time_data = time.time()
ts = {}
for i in range(10):
t = threading.Thread(target=start)
t.start()
ts[i] = t
for i in range(10):
ts[i].join()
multithread_consume_time = time.time() - time_data
print("多线程耗时:", multithread_consume_time)
return multithread_consume_time
if __name__ == "__main__":
single_consume_time = single_task()
multithread_consume_time = multithread_task()运行结果是两者时间差不多,几次下来有时单线程耗时多,有时多线程耗时多:
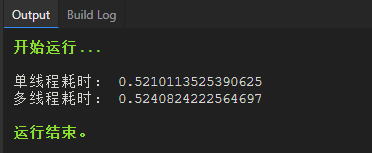
线程池的写法为啥这么快,普通多线程的写法为啥这么慢?
以及join()的作用?——堵塞线程
4.什么是堵塞线程
5.非守护与守护线程
6.普通锁与递归锁
7.线程\进程池
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
with ProcessPoolExecutor(max_workers=20) as pool:
res = pool.map(run, company_list)线程/进程池最大数量限制
经检测,多进程在windows端是有数量限制的,最大61个线程
with ProcessPoolExecutor(max_workers=500) as pool:
res = pool.map(run, company_list)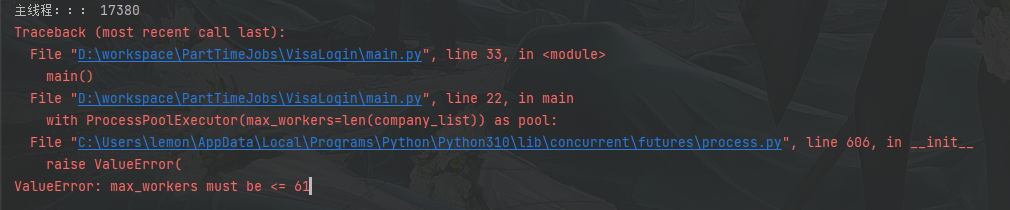
而在linux端则没有限制,以及在windows端的多进程也没有数量的限制
那么为了实现高并发的情况,并且不清楚任务数量的情况下,还是选择线程池比较理想,兼容性更好
至于上线,并不清楚,几万的并发是可以运行的,主要还是看主机的承受能力,我输入几亿的并发数量,Windows直接卡死了。。。
所以说,还是选择多进程比较方便。
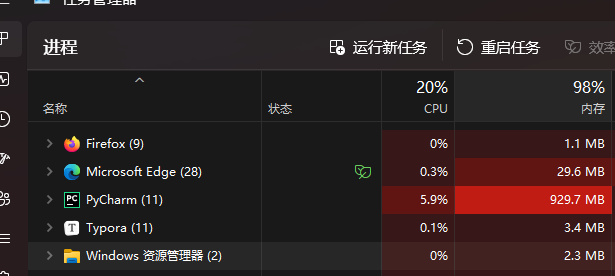
本人又拿公司的电脑测试了,我靠多线程居然又不是61个数量限制了,所以说,多线程还是看机器。
执行顺序
一般来说是随机的,